Thanks for your reply. I’m aware it’s not because of timescale or the ltss component, it’s just that, well, I got stuck on how to actually process the data, heh.
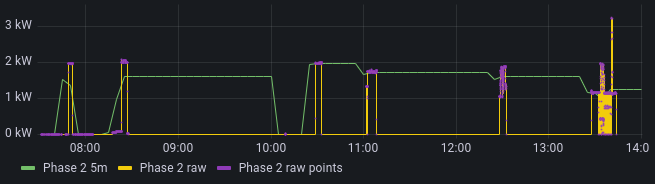
Grafana then always takes the last value, so long. Until it gets a new value.
time_bucket_gapfill, as far as I understand (and observe), is supposed to “create” datapoints for Grafana, so there are no gaps for Grafana to fill. It consistently creates datapoints at every $interval, in this case 5m.
This is reflected also by my continuous aggregate tables/materialized views, which reflect the same “wrong” data before hitting Grafana.
I have tried using the $__timeGroup("time",‘5m’, 0), which, interestingly, does something, but I’m not sure what. The resulting query functionally is identical to mine, but adding the macro makes Grafana handle it differently (but not correctly).
Below another graph, with the macro’d query in green, and a terrible hack that results in the correct data in red:

The query I came up with for this, while it does produce the correct data, is obviously extremely hacky and fragile, it first executes the actual query I want with a time_bucket_gapfill of less than the interval my data comes in (more than the interval, even setting it to 2s, completely messes up the data in a similar way to my original issue), as a subquery, then on the “complete” gap-less data it executes the actual time bucket I want:
SELECT time_bucket_gapfill('5m', "time") AS "time",
locf(
AVG(state_numeric)
) AS "Phase 2 5m awful"
FROM (
SELECT
time_bucket_gapfill('0.5s', "time") AS "time",
locf(
AVG(state_numeric)
) AS state_numeric
FROM ltss
WHERE
$__timeFilter("time")
AND entity_id = 'sensor.power_consumed_phase_2'
GROUP BY time_bucket_gapfill('0.5s', "time")
ORDER BY 1
) AS t1
WHERE
$__timeFilter("time")
GROUP BY time_bucket_gapfill('5m', "time")
ORDER BY 1
So in short, the issue is in the query somewhere, my “workaround” in red produces the correct results I want to see, but seems like an incredibly inefficient hack and I imagine there’s a much smarter way to do it.