To be honest @mbuscher beat me to the punch. To be fair I troubleshoot MSSQL for the past 20 years so I gravitate to that if it’s in the cards — however, we’re talking about 2-3 minutes of reviewing the SQL results vs. lots of Excel manipulation. The idea and the point of your post is a good one and caused me to pay more attention to my DB size (which I already was just not too closely as of late) but the SQL approach is certainly the faster and cleaner one. Please do link to @mbuscher’s reply in your original post for the 50% of the audience that’d want to use the SQL approach.
I had a noticeable king offender:
|entity_id |cnt |
|automation.battery_sensor_from_attributes |416328|
|sensor.multisensor_feather_2_7 |44592 |
|sensor.multisensor_feather_2_6 |43528 |
So go and write a community guide on using SQL to reduce your database size.
1 Like
Don’t get so defensive just trying to complete that guide you have above — the dude above already wrote it in a very concise fashion. Folks should probably invest the 15-30 minutes of time learning how to query MySQL, MariaDB or even SQLite all of which are much simpler to do than any other method. Not mentioning or acknowledging the alternatives in your guide is not exactly the best thing to do either as it sends folks down much longer roads.
I’m not being defensive I think it is a good idea. Just a different one that deserves it’s own guide.
The instructions above are far from comprehensive, e.g.
To do so, you’d need SQL access to the database,
Great, how’s that done then?
And they would be better as a full guide In their own right rather than tacked on here as a comment that few will read.
Running MySQL or MariaDB it’s as simple as executing the following based on the query that @mbuscher posted:
mysql -h localhost -uusername -ppassword -Dhass -e"SELECT entity_id, COUNT(*) AS cnt FROM states GROUP BY entity_id ORDER BY COUNT(*) DESC;"
-h is host, -u and -p are user/pwd — DO NOT ADD SPACE after those two params, learned the hard way many moons ago. -D is db name and -e is the SQL command to execute. You can also redirect that to file with > filename.txt at the tail end — or mysql command may have some “output file” parameter you could pass to it…
I see you pulled down your guide — certainly not my intent. Your guide explores a few other interesting techniques, just offer the alternatives.
1 Like
I also think it’s a shame you took it down, 21 likes in 4 days must mean something.
Also it at least refreshed a few thigs in my mind so it was useful to me even though I hadn’t got round to using your method (my recorder is set up quite nicely already).
(and you changed your icon  )
)
State will no longer be duplicated in the events table in 0.112 and later. This should significantly reduce the size of the database.
2 Likes
Will this improvement (lookup state with a join) require converting an existing database to a new structure?
I would ‘assume’ that when you apply the upgrade it will make any necessary databases changes. I have looked at the code, but that’s the way that most software programs handle it.
I don’t doubt any structural changes will be handled automatically during the upgrade as opposed to performing them manually. The database’s structure was changed many versions ago (and the conversion process was automatic).
Just trying to get a reading on the scope of the database’s changes. If a structural change is required, it may impact the user’s ability to rollback to a previous version and retain history collected since the upgrade.
The schema change will happen automatically on update to 0.112, no action is required.
A new column old_state is added to the states table that can be used to find the old_state.
Events created before v8 schema will have the state data stored in event_data and not have the old_state column set in the states table (We were storing the state 3 times, old_state, new_state in event_data, and then in the states table).
Events created after v8 schema will have an empty event_data and the state data should be found with a join as described in the updated documentation.
It is too expensive back populate old_state as it could delay startup for a long time on large databases.
The logbook api is aware of the change and knows how to handle rows that have old_state or event_data. Once all the pre-v8 data has been purged (https://www.home-assistant.io/integrations/recorder/#auto_purge), we can improve performance a bit more as we won’t have to check to see if the row is in pre-v8 format anymore.
If you roll back after updating you won’t be able to see the events created by 0.112 until you update again. Rollbacks are not recommended as we don’t explicitly test rolling back so YMMV.
2 Likes
I have an issue with the edit to the main post. Using the template editor tool may not work for everyone. I was unable to select more than 30 lines or so without losing the previous selection. Also the output of the template editor (then spreadsheet) is not able to be directly pasted into the logbook configuration as it does not have the required indentation. Hence the notifier method. Which I will now reinstate.
