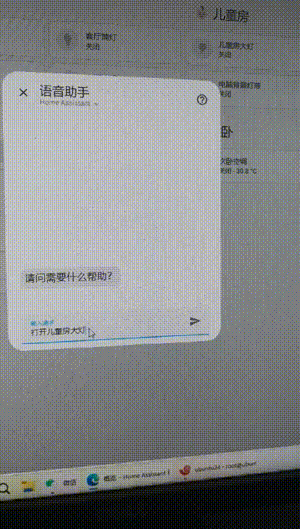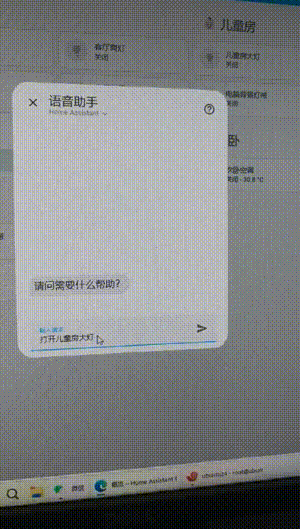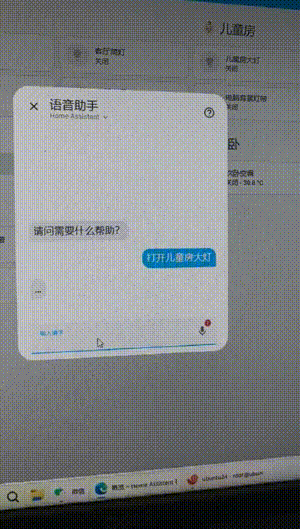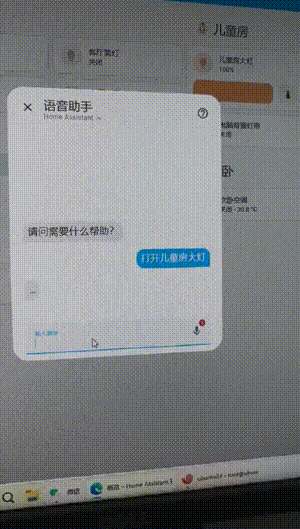
After trying it out and much research.
My conclusion is functionary was made to call function, so even a simple thing like what’s the temperature like? require a service call (sometimes it can work tho)
This fact aligns with the current state of HA intent development (you can check their block post). Which I agreed, you may not want to expose every state in the system prompt and want it to be able to execute everything (including things that you didn’t expose, for example unlock your front door.)
So, it seems like HA team is working on some sort of integration to add LLM.
Home-LLM also suffered a lot, he must re-write a lot of code to be compatible with the new way to execute intent. I’m not sure if it supports things like toggle fan swing, preset or similar.
So, the future is
function calling LLM
HA Intent (custom integration could also provide the intent)
System prompt will not provide the states by default
No I don’t think so, you can synchronize all your HA entities to your Google home. This lets you keep all functionalities of the speaker, but you’re bound to Google Home.
An alternative is to use Onjuvoice, which is a custom PCB that can fit within the housing of the Google Nest speaker. This way, you have more control over your microphone / speaker and can combine it with this AI voice control. Not sure about the quality of Onjuvoice though.
Thank you for posting this guide! This seems much easier than dealing with LocalAI with GPU acceleration.
My only issue is the LLM seemingly unable to call the correct services. I ask if my front door is locked, and it calls:
{"domain": "lock", "service": "is_locked"
(that’s a truncated part of the log, just to show the [wrong] service it’s calling) Home Assistant errors out with “Service lock.is_locked not found”.
If I ask it how much time is remaining on my washer - whose entity ID is front_load_washer_remaining_time - it tries to set the state, rather than read it.
Am I doing something wrong, or is this a limitation of the LLM?
This way, the model only has one function to choose from, and has to fill in all the context data by itself. This model is simply not good enough for that. It’s better to write a function for e.g. the lock state itself. You can check more function examples in the Extended OpenAI GitHub rep.
I’m testing this out on vast to find a good compromise of performance and cost. I’m looking at the benchmark numbers in the assistant debugger. Do the timings include latency to the vast GPU or is it only counting the time of the actual inference?
I think the pipeline debugger includes network delay etc. For better benchmarks, check the llama-cpp-python logs on VastAI.
My conclusion of testing a number of GPU’s: the speed of llama-cpp-python and compressed LLMs are the bottleneck and speeds as low as 3 seconds can be reached (incl network delay). When I tested the Functionary V2.4 FP16 model on a RTX 3090 with vLLM, I got to 1 second.
I use the Qwen model+localAI+Extended OpenAI Conversation+RTX3060-12G. The execution control is very fast (about 1 second). Always repeating what I say. And if the execution fails, it means repeating my words. If the execution succeeds, the reply to me is:
助手UI
Quick benchmarks for a RTX3060! Never heard of this LLM since its not in the Berkeley Function Calling Leaderboard. Are you sure it supports function calling?
And what backend is being used in LocalAI, llama.cpp?
I tried to use the Gorilla-OpenFunctions model in place of the functionary model from the OP. This is really the first time I’m dabbling in ML beyond as an end user, so I’m going through trial and error to try to get it to work.
The model seems to be targeted towards engineers trying to figure out how to call functions to do what they want and that’s the sort of response I get back. I don’t think it’s actually calling the functions to generate a useful response.
The Gorilla OpenFunctions website says the following: Note: Gorilla through our hosted end-point is currently only supported with `openai==0.28.1` . We will migrate to also include support for `openai==1.xx` soon with which `functions` is replaced by `tool_calls` .
So function calling on the newer OpenAI APIs is not yet implemented in this LLM.
I’m installing follow by your guide and have problem when add local llm cpp to home assistant via Extended Open AI. Please help me to see if I have mistake somewhere.
I install the LLama-cpp-python on a Windows machine and it’s running on http://172.23.126.96:8000/ . I’ve test if the docker working or not by post a json via API and this is the result
Next step. I adjust my Extended OpenAI Conversation by download init.py and replace it with the original file in /homeassistant/custom_components/extended_openai_conversation . Double check by open the new file init.py and see the 218th row where you have adjustment. I can see it is messages.append(query_response.message.model_dump()) . So this is the new init.py file, not the old one.
Restart Home assistant.
In the Extended OpenAI Conversation Intergration I add a new service like the picture below.
Reconfigure this service by enable Use Tools and mạke Context Threshold 8000.
Then I add this Local AI as Voice Assistant Conversation agent and test by text to my assistant. By when I ask everything it just show “Sorry, I had a problem talking to OpenAI: Request timed out.”
When I check the log in Llama-cpp-python docker, there is nothing happened there. This should be something error in Extended OpenAI that does not send any information to Llama-cpp-python.