Hi. Not that I know. I will let the profiler run again for a couple of days and see what that brings us.
Sorry to revive an oldish thread. I was wondering what the solution, if any, had been found. I am only a couple weeks into using Home Assistant and while trying to figure out why my system was slowing down and eventually becoming unresponsive, I found that I most likely have a memory leak. I too had the impression that the more Chrome tabs I forgot open the faster the issue happens. I setup system monitoring and can see a slow decline of free memory over time. Last 24hrs shown below:

I can try to follow some of the suggestions in this thread but I am still quite new is HASS and HA OS
I had to update an integration vua HACS and therefore restart HA Server. Free memory jumped up as shown below:

It is expected that after startup that caches are empty and it will take a few hours before all the expected data is loaded into memory.
The graphs you posted look like the caches are being built and then it stabilizes. It would help to see long term data if it continues to rise over time.
Once the caches are built you can use the profiler.start_log_objects service to watch the log for which objects are being created and not freed.
I’ve been trying to figure out a memory leak for days now. Just came across this profiler thread. I added the profiler and then ran the profiler.memory service. Here’s the the top of the output from the
hpy file:
.loader: _load_stat
.format: SetFormat
.timemade: 1645532553.304173
.count: 4151
.size: 499306
.kindname:
.kindheader: Referrers by Kind (class / dict of class)
.numrows: 186
.r: 1721 126002 dict (no owner)
.r: 158 101120 dict of async_upnp_client.utils.CaseInsensitiveDict
.r: 350 60528 function
.r: 15 14992 functools._lru_cache_wrapper
.r: 29 14368 types.CoroutineType
.r: 310 14002 tuple
.r: 11 12936 dict (no owner), dict of kasa.smartplug.SmartPlug
.r: 20 12800 sqlalchemy.orm.state.InstanceState
.r: 216 9864 asyncio.events.TimerHandle
.r: 62 9062 types.FrameType
.r: 96 8016 types.CellType
.r: 58 7888 asyncio.events.TimerHandle, types.CellType
I then restarted core and ran the service again to see where things would .loader: _load_stat
be on a fresh start. Here’s the top of that file output:
.loader: _load_stat
.format: SetFormat
.timemade: 1645533712.769792
.count: 2481
.size: 298258
.kindname:
.kindheader: Referrers by Kind (class / dict of class)
.numrows: 180
.r: 350 60528 function
.r: 320 31563 dict (no owner)
.r: 31 15352 types.CoroutineType
.r: 14 13842 functools._lru_cache_wrapper
.r: 306 13474 tuple
.r: 11 12936 dict (no owner), dict of kasa.smartplug.SmartPlug
.r: 20 12800 sqlalchemy.orm.state.InstanceState
.r: 241 10992 asyncio.events.TimerHandle
.r: 70 9336 types.FrameType
.r: 96 8016 types.CellType
.r: 58 7888 asyncio.events.TimerHandle, types.CellType
.r: 70 7680 dict of sqlalchemy.orm.state.InstanceState
I’m not using any upnp integrations. I know HA enables a bunch of stuff by default. Any idea how to disable whatever async_upnp_client.utils.CaseInsensitiveDict is associated with? After checking a second system I have it turns out it has the same counts for the upnp item. So I’m guessing that the “dict (no owner)” items are the problem as they are growing. Since they have “no owner” is this even helpful? Any other suggestion for stopping the leak would be appreciated. I’ve run HA for over a year without issue and it seems somewhere around the start of the new year this came into play. I am running HA supervised on Debian 11 as packaged by Armbian.
There was an issue related to ssdp which was included by the default_config. The developers fix appears to have been release in core-2022.3.3.
I’m suffering from a memory leak since updating to 2022.3.x. Currently on 2022.3.5.
Memory is still leaking.
I’m using a rpi3b, any assistance would be appreciated.
System Health
| Version | core-2022.3.5 |
|---|---|
| Installation Type | Home Assistant OS |
| Development | false |
| Supervisor | true |
| Docker | true |
| User | root |
| Virtual Environment | false |
| Python Version | 3.9.9 |
| Operating System Family | Linux |
| Operating System Version | 5.10.92-v7 |
| CPU Architecture | armv7l |
| Timezone | UTC |
The first thing I’d suggest you do, if you haven’t already done it is enable the “profiler” integration from the “Configuration → Devices & Services → Integrations → Add Integrations button”.
Once you have that installed you can restart your system. After it’s been up for 5 minutes go to the
“Developer Tools → Services” area. Then in the data field you can select profile.memory and run the service. This will dump a file in your home assistant directory. Then after the system had run for a few hours you run the memory profile again. Do it a few more times as your leak continues to grow. The dumped files are placed in your default home assistant directory. On my system that is /usr/share/hassio/homeassistant and the file name start with “heap”. Looking at the files in time order, you might notice a data item showing at the top of the list growing. There are a number of items that are not assocated with any specific process, but a lot of the names will give you an indication of a possible integration to look at. For me I notice an entry that I was associated with upnp. That lead me to the ssdp integration. I didn’t even know I had than enabled. Turns out it was enabled by default_config:
