One thing I remember is that the Grafana Flux plugin would not let me save until I put in a bogus token. Otherwise I think that is all that’s needed but it has been a couple months.
Having issues trying to remove traces of 1.6 and install 1.7.7.
I’ll persist but can be a right pain sometimes
Gone full Ubuntu. Killed the processor consuming windows 10. Lightning speed now.
But haven’t figured out how to import a snapshot yet.
Building it fresh from scratch
ok now I’m getting this error after installing the flux plug in from grafana-cli:
403 Forbidden: Flux query service disabled. Verify flux-enabled=true in the [http] section of the InfluxDB config.

But it is enabled in the config.
Grafana v7
influxdb 1.8
influxdb is pulling in data from homeassistant
CANNOT access the influxdb from the browser UI either but it is running as a container. 404 error.
I have not seen that error. This is my Hass.io InfluxDB configuration, for what it’s worth.
auth: true
reporting: true
ssl: true
certfile: fullchain.pem
keyfile: privkey.pem
envvars: []
Have you been able to configure the flux datasource in Grafana ?
I believe the url should be http://a0d7b954-influxdb:8086 (check the influxDB datasource) but I don’t know how to get my organization id.
Using the influx cli gives me an “ERR: unable to parse authentication credentials” error
I don’t think we can access the influx ui on the port 9999 when using Frenck’s Addon.
Any help ?
Gave up on flux beta addon.
Got influxdb connected fine yes with the addon.
But finally ended up using mariadb and that is also connected in grafana.
Use mysql workbench on my main pc with an odbc connection also.
Much more familiar with mysql.
Has anyone gotten the flux addon to work with grafana? I am running HassOS and just installed the InfluxDB and Grafana add-ons and can’t seem to figure it out. All the guides or forums I read seem to be out of date or I’m missing something because I can’t seem to find the organizationid or token that the Grafana flux plugin wants.
Any help would be greatly appreciated.
Same problem here, no way to find the access token? Pitty, I could do a lot more with flux!
I didn’t need a real token, just put in a bogus one.
ive entered the url im using for the normal influx db and bucket as name of database put in the password as token but it still wont connect.
What exactly did you put in?
I think that the problem is because the influxDB version of the HA addon is V1.8.3. Although it has flux enabled (and you can test it via the UI) it is not the latest.
The problem with Grafana is that the plugin is expecting V2.0 which comes with new API and concept and therefore you may not be able to do it anymore.
@rpress, you probably managed to put it to work when the version of the plugin was only working for V1.8… now that is only for V2.0 it shouldn’t work (at least until the addon in updated to 2.x or if you install a separate instance)
I know this is an old thread, but for the record I managed to get the Flux datasource working on InfluxDB 1.8.3 with Grafana 7.3.6. Step 1 was to enable the flux api in influxdb by adding
flux-enabled = true
to influxdb.conf under [http].
Step 2: Add a new data source, using the previous URL, but with adding "" to the organization field (yes, the two quote marks are needed, not just leaving it empty) and myuser:mypassword into the Token field.
Now I just need to figure out the new query syntax…
Sources for the instructions:
6 Likes
This took me some time to figure out, so just in case somebody needs it, here’s a basic query in the Flux language that works with a typical sensor recorded from Home Assistant in Influxdb:
from(bucket: v.defaultBucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "°C" and r.entity_id == "name_of_sensor" and r._field == "value")
|> keep(columns: ["_field", "_time", "_value"])
|> set(key: "_field", value: "Value Alias")
Change "°C", "name_of_sensor" and "Value Alias" as necessary.
Here’s a bit more advanced, a -24h time shifted set of values, to compare previous days with the current data set:
import "experimental"
shift_val = 24h
from(bucket: v.defaultBucket)
|> range(start: experimental.subDuration(d: shift_val, from: v.timeRangeStart), stop: experimental.subDuration(d: shift_val, from: v.timeRangeStop))
|> timeShift(duration: shift_val)
|> filter(fn: (r) => r._measurement == "°C" and r.entity_id == "name_of_sensor" and r._field == "value")
|> keep(columns: ["_field", "_time", "_value"])
|> set(key: "_field", value: "-1d")
These are using some of the Grafana macros, explained here:
5 Likes
cool… the step 2 trick worked like charm. Thanks
I didn’t check step 1 since I used flux in the chronograf ui from the HA influx Addon so I knew it was active.
