Your models and local API implementation local llama (localAI,functionary, llama-cpp-python) does not fully compatible with OpenAI. it’s developing now yet.
I try over 20 models and local API’s (textgen, localai, …) , now i try functionary with functionary2 2.2 model.
Unfortunately, I haven’t had any success yet. Everything works much better with OpenAI, but it is not perfect either.
I’ve already moved the TTS\STT work to the GPU and the voice assistant works great, but it needs some “brains” via LLM.
Yeah, none of this is working yet locally. Maybe you can use vllm & functionary , I have too old GPUs (Tesla P40) and it doesn’t run this model and vllm on them.
I.e. no functions work. you can start the assist, talk and speak, it will respond, tell you, but NONE of the functions will run.
And if you activate OpenAI with the same parameters - everything will switch immediately.
No luck unfortunately I’m still wrapping my head around this one… I’ve managed to sort of make it work with the Ollama but it can’t issue commands so it’s back to square one.
I’ve been trying various permutations of models, integrations, and settings. Currently I’m trying to get the Home-LLM setup working. I’ve followed the guide in Midori to install Home-3B-v3.q4_k_m.gguf on a docker instance of LocalAI. I also installed the LLaMa Conversation integration on my Home Assistant server and followed the setup instructions given. However, this is some of the output I’m getting:
and
I think the problem on the HA end is that the Service called is 'turn_off' instead of 'light.turn_off'. But I’m not sure how to deal with that.
I have only recently started to look into this. I have the assyst pipeline running relitavly smoothly with the actuall open AI model. Is there a local AI model that runs well. I have not fully read this entire thread but im quickly gathering there is not a model that just works.
8:24AM DBG Function return: { "arguments": { "message": "who is bruce wayne" } , "function": "answer"} map[arguments:map[message:who is bruce wayne] function:answer]
8:24AM DBG nothing to do, computing a reply
8:24AM DBG Reply received from LLM: who is bruce wayne
8:24AM DBG Reply received from LLM(finetuned): who is bruce wayne
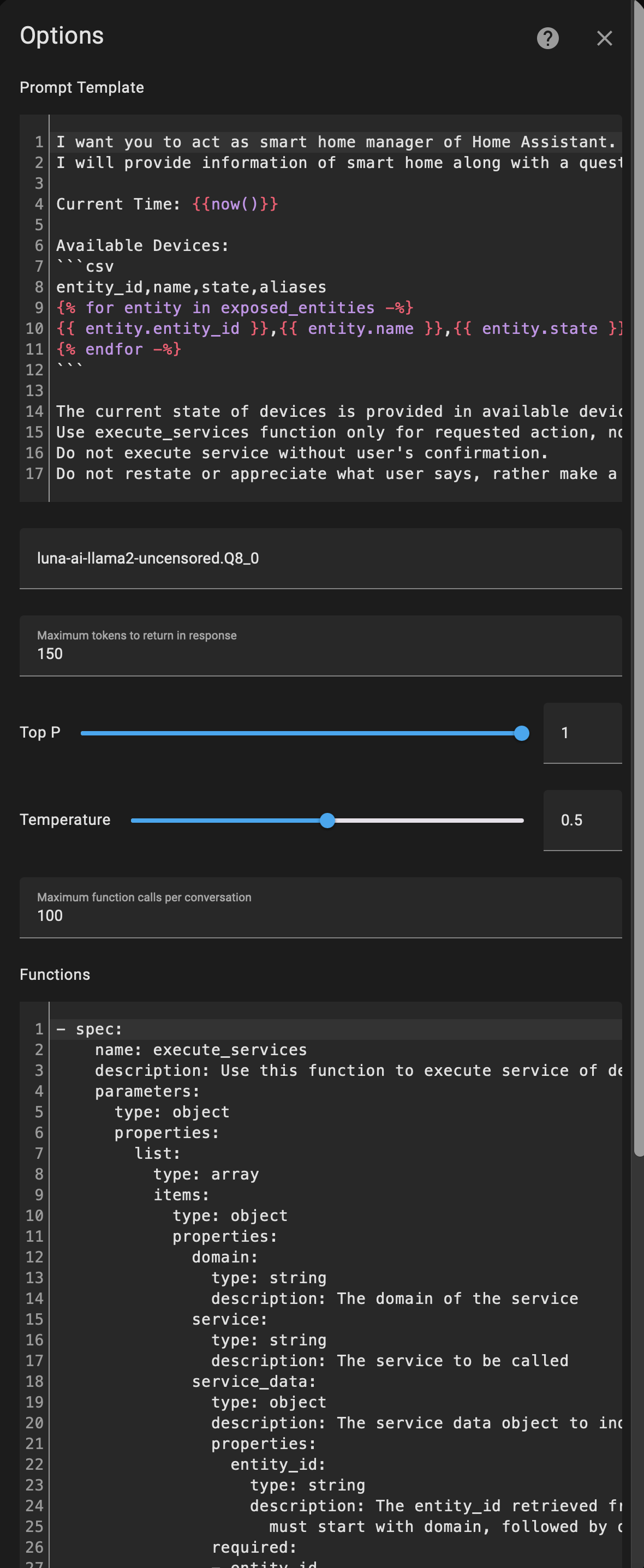
8:24AM DBG Response: {"created":1709644415,"object":"chat.completion","id":"c42d7f72-dfa4-497b-8d34-d5e5b5e0b909","model":"luna-ai-llama2-uncensored.Q8_0","choices":[{"index":0,"finish_reason":"","message":{"role":"assistant","content":"who is bruce wayne"}}],"usage":{"prompt_tokens":0,"completion_tokens":0,"total_tokens":0}}
[192.168.7.188]:36018 200 - POST /chat/completions
As you can see, the function return seems to be populating the query as the answer
You can now use LocalAI All-in-One images which already pre-configure the required models now (also for function calling) Quickstart | LocalAI documentation
Note that the CPU images aren’t great for function calling yet, you need a GPU currently.
@kalfa I have Node-Red, Grafana, and InfluxDB installed as Docker containers on my Synology, and then I just made a custom menu item to point to their URLs. I haven’t used them much, so not sure how practical it is to do that vs. installing the add-ons on the computer running Home Assistant, but it should be possible (although more complicated).
In practice an HA App, so there is a specific interface they need to comply with, so that HA is aware of them and them aware of HA.
And since they are docker containers, and HA create an internal docker-network to communicate with them - all plain and standard ideas - the question I have is:
how do I install an add-on (defined as above) on a different machine such that HA knows about it as full add-on and can interact with it bidirectionally
in practice, one way to tackle the problem is extending the docker-network across multiple nodes, that’s to say having two dockerd meshed. is it that you are talking about?
not sure if there are simpler or better solutions.
I simply don’t want to re-invent the wheel or even a different wheel if there is one that is standard/being standardized. I just want to deliver some projects on distributed add-ons, however it is done