First of all: I use InfluxDB v2.7 and I have never installed VictoriaMetrics.
I was thinking about VM to have faster queries (not that I need it…) and less space on disk, then I found that
- VM cannot delete single points or arbitrary groups of points, only WHOLE metrics (it’s meant to be used for compliance with data protection laws…)
- the query language PromQL used by VM is not that straighforward and intuitive (to me)
- InfluxDB v2 with Flux queries can perform on its own QUITE some data processing without resorting to external scripts
At this point, I stopped being interested in VM.
And I was right, here a practical case.
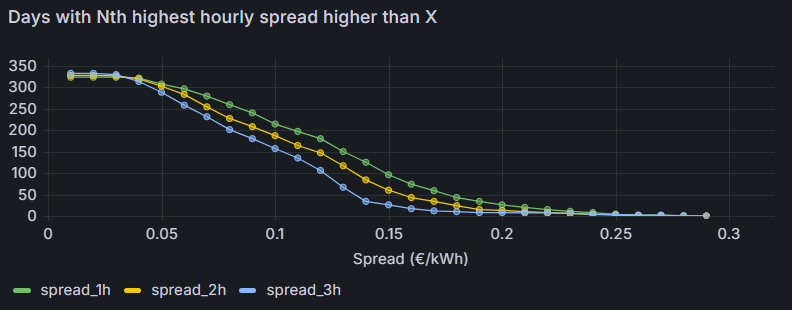
I wanted to calculate the number of days in a year for which the hourly energy price spread is above a threshold, where the spread should be calculated on the Nth best spread (so, N=1 would be the very extremes, N=2 would be the spread between second highest and second lowest hourly price, amd so on). It’s useful to plan home battery systems (how many cycles can I perform a year? what is the average economical return per dis/charge cycle?).
I had to resort to some AI help (Gemini v2.5 Pro work quite well, whiel v2.5 flash ok but misses syntax, and Chatgpt is behind), but at the end I came up with:
import "influxdata/influxdb/schema"
import "array"
// Helper function to calculate the spread between the minimum of the top N
// and maximum of the bottom N values in a stream of tables.
//
// n: The number of top/bottom elements to consider.
// column: The column to operate on.
// tables: The stream of tables to process, passed implicitly.
calculateSpread = (n, column, tables=<-) => {
// Calculate the minimum of the top N values. This returns a stream.
top_mean_stream = tables
|> top(n: n, columns: [column])
|> min(column: column)
// Calculate the max of the bottom N values. This also returns a stream.
bottom_mean_stream = tables
|> bottom(n: n, columns: [column])
|> max(column: column)
// Union the two streams (each containing one table/row) and calculate
// the spread between the two values. This correctly returns a new stream
// with the calculated spread as its value.
return union(tables: [top_mean_stream, bottom_mean_stream])
|> spread(column: column)
}
// function to calculate inverse histogram
// n: The number of top/bottom elements for calculateSpread.
// outputField: The string value to set for the "_field" column.
// tables: The stream of tables to process, passed implicitly.
higherThanHistogram = (n, outputField, tables=<-) => {
// Aggregate to daily spread using the calculateSpread function
dailySpread = tables
|> aggregateWindow(
every: 1d,
fn: (column, tables=<-) => calculateSpread(n: n, column: column, tables: tables)
)
// Calculate the histogram (cumulative less than or equal to)
cumulativeHistogram = dailySpread
|> histogram(bins: linearBins(start: 0.0, width: 0.01, count: 30))
|> set(key: "_field", value: outputField) // Use the outputField parameter here
|> drop(columns: ["_start", "_stop"])
// follows the cutting of the last "infinite bin" generated by "histogram"
|> limit(n: 1000,offset: 1)
|> tail(n: 1000,offset: 1)
// Get the single record containing the maximum value from the histogram.
// This results in a record object, not a stream.
maxRecord = cumulativeHistogram
|> group() // Group all rows to find the overall maximum
|> max(column: "_value")
|> findRecord(fn: (key) => true, idx: 0) // Extract the single record as an object
// Safely extract the float value from the record, defaulting to 0.0 if the histogram was empty.