If you’ve been dealing with the leak for a while then I assume you’ve already spent a lot of times disabling and re-enabling the integration that were enabled as a result of building your system. So items that show up under “Configuration → Device & Services”. These are the heart of your working system. It’s possible that one of these integration is the problem. So you can try disabling an integration here using the triple dot menu at the bottom right corner of the integration. Disabled integration can later be re-enable from the button at the top left of this screen that shows you have disabled integrations.
The last thing I have to offer is that you should consider disabling default_config: from your configuration.yaml file. You just put a # at in front of default_config. If you disable this you would then manually enter all of the items that are included with default configure into your configuration.yaml file. That list is found here. The reason for doing this is then you can try disabling integration that are automatically included in the system. HA has multiple configured integration that look for new smart things on your network. If you’ve had your system up and running for a while you probably don’t need the system to continuously look for new things to add. Hopefully at some time the developers will add a button to the gui so you can disable/enable this feature without having to change the configuration. Anyway when you remove default_config you then replace it with something like this:
automation: !include automations.yaml
#automation manual: !include_dir_merge_list automations
cloud:
config:
counter:
#dhcp
#energy
frontend:
history:
image:
input_boolean: !include input_boolean.yaml
input_button:
input_datetime: !include input_datetime.yaml
input_number: !include input_number.yaml
input_select: !include input_select.yaml
input_text: !include input_text.yaml
logbook:
map:
media_source:
mobile_app:
my:
person:
#scene:
script: !include scripts.yaml
#ssdp:
stream:
sun:
system_health:
tag:
timer:
# deprecated updater:
#usb:
#webhook
#zeroconf:
zone:
The items above with the # are ones I’ve disabled from my system. zeroconf and sspd are the primary items that search for stuff on your network. ssdp was what caused my system to have to be rebooted every 2-3 days. That issue has since been fixed in ssdp, at least for me. I however keep these thing disabled as I don’t need aut discovery. If you disable energy, like I did, it removes the energy menu in the gui. I don’t have solar panels or anything that energy controls and so had no need for that capability. I also disabled usb as I don’t have anything plugged into the usb ports of my HA controller.
Watching my system I think it probably still has a very slow memory leak, but nothing like what I was having. The system had to be rebooted every other day when I had the major memory leak. I’ve been running on a 2G of memory system for over a year and as a result of the memory leak I have decided to get a 4G system. While I’m at home I restart HA pretty regularly because of the rate of software releases. The 4G memory is to ensure if I have a slow memory leak that the system stays up for at least a month.
Hope this helps.
2 Likes
It’s a recent leak, since updating to 2022.3.x
I’ll have a look at the profiler integration and see what’s what.
Thanks for the tip.
I may have solved it. Your mentioning the upnp integration reminded me that I had that installed. I disabled it and so far, memory usage seems to have settled down.
I’ll know more in a few days.
Edit:
1 day later and memory usage has settled down. It’s confirmed, at least on my system that something about upnp is to blame.
Hello together,
since I updated my HA to OS 7.5 I have a problem with memory. Everything was running fine bevore.
Can s.b. please help me to debug this?
Atm I make a restart every night at 3.00
Home Assistant 2023.2.2
Supervisor 2023.01.1
Operating System 9.5
Frontend 20230202.0 - latest
Running on Odroid N2+ with 4GB

Try the PROFILER.START_LOG_OBJECTS service. If you let it run for a hour and its a leak of python objects, the ones that are leaking should the be the only ones still growing in the log
@bdraco: Thank you! Today I made the update to newest version 2023.2.3 and will look further with PROFILER.START_LOG_OBJECTS service
I have updated from 2022.7 to 2023.2.2 and also seeing memory leak issue with my installation. After a few hours homeassistant is complete unresponsible because it uses all SWAP-Space.
Have to do some profiler work on it. Currently when we hit a switch, the corresponding light needs up to 40 seconds to toggle its status.