A little hint for getting the friendly names shown in the legend of Grafana without setting name aliases all the time:
You can use a rename-by-regex transform to catch the name using a capture group and use the result ($1) as the replacement text.

2 Likes
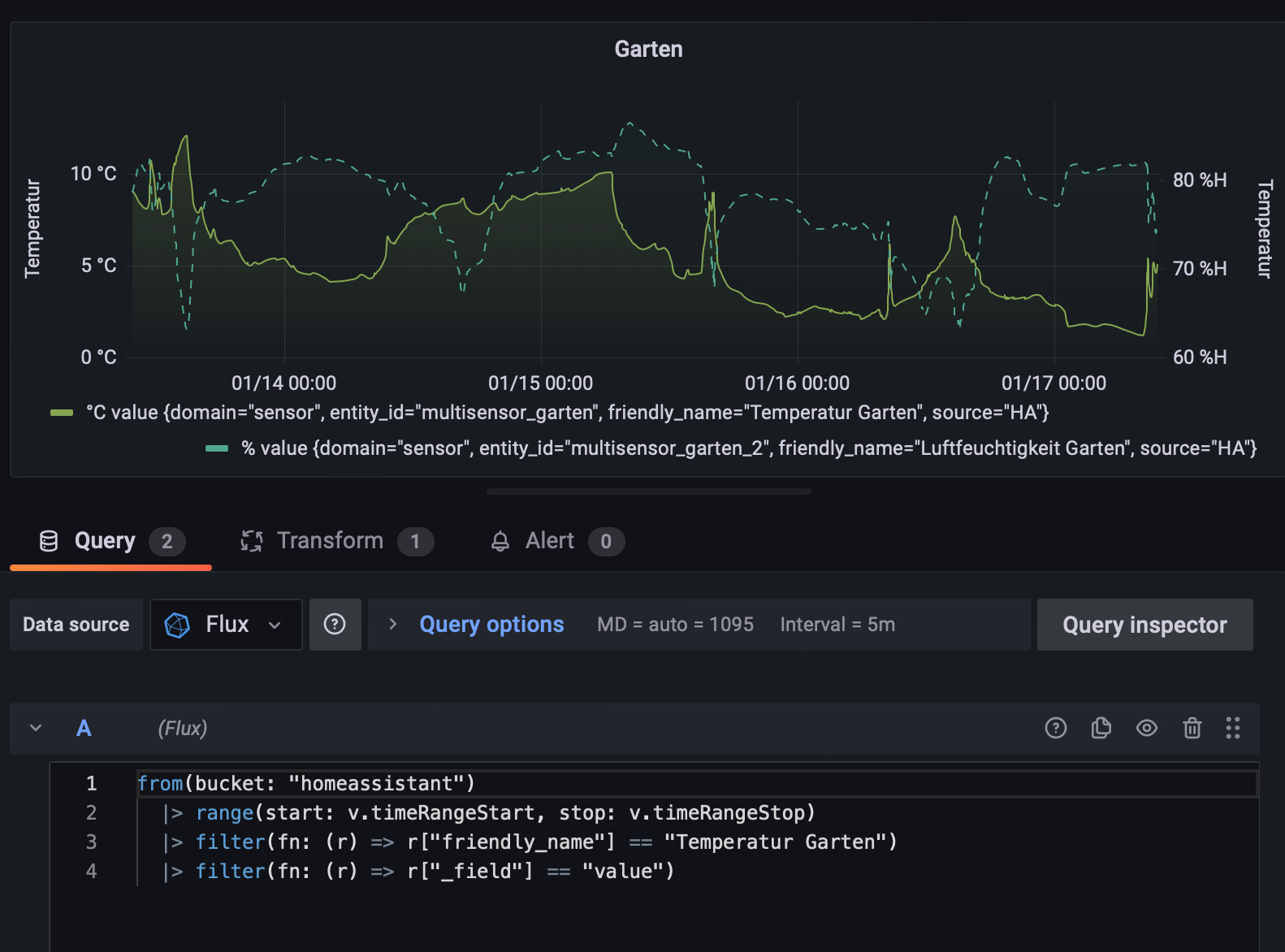
And another tip for better looking charts with Flux,
by avoiding gaps at the beginning or the end of the chart.
This query:
- Loads data points from a few hours in the past of the currently selected timerange.