totalCount = if exists maxRecord._value then float(v: maxRecord._value) else 0.0
// Calculate the "greater than" counts
return cumulativeHistogram
|> map(fn: (r) => ({
r with
_value: totalCount - r._value
})
)
}
// Main query starts here
data = from(bucket: "home_assistant/autogen")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "€/kWh")
|> filter(fn: (r) => r["entity_id"] == "current_electricity_market_price")
|> filter(fn: (r) => r["_field"] == "value")
|> aggregateWindow(every: 1h, fn: mean, createEmpty: false)
|> drop(columns: ["domain", "entity_id", "source", "friendly_name"])
spread_1h = data
|> higherThanHistogram(n:1, outputField: "spread_1h")
spread_2h = data
|> higherThanHistogram(n:2, outputField: "spread_2h") // Corrected n and outputField
spread_3h = data
|> higherThanHistogram(n:3, outputField: "spread_3h") // Corrected n and outputField
union(tables: [spread_1h, spread_2h, spread_3h])
|> drop(columns: ["_start", "_stop"])
|> pivot(rowKey: ["le"], columnKey: ["_field"], valueColumn: "_value")
|> rename(columns: {le: "Spread (€/kWh)"})
The result is:
This would be almost completely impossible if I were using VM, unless I wrote a Python script or equivalent, to be run offline (while Grafana allows me to change on the fly the time interval).
I asked Gemini V2.5 Pro:
For comparison, can you rewrite it (if possible) using PromQL, the query language of Prometheus, or a query language which VictoriaMetrics (which is based on Prometheus, with more capabilities) can understand?
The answer was:
It’s not possible to rewrite your entire Flux query into a single, equivalent PromQL or MetricsQL query.
The fundamental reason is that your Flux script performs a multi-stage analysis: it first calculates a derived value (the daily spread) and then performs a second level of aggregation on those results (the histogram). PromQL and MetricsQL are designed to perform one level of aggregation over a set of raw time series, not to re-process the results of a previous aggregation within the same query.
However, you can achieve the same goal by using the standard Prometheus/VictoriaMetrics approach, which combines server-side pre-aggregation (using recording rules) with client-side visualization.
The Conceptual Difference
- Flux: Uses a data-flow model where you can pipe the results of one transformation into another, allowing for complex, multi-stage calculations entirely on the server within one script.
- PromQL/MetricsQL: Uses a functional model where you select a vector of time series and apply aggregation functions to it. It is not designed for sequential, dependent calculations on derived data in a single query.
 Step 1: Pre-Aggregating the Data with Recording Rules
Step 1: Pre-Aggregating the Data with Recording Rules
The idiomatic way to handle this in Prometheus or VictoriaMetrics is to create recording rules. These rules run at a regular interval, calculate new metrics from existing ones, and save them back to the database. This makes the final querying fast and simple.
First, you would create a rule to calculate the hourly mean, similar to your first aggregateWindow.
Then, you’d create rules to calculate the daily spread for each value of n. For this, we’ll use MetricsQL functions, which are a superset of PromQL. The key is to use quantile_over_time to find the Nth highest and lowest values.
Here is an example of what these rules would look like in a YAML file:
(here come some YAML code…)
 Step 2: Querying and Visualizing in a Client (like Grafana)
Step 2: Querying and Visualizing in a Client (like Grafana)
Now that the complex calculations are done and stored, your work in the querying client (like Grafana) becomes incredibly simple. You cannot generate the inverse histogram directly in the query, but you can pull the raw spread values and let Grafana create the histogram for you.
- Query the Data: In your Grafana panel, you would query the pre-calculated spread metrics. To get all three on one graph, you could use a regex:
Snippet di codice{__name__=~"electricity:price_spread_daily:n[1-3]"}This query fetches the daily spread values for n=1, n=2, and n=3.
- Use Grafana’s “Histogram” Visualization:
- Change the panel visualization type to Histogram.
- Grafana will take the values returned by the query and automatically bucket them, creating a histogram from the spread data.
- Create the Inverse Cumulative Histogram:
- In Grafana’s “Transform” tab, you can add a transformation to calculate the cumulative count and then use another transformation (“Add field from calculation”) to compute
Total - Cumulative.
- Alternatively, many visualization options have a “Cumulative” display switch, and you can often configure it to show an inverse or “greater than” view.
 Summary of the Difference in Approach
Summary of the Difference in Approach
| Aspect |
Flux / InfluxDB |
PromQL / VictoriaMetrics |
| Complexity |
Handled in a single, complex server-side query. |
Split between server-side recording rules and client-side visualization. |
| Histogram |
Calculated on the server using histogram(). |
Calculated on the client (e.g., Grafana) from the pre-aggregated data. |
| “Nth Value” |
Done with top() and bottom() functions. |
Approximated very effectively with quantile_over_time(). |
| Final Query |
The entire script you wrote. |
A very simple query like {__name__=~"electricity:price_spread_daily:n[1-3]"}. |
So I would need to STORE INTERMEDIATE results in VM to be able to do what I needed. And notice that PromQL/MetricsQL is said to approximate the result for the spread.
