I have a problem with my HAOS installation which has been working fine for more than a year. After an uptime of less than 24h it becomes unusable due to high disk reads and cpu load also increases to unusual ranges. (Proxmox VM, 2 cores, 3GB RAM).
I have no idea how to identify what causes the disk reads since it seems impossible to install additional packages on HAOS.
What I have tried:
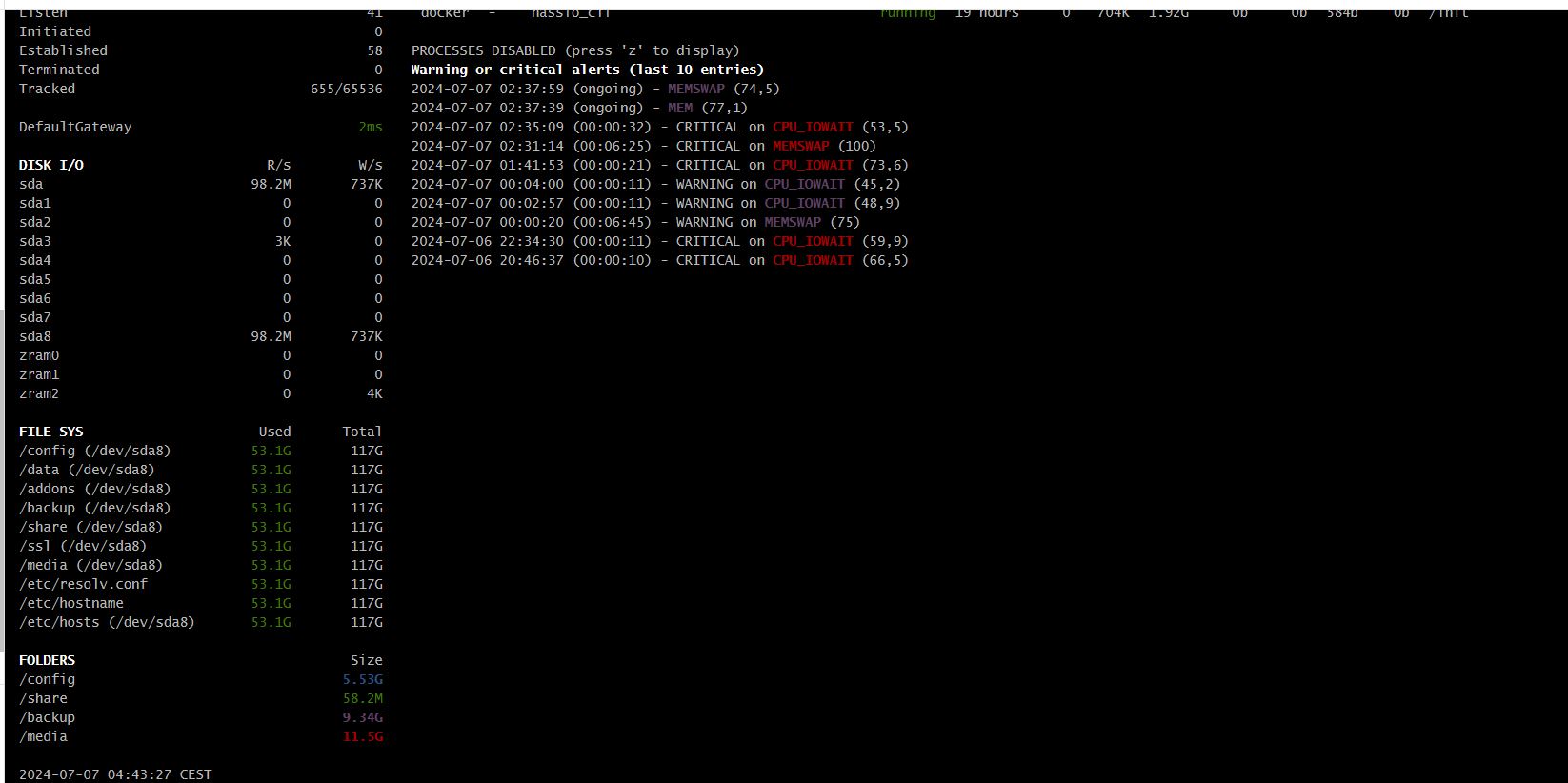
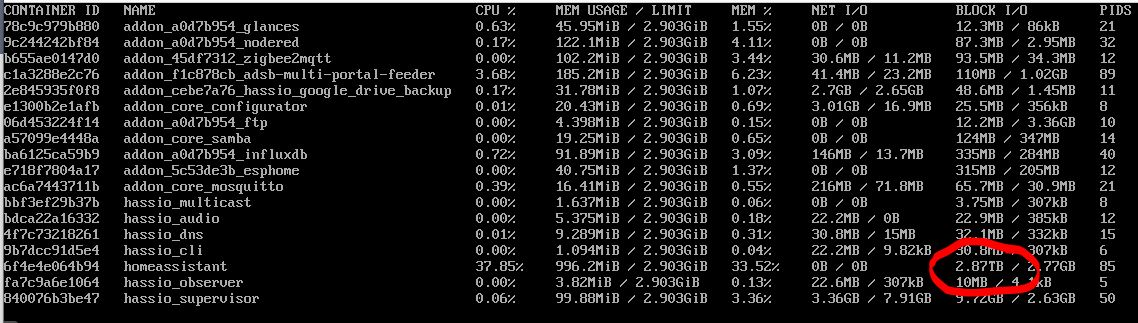
Glances Addon - tells me that the homeassistant docker image is the main cause of the cpu load, but not why. Shows me high disk reads without significant writes, so I assume it is not caused by swapping. Increasing ram on the machine also did not solve the problem.
