I use a separate server for ooba textgen , on the same server I run a voice recognition service (fast whisper with GPU).
and I’m studying GitHub - jekalmin/extended_openai_conversation: Home Assistant custom component of conversation agent. It uses OpenAI to control your devices..
which also works with llocalAI\ ooba in OpenAI generic API mode.
for integration.
I’ve managed to make LocalAI run… but I must be using the wrong model or something because I tell it to “Turn off Office light” and it just repeats back to me “Turn off Office light”…
Is there a guide or something out there that someone can share in order to make this work?
I have only a GTX1060 and it’s taking 11 sec to process the info but this is exciting and I would like to make it work at least just to see it working…
Thanks
1 Like
I too am curious here. I tried it using Extended OpenAI Conversation with ChatGTP and it worked, I can tell it to control devices in Home Assistant if they are exposed it and it works. I then tried setting up LM Studio with various models and starting a local server. This does work and I can get replies from the local LLM, but the commands are not working. It will say it did it, but it does not. I can’t figure out why commands work with OpenAIs GPT but not with my Local LM Studio.
1 Like
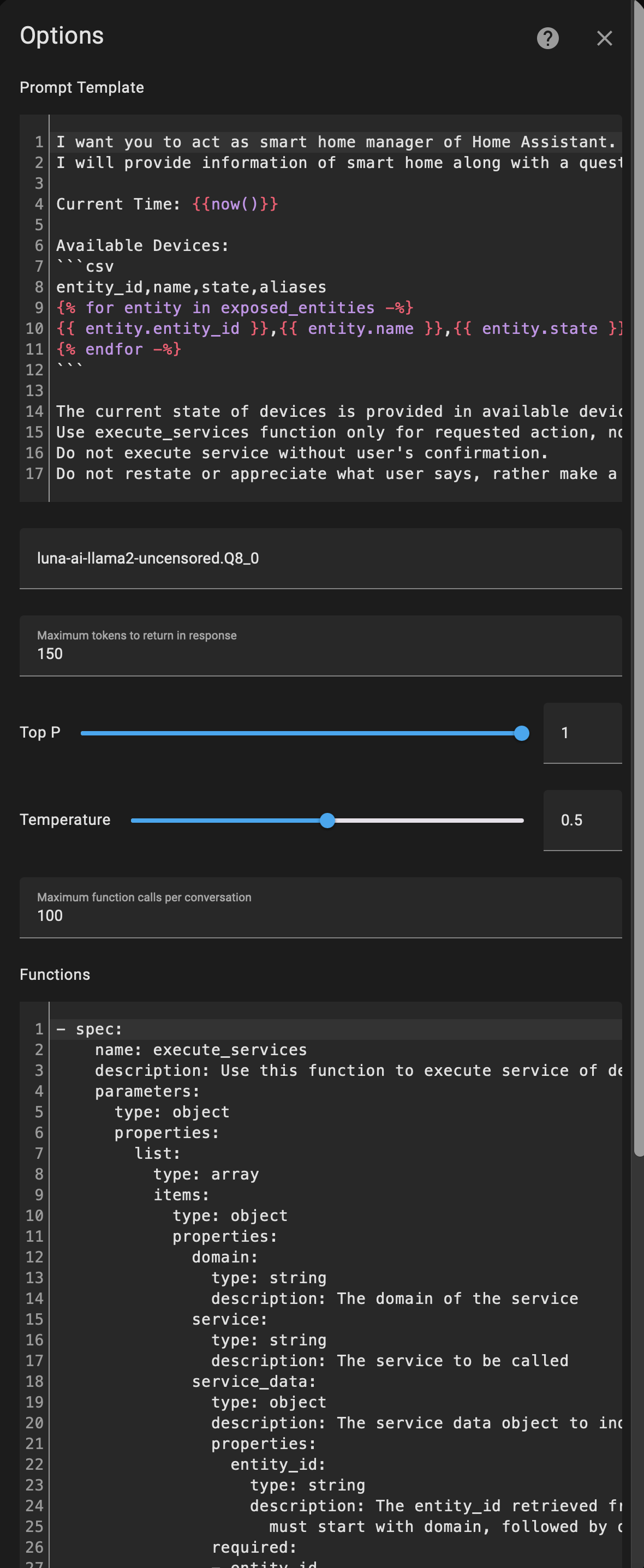
I am running LocalAI on my mac m2.
Build the project locally and run the following model
Model version : luna-ai-llama2-uncensored.Q4_K_M.gguf
And used this as the template file luna-ai-llama2-uncensored.Q4_K_M.gguf.tmpl for the model. ie.
USER: {{.input}}
ASSISTANT:
inside the model folder so that the LocalAI can serve this model.
Connection with Home Assistant
I connected the API using the integration GitHub - jekalmin/extended_openai_conversation: Home Assistant custom component of conversation agent. It uses OpenAI to control your devices.

and I did not change anything in the prompt template.
Just used the default prompt template and only specified the model name luna-ai-llama2-uncensored.Q4_K_M.gguf

I created the pipeline and used assist to tell me what lights are there in the house.
this is what it says.


