My 2 cents on “extend the life of your SD card”:
- You can use eMMC with adapter in place of an SD card: SOLUTION : Hassio HA Database in Memory - #10 by lmagyar1973
- I’ve made an add-on that runs MariaDB on tmpfs, so it is an in-memory database. See: In-memory MariaDB (MySQL) add-on for recorder/history integration
- This is a fork of the official add-on!
- This version uses tmpfs to store MariaDB databases in-memory.
- Even this is an in-memory database, it can automatically export (from memory to SD card) the database’s content during backup, update, restart or even periodically, and can automatically import (from SD card to memory) the content when the add-on starts again. The database dump is gzip-ed before written to the storage to minimize SD-card wear.
- Though it won’t protect you from power failures completely. After a power failure, when the add-on is restarted, it will import the last known exported database content. So when eg. daily periodic export (from memory to SD card) is enabled, you will loose the latest sensory data within that day, but your long term statistics information will remain mostly intact:
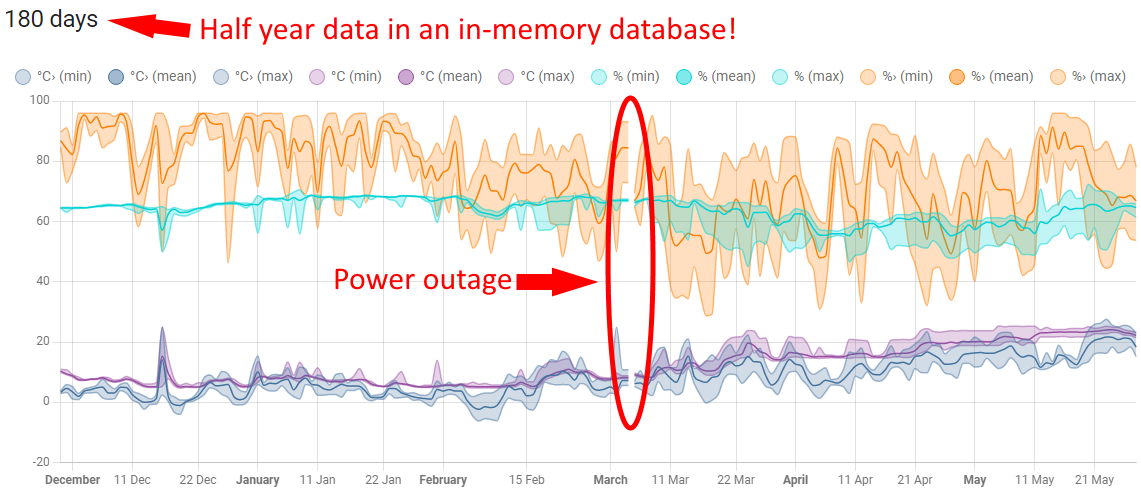
But first you have to really minimize the amount of data you want to store in the in-memory database!
I store only the necessary entities for graphs/charts, I turned on the regular, daily export (memory->SD) to protect against power failures, and I turned on to delete the old statistics that I don’t want to display. The best is to keep the DB size only a few 10MB.