So be VERY aware of this difference when evaluating VictoriaMetrics vs InfluxDB v2.
Concerning InfluxDB v1.8, Flux is (much?) less powerful and InfluxQL is ages behind, so no.
InfluxDB v3 Core (the free one) has no Flux anymore, I think, but offers SQL queries which can do that, but since I am afraid it will become paid or severely limited, I’m not going there.
For info, from Gemini v2.5 Pro, this is the SQL for InfluxDB v3 (untested!):
WITH
-- Step 1: Filter the data and aggregate it into hourly means, just like the first part of the Flux query.
hourly_means AS (
SELECT
date_bin('1 hour', "time") AS hourly_time,
AVG(_value) AS hourly_mean
FROM "€/kWh"
WHERE
"time" >= now() - interval '30 days' -- Example time range, adjust as needed
AND entity_id = 'current_electricity_market_price'
AND _field = 'value'
GROUP BY hourly_time
),
-- Step 2: For each hourly mean, determine its rank (1st, 2nd, 3rd, etc.) within its day,
-- both ascending and descending. This is how we find the Nth highest/lowest values.
daily_ranks AS (
SELECT
date_bin('1 day', hourly_time) AS day,
hourly_mean,
ROW_NUMBER() OVER(PARTITION BY date_bin('1 day', hourly_time) ORDER BY hourly_mean DESC) as rank_desc,
ROW_NUMBER() OVER(PARTITION BY date_bin('1 day', hourly_time) ORDER BY hourly_mean ASC) as rank_asc
FROM hourly_means
),
-- Step 3: Group by day and pivot the ranked values to calculate the spread for n=1, 2, and 3.
daily_spreads AS (
SELECT
day,
-- Spread n=1 (max - min)
(MAX(CASE WHEN rank_desc = 1 THEN hourly_mean END) - MAX(CASE WHEN rank_asc = 1 THEN hourly_mean END)) AS spread_1h,
-- Spread n=2 (2nd highest - 2nd lowest)
(MAX(CASE WHEN rank_desc = 2 THEN hourly_mean END) - MAX(CASE WHEN rank_asc = 2 THEN hourly_mean END)) AS spread_2h,
-- Spread n=3 (3rd highest - 3rd lowest)
(MAX(CASE WHEN rank_desc = 3 THEN hourly_mean END) - MAX(CASE WHEN rank_asc = 3 THEN hourly_mean END)) AS spread_3h
FROM daily_ranks
GROUP BY day
),
-- Step 4: Generate the cumulative histogram for each of the three spread calculations.
-- The HISTOGRAM table function is a powerful feature of InfluxDB v3 SQL.
hist_1h AS (SELECT le, "count" FROM TABLE(HISTOGRAM(TABLE daily_spreads, 'spread_1h', 0.0, 0.01, 30))),
hist_2h AS (SELECT le, "count" FROM TABLE(HISTOGRAM(TABLE daily_spreads, 'spread_2h', 0.0, 0.01, 30))),
hist_3h AS (SELECT le, "count" FROM TABLE(HISTOGRAM(TABLE daily_spreads, 'spread_3h', 0.0, 0.01, 30))),
-- Step 5: Invert each histogram. We calculate the total count for each series using a window function
-- (MAX("count") OVER()) and subtract the cumulative count from it.
inv_hist_1h AS (SELECT le, (MAX("count") OVER()) - "count" as value FROM hist_1h),
inv_hist_2h AS (SELECT le, (MAX("count") OVER()) - "count" as value FROM hist_2h),
inv_hist_3h AS (SELECT le, (MAX("count") OVER()) - "count" as value FROM hist_3h)
-- Step 6: Final SELECT. Join the three inverted histograms on their bin boundary ('le')
-- to pivot the data into the desired final shape.
SELECT
inv_hist_1h.le,
inv_hist_1h.value AS spread_1h,
inv_hist_2h.value AS spread_2h,
inv_hist_3h.value AS spread_3h
FROM inv_hist_1h
JOIN inv_hist_2h ON inv_hist_1h.le = inv_hist_2h.le
JOIN inv_hist_3h ON inv_hist_1h.le = inv_hist_3h.le
ORDER BY inv_hist_1h.le;