Running “top” on HAOS - tells me nothing new, interestingly the cpu load shown here is always significantly lower than the one that Proxmox displays for the machine at the same time (e.g. 13 vs 50%)
On HAOS level, in command line you do nothing. You did unnecessary troubleshooting. First of all find out how to get logs from this particular LXC container or virtual machine in Proxmox. Proxmox does not use Docker. So this is something that is weird. I suppose you installed it using Proxmox script for Home Assistant. Am I right? You can always do a backup to a Google Drive. Get rid of this machine from Proxmox, install Home Assistant using the script made for Proxmox that will install HA for you in Proxmox and then you install the backup plugin for Google drive and restore the backup.
I perfectly understood what you wrote in the first post. Well, just in Proxmox usually people install Home Assistant as a LXC container rather than a virtual machine. If this is a virtual machine, then well I suppose it contains a Docker. What sudo docker ps shows? Is Docker up to date on this virtual machine? What distro is running in this virtual machine? What sudo cat /etc/os-release shows? Is the distro up to to date? I do not know the script you mentioned. What sudo sar displays? By the way you can read about sar usage. Which exact script did you use to install Home Assistant? I can analyse it. If you are using Portainer, is the Portainer up to date?
I would make a backup of your Media folder and then delete everything in it to see if that reduces the disk reads. The next option would be to stop/disable Add-Ons and Integrations one at a time to see if you can isolate one of those as the cause.
I just noticed that your Media folder is 11.5 gig and thought something might be reading or indexing it. Your Config folder is 5.5 gig, while mine is 63 meg, so that seems quite large also. You might want to see what files in those folders are using the most space. What is the size of your HA database?
The only logic reason is that Home Assistant is doing something exactly at this exact time. So I would reconsider to write a script for Alpine to monitor processes that are running. You can then run the script using a crontab directly at the same time and monitor running processes with top, iotop and ps -ef or ps aux. I will write a script and put it here for you.
Here is a Bash script that will monitor CPU usage, I/O usage, disk, RAM, and swap usage for 60 minutes and log the output to a file in a human-readable format. You can schedule this script to run at 4 am using crontab.
SELECT table_schema "database", Round(Sum(data_length + index_length) / 1024 / 1024, 1) "value" FROM information_schema.tables WHERE table_schema="homeassistant" GROUP BY table_schema;
No, it started at 2. There was a sync that started at 4:00 AM, but stopping the Google Drive Backup-Addon did not change the crazy amount of disk reads.
07-08 02:13:11 INFO [backup.drive.drivesource] Deleting 'Partial Backup 2024-07-05 02:00:00' From Google Drive
07-08 02:13:12 DEBUG [backup.watcher] Checking backup source for changes...
07-08 02:13:12 DEBUG [backup.model.syncer] Sync requested by Backup Directory Watcher
07-08 02:13:12 INFO [backup.model.coordinator] Syncing Backups
07-08 04:01:37 DEBUG [backup.model.destinationprecache] Preemptively retrieving and caching info from the backup destination to avoid peak demand
07-08 04:01:37 DEBUG [backup.drive.driverequests] Requesting refreshed Google Drive credentials
07-08 04:01:39 DEBUG [backup.model.syncer] Sync requested by Coordinator
07-08 04:01:39 INFO [backup.model.coordinator] Syncing Backups
07-08 05:32:38 DEBUG [backup.model.destinationprecache] Preemptively retrieving and caching info from the backup destination to avoid peak demand
07-08 05:32:38 DEBUG [backup.drive.driverequests] Requesting refreshed Google Drive credentials
07-08 05:44:45 DEBUG [backup.model.syncer] Sync requested by Coordinator
07-08 05:44:45 INFO [backup.model.coordinator] Syncing Backups