I did discover one thing new about how time triggers work. Starting in 2022.12, there is a random offset of between 50 and 500 msec added to each time trigger (and some other things in the system that are scheduled to run at a particular second.) This means, e.g., if you have a time trigger at “09:00:00”, it will try to run at anywhere from “09:00:00.050” and “09:00:00.500”. Normally this isn’t an issue. It was done to prevent many, many time-based events, all scheduled at the same time (particularly, at a time whose microseconds component is zero), from all trying to run at exactly the same time. See Fix high latency from thundering heard at 0 microseconds by bdraco · Pull Request #82233 · home-assistant/core (github.com).
I should also mention that offset is calculated once per time-based event. I.e., for a particular time trigger, it will get a random offset that stays the same for that trigger. A different trigger will get a different offset, that then stays the same for that particular trigger, etc. To put that another way, each time trigger will have a different offset, but for each trigger its offset won’t be changing.
But this still doesn’t explain what you’ve been experiencing.
I’ve been refreshing my memory on how time-based things work in HA. The bottom line seems to be that there is a monotonic clock used for scheduling time-based events. When an event needs to be scheduled, the current time (i.e., time.time()) is subtracted from the desired time (typically from something roughly like now().timestamp()), to get a time delta (in seconds.) Then a “callback” is placed to run that (delta) amount of time in the future, based on the monotonic clock.
So, what does that all mean?
First, time.time(), now().timestamp(), etc. are based on the underlying OS’s time. If that time gets adjusted (NTP, etc.) between the time the event is scheduled (and for a fixed time trigger, that is basically once per day), and when it runs, that could, at least partially, explain the difference you’re seeing.
The other thing is, if the monotonic clock (which is not supposed to change when the underlying clock is adjusted, that’s the whole point of a “monotonic” clock) that is used for actually scheduling the events is drifting, that could also, at least partially, explain the differences.
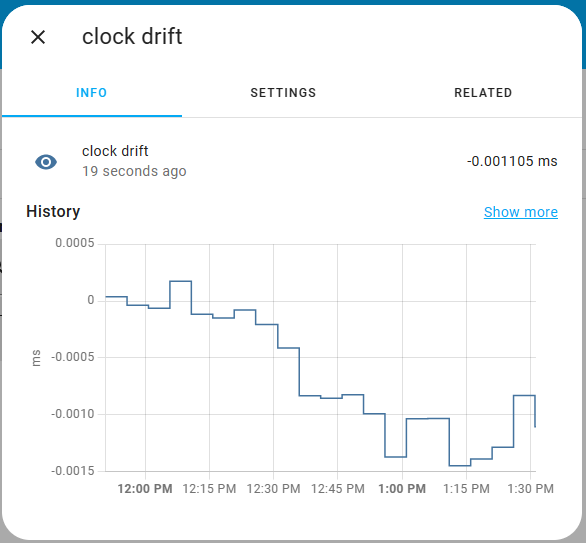
I’m running some experiments on my own system. I already have a relatively simple custom integration I wrote that does something every five minutes. I added code to it to check the difference between time.time() and the monotonic clock when it starts, and then every five minutes. If the underlying clock isn’t adjusted, and everything is working perfectly (which, of course, they never are), in theory the difference between time.time() and the monotonic clock should not change. Any change in that difference would be drift of one, if not both, of the clocks.
I’ve run it for a bit, and so far, it looks like on my system the drift is around 1 µsec / 5 minutes. That would mean the drift would be around 300 µsec or less per day.
EDIT: Sorry, that’s wrong. I initially misinterpreted the results. The difference is actually staying about the same, so for the short time I’ve run it, I do not see any drift.
If you’d like to try it, I can certainly whip up a custom integration that does just this. Right now, it’s just logging to home-assistant.log, but it would be easy for it to create a sensor that could be displayed in a history window. Let me know if you’re interested.
In the meantime, it would be interesting to know something more about your system. You said, “its a virtual machine running on virtualbox in a Macmini.” What do you have for acceleration under the VM’s system settings? Does the VBox UI, when HA is running, show that virtualization acceleration is enabled in the tray in the bottom right? Is virtualization acceleration (e.g., VT-x, etc.) enabled in the “system BIOS” (or whatever is the equivalent on a Macmini)?
Also, here is a potential, at least temporary, workaround…
Instead of using:
trigger:
- platform: time
at: "09:00:00"
Try this:
trigger:
- platform: template
value_template: "{{ now() > today_at("09:00:00") }}"
Note that a template trigger will “fire” when it evaluates as true after having evaluated as false. That means, if HA starts when it is already after the specified time, the template will evaluate as true. This will not cause it to fire (because it didn’t change from false to true.) It will have to evaluate as false (when it gets to midnight), and then evaluate as true (when it gets to specified time), for it to fire. Then, this repeats, meaning it will only fire once a day when it crosses from before the time to after the time. Note that the template will be re-evaluated at the beginning of every minute.
Just like a time trigger, it’s also possible to use the template trigger to compare the time against an input_datetime helper, if you should need that, too.