There is also a problem using this method for the History integration (which I have decided to use after-all). Includes and Excludes do not work the same was as for the logbook and recorder. Excluding a domain and including an entity from that domain does not work for History, it does work for the logbook and recorder. The solution for me was to just use entity includes for the History integration.
I seem to have bottomed out at 850MB down from 1500B. A 43% reduction.
Looking forward to the improvements in 0.112 as events seem to be the largest chunk of my DB now.
2 Likes
If you paste the templates into the developer tools as the only content (delete everything else first), you can use your browser’s tools to copy out the content. For example, in Chrome you’d hit F12 for DevTools, use the inspect tool to select the template output, right-click the <pre class="rendered"> element in the source view and Copy Element.
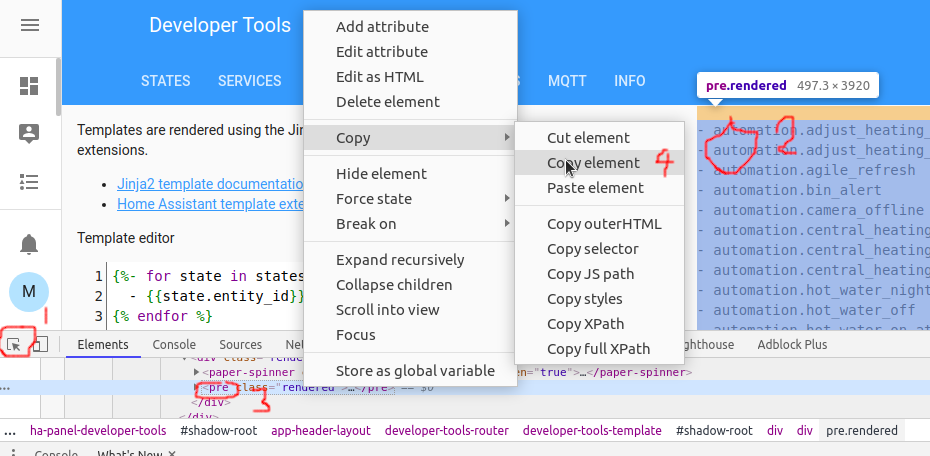
That pastes straight into your spreadsheet, with just the first and last entities needing a bit of HTML removal.
1 Like
It still does not have the required indentation for pasting into the config later.
True, but that’s relatively easy to add in the spreadsheet: search-and-replace "- " for " - ". I could do this quicker than the time it takes to restart HA, and I haven’t had to mess around with my config files.
Feel free to add it as an option. But please don’t delete the file notification version.
… ashamed to admit I had not realized we can set the history items too… I am all in to minimizing what’s been recorded, and have meticulously set logbook and recorder (always thought recorder set the history items…duh)
will add immediately, so thanks for this!
fwiw, I excluded these, and only add the individual entities in include ![]()
exclude:
event_types:
- service_removed
- service_executed
- platform_discovered
- homeassistant_start
- homeassistant_stop
- feedreader
- service_registered
- call_service
- component_loaded
- logbook_entry
- system_log_event
- automation_triggered
- script_started
- timer_out_of_sync
domains:
- alert
- automation
- binary_sensor
- camera
- climate
- counter
- customizer
- device_tracker
- group
- input_boolean
- input_datetime
- input_number
- input_select
- input_text
- light
- media_player
- proximity
- scene
- sensor
- script
- sun
- switch
- persistent_notification
- person
- remote
- timer
- updater
- variable
- weather
- zone
1 Like
Not seen it mentioned but sometime around 110 they added a new command option to tune the commit interval on the DB.
All the above is still relevant to cut down on what is stored in the DB, but by upping the commit interval you can batch commit which will lead to far fewer writes.
I use a 15 second interval which has drastically reduced the number of writes to the DB, and confirmed by monitoring with iostat
commit_interval: 15
1 Like
I always thought so. Maybe it is just the docs that are misleading ?