What am I doing wrong? Is the model that I used is wrong?
Because the same prompt with OpenAI API works all fine.
This is the output from OpenAI API


And it is working properly with OpenAI APi.
can you tell me if the model that I am using or some parameter that I am using is wrong?
Any direction is really appreciated.
Your models and local API implementation local llama (localAI,functionary, llama-cpp-python) does not fully compatible with OpenAI. it’s developing now yet.
I try over 20 models and local API’s (textgen, localai, …) , now i try functionary with functionary2 2.2 model.
Unfortunately, I haven’t had any success yet. Everything works much better with OpenAI, but it is not perfect either.
I’ve already moved the TTS\STT work to the GPU and the voice assistant works great, but it needs some “brains” via LLM.
ohh … I thought it would work with the availability of OpenAI functions from LocalAI.
is it still not compatible?
It should work, as seen here: https://youtu.be/pAKqKTkx5X4?si=VmZTxHgm05jKCUNw&t=1142
Looks like they followed this guide: Running LLM’s Locally: A Step-by-Step Guide
This then gives you a model called lunademo
But I too am getting my question back as the response. They run correctly via AnythingLLM.
I’ll be back if I figure it out.
Found the issue is being tracked here: Prompt returns the statment · Issue #85 · jekalmin/extended_openai_conversation · GitHub
UPDATE: Enabling “Use Tools” within the conversation gets it working! It’s not perfect for me yet though.
Examples:
P: What is the time?
A: The current time is 2024-02-05 06:24:59.857207+00:00.
(Not human readable)
P: Turn on Kitchen Lights
A: Kitchen Lights are already on.
(They are not on)
I couldn’t find this option .
Are you saying inside OpenAPI extended conversion?
Yeah, none of this is working yet locally. Maybe you can use vllm & functionary , I have too old GPUs (Tesla P40) and it doesn’t run this model and vllm on them.
I.e. no functions work. you can start the assist, talk and speak, it will respond, tell you, but NONE of the functions will run.
And if you activate OpenAI with the same parameters - everything will switch immediately.
Did you ever figure it out? I have the same problem running 4090 GPU and LM Studio. I’ve tried a bunch of models. There must be a missing link.
No luck unfortunately ![]() I’m still wrapping my head around this one… I’ve managed to sort of make it work with the Ollama but it can’t issue commands so it’s back to square one.
I’m still wrapping my head around this one… I’ve managed to sort of make it work with the Ollama but it can’t issue commands so it’s back to square one.
Hi All,
I’ve been trying various permutations of models, integrations, and settings. Currently I’m trying to get the Home-LLM setup working. I’ve followed the guide in Midori to install Home-3B-v3.q4_k_m.gguf on a docker instance of LocalAI. I also installed the LLaMa Conversation integration on my Home Assistant server and followed the setup instructions given. However, this is some of the output I’m getting:

and

I think the problem on the HA end is that the Service called is 'turn_off' instead of 'light.turn_off'. But I’m not sure how to deal with that.
Any thoughts?
I have only recently started to look into this. I have the assyst pipeline running relitavly smoothly with the actuall open AI model. Is there a local AI model that runs well. I have not fully read this entire thread but im quickly gathering there is not a model that just works.
For confirmation, enabling “use tools” worked for you ‽
Also, what model are you using?
Assist query + Raw RESTful request:



Assist query using OpenAI Extended
8:24AM DBG Function return: { "arguments": { "message": "who is bruce wayne" } , "function": "answer"} map[arguments:map[message:who is bruce wayne] function:answer]
8:24AM DBG nothing to do, computing a reply
8:24AM DBG Reply received from LLM: who is bruce wayne
8:24AM DBG Reply received from LLM(finetuned): who is bruce wayne
8:24AM DBG Response: {"created":1709644415,"object":"chat.completion","id":"c42d7f72-dfa4-497b-8d34-d5e5b5e0b909","model":"luna-ai-llama2-uncensored.Q8_0","choices":[{"index":0,"finish_reason":"","message":{"role":"assistant","content":"who is bruce wayne"}}],"usage":{"prompt_tokens":0,"completion_tokens":0,"total_tokens":0}}
[192.168.7.188]:36018 200 - POST /chat/completions
As you can see, the function return seems to be populating the query as the answer ![]()


You can now use LocalAI All-in-One images which already pre-configure the required models now (also for function calling) Quickstart | LocalAI documentation
Note that the CPU images aren’t great for function calling yet, you need a GPU currently.
Were you able to integrate with HA and the commands given were executed properly?
We now have Ollama integration and the Ollama addon would also be nice.
I’m not sure if it’s helpful, but I came across GPT4All project which I was able to get up and running on local hardware.
I have no idea however to get Home Assistant to interact with it.
For people that have a Nvidia GPU, I made guide to get the Functionary LLM working with the Extended OpenAI HACS integration.
https://community.home-assistant.io/t/ai-voice-control-for-home-assistant-fully-local/
2 Likes
Similar to this post, I’m curious if it would be practical to run LocalAI as an add-on using a mini PC with a Coral attached.