This way the lines will be drawn from the start of the chart without a gap at the beginning. - Loads data points from a few hours in the future of the currently selected timerange.
This way the lines will be drawn until the end of the chart when you scrolled back in time - Loads the last value of the sensor separately and sets the timestamp to “now()”.
That way the line gets extended to the current time (if the current time is currently in the visible timerange) instead of ending at the last data point. - Creates a union of these 2 requests
- Drops columns that will result in Grafana thinking that this would be 2 seperate signals, so we get one combined line
You have to choose the pre- and post-duration according how often your sensor will at least update.
I used 6h, as my temperature sensors normally update quite often. I’ve never seen gaps longer than 2h in the past.
If you choose the timespan very long (like a year  ), your sensor better doesn’t update too often or you might run into performance issues…
), your sensor better doesn’t update too often or you might run into performance issues…
import "date"
history = from(bucket: "homeassistant")
|> range(start: date.sub(d: 6h, from: v.timeRangeStart), stop: date.sub(d: -6h, from: v.timeRangeStop))
|> filter(fn: (r) => r["friendly_name"] == "Temperatur Wohnzimmer")
|> filter(fn: (r) => r["_field"] == "value")
extend = from(bucket: "homeassistant")
|> range(start: date.sub(d: 6h, from: now()), stop: now())
|> filter(fn: (r) => r["friendly_name"] == "Temperatur Wohnzimmer")
|> filter(fn: (r) => r["_field"] == "value")
|> last()
|> map(fn: (r) => ({r with _time: now()}))
union(tables: [history, extend])
|> drop(columns: ["_start", "_stop"])
2 Likes
Amazingly helpful, thank you! Odd that this info still doesn’t seem to be officially documented.
I improved my last snippet (loading data before and after the visible time range + extend line until “now” with the last value).
It now uses variables, so it’s easier to copy & paste to new panels, as you only have to edit in one place on the top of the query.
It also only requests the first value before and after the timerange instead of all values in the extended timespan.
Visually, this isn’t any different, but it leads to less transfered data which might speed up refresh on mobile connections:
import "date"
friendly_name = "Temperatur Wohnzimmer"
extend_duration = 24 // hours
extend_duration_ns = extend_duration * 60 * 60 * 1000 * 1000 * 1000
prefill = from(bucket: "homeassistant")
|> range(start: date.sub(d: duration(v: extend_duration_ns), from: v.timeRangeStart), stop: v.timeRangeStart)
|> filter(fn: (r) => r["friendly_name"] == friendly_name)
|> filter(fn: (r) => r["_field"] == "value")
|> last()
history = from(bucket: "homeassistant")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["friendly_name"] == friendly_name)
|> filter(fn: (r) => r["_field"] == "value")
postfill = from(bucket: "homeassistant")
|> range(start: v.timeRangeStop, stop: date.sub(d: duration(v: -extend_duration_ns), from: v.timeRangeStop))
|> filter(fn: (r) => r["friendly_name"] == friendly_name)
|> filter(fn: (r) => r["_field"] == "value")
|> first()
extend = from(bucket: "homeassistant")
|> range(start: date.sub(d: duration(v: extend_duration_ns), from: now()), stop: now())
|> filter(fn: (r) => r["friendly_name"] == friendly_name)
|> filter(fn: (r) => r["_field"] == "value")
|> last()
|> map(fn: (r) => ({r with _time: now()}))
union(tables: [prefill, history, postfill, extend])
|> drop(columns: ["_start", "_stop"])
|> sort(columns: ["Time"])
1 Like
@yonny24 please can you make this the ‘Selected Answer’? This appears to solve the problem you asked, and will make it quicker to find for everyone!
Thanks @attila_ha - this post and your next one have massively helped me solve what I was looking for.
I was trying to look at my energy consumption for each day of the week, accumulated and averaged over the last 30 days/1 year etc. Couldn’t find the answer anywhere, but seems you can do it with Graphana ‘X-Y’ Chart and Flux The below query does that, although needs a little tidying up to display a nice graph:
import "date"
from(bucket: "homeassistant/autogen")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "kWh" and r.entity_id == "solarman_daily_house_backup_load_consumption" and r._field == "value")
|> keep(columns: ["_field", "_time", "_value"])
|> map(fn: (r) => ({ r with _day: date.weekDay(t: r._time) }))
|> aggregateWindow(every: 1d, fn: max)
|> set(key: "_field", value: "Value Alias")