I have some hopes on new framework releases to get rid of some memory management issues. The crashes that I see all seem related to invalid memory access. I’m currently working on getting everything compiled, because the single core processor is a bit of a challenge.
One thing that I noticed is that there seem to be two different issues:
-
The connection of Home Assistant to the ESP32 is dropped quite often, because the ESP32 reports that the final TCP ACK for an ESPHome ping sequence is not received by the ESP32 (and kills the connection). In tcpdump I do see an ack though, so it;'s either not transported to the ESP32, or it misses out on the packet. Right after the ESP32 sends the TCP FIN sequence, Home Assistant will always successfully reconnect.
-
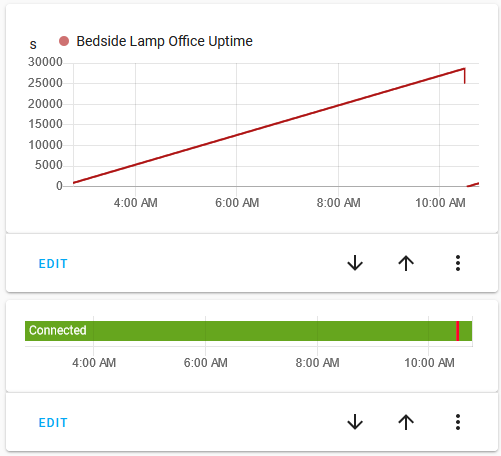
When I have the logging screen open from the ESPHome web terminal, then I do see ugly reboots of the device. When I don’t have any logging channel attached, the device seems stable. To test for reboots while not logging, I added the uptime sensor platform to the config. The below graph shows the uptime. Twice I had the logging console open, and those two times show up clearly in the uptime.

So still working on drilling this down. If I can get to the point where the device does not reboot, but loses its connection with Home Assistant once in a while, I am willing to accept that as a feasible setup. The connection loss in Home Assistant is irritating from a development standpoint, but it is not hugely disturbing for daily use.
Update:
I managed to hack and compile the firmware using [email protected] and [email protected], but unfortunately that did not change the disconnect and reboot behavior of the device  I just saw a few disconnects followed by a reboot. The reboot was still happening at
I just saw a few disconnects followed by a reboot. The reboot was still happening at src/esphome/components/api/api_server.cpp line 67 (which isn’t a surprise, since the esphome api code was not changed in the process, I mainly hoped for less disconnects triggering less reboots as a result).
Update:
Hello from deep down in the firmware code. I am in the process of debugging the recurring disconnects and I might have found something interesting. With extra debugging added, I see the following pattern:
SENSOR STATE IS PUBLISHED
[00:56:17][D][sensor:099]: 'Bedside Lamp Office Uptime': Sending state 462.02200 s with 0 decimals of accuracy
[00:56:17][VV][api.service:105]: send_sensor_state_response: SensorStateResponse {
[00:56:17] key: 1910806034
[00:56:17] state: 462.022
[00:56:17] missing_state: NO
[00:56:17]}
A TCP ACK IS REGISTERED, SETTING BUSY TO FALSE
[00:56:17]-S: 0x3ffd35c8
[00:56:17]_sent() sets busy = false: 0x3ffd35c8
[00:56:17]_sent() end of function, busy = 0: 0x3ffd35c8
A TCP SEND IS REGISTERED SETTING BUSY TO TRUE (which means: waiting for a TCP ACK)
[00:56:17]send() sets busy = 1, _pcb_sent_at=462060: 0x3ffd35c8
POLLING NOW CONTINUOUSLY SEES BUSY = TRUE
[00:56:17]-P: 0x3ffd35c8
[00:56:17][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=462223, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:17]-P: 0x3ffd35c8
[00:56:17][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=462723, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:18]-P: 0x3ffd35c8
[00:56:18][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=463223, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:18]-P: 0x3ffd35c8
[00:56:18][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=463723, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:19]-P: 0x3ffd35c8
[00:56:19][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=464223, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:19]-P: 0x3ffd35c8
[00:56:19][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=464723, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:20]-P: 0x3ffd35c8
[00:56:20][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=465223, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:20]-P: 0x3ffd35c8
[00:56:20][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=465723, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:21]-P: 0x3ffd35c8
[00:56:21][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=466223, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:21]-P: 0x3ffd35c8
[00:56:21][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=466723, _pcb_sent_at=462060, _rx_last_packet=462056
[00:56:22]-P: 0x3ffd35c8
[00:56:22][W][AsyncTCP.cpp:963] _poll(): _pcb_busy=1, now=467223, _pcb_sent_at=462060, _rx_last_packet=462056
UNTIL IT DECIDES IT IS A TIMEOUT
[00:56:22]_poll() sets busy = false after ack timeout: 0x3ffd35c8
[00:56:22][W][AsyncTCP.cpp:969] _poll(): Houston, we have an ack timeout 4
[00:56:22][V][api.connection:696]: Error: Disconnecting Home Assistant 2021.3.2 (192.168.100.135)
The weird thing in the pattern here, is that there is a send in the log that is coming AFTER the ACK that to me looks like the ACK for the send call. If the code handles these two events in the wrong order here (sometimes), then the timeout can be explained very easily.
Some signs that this might indeed be a code issue:
- The timeout is always on this step of the data exchange.
- The connection seems to work just fine. I do see the correct TCP flows when scanning the network at the Home Assistant side.
- When I hack the code to simply ignore the ACK timeouts, then the socket connection with Home Assistant is kept as-is and it is still very much functional. I get update and can change light settings, without running into issues. So disabling the timeout check, actually makes my device more stable

- It is also likely not Home Assistant that is breaking the network connection here, because the same kind of connection drops can be observed when viewing logging from the ESPHome web console. This means I have two endpoints that show the same behavior, making the network stack in the ESP32 more likely the culprit.
Unfortunately, one needs to sleep at some point, so I’ll continue this bug hunt tomorrow.
Update:
With some more debugging I am now 100% sure that there is a race condition going on, and that the ACK is processed before the AsyncTCP code has decided that it wants to process an ACK.
I color coded the console output and what you see is the red text, which is interrupted mid sentence by the green text. I also added timestamps (now = …) and those proof 100% that this is a race condition. The earlier logline in green has a later timestamp than the last bit of the interrupted red log line.
Going to cook up a fix and see if the upstream project can incorporate it!
Update: Issue created with AsyncTCP upstream
I created an issue ticket for AsyncTCP.
And I creaed a fix in a forked repo, which I described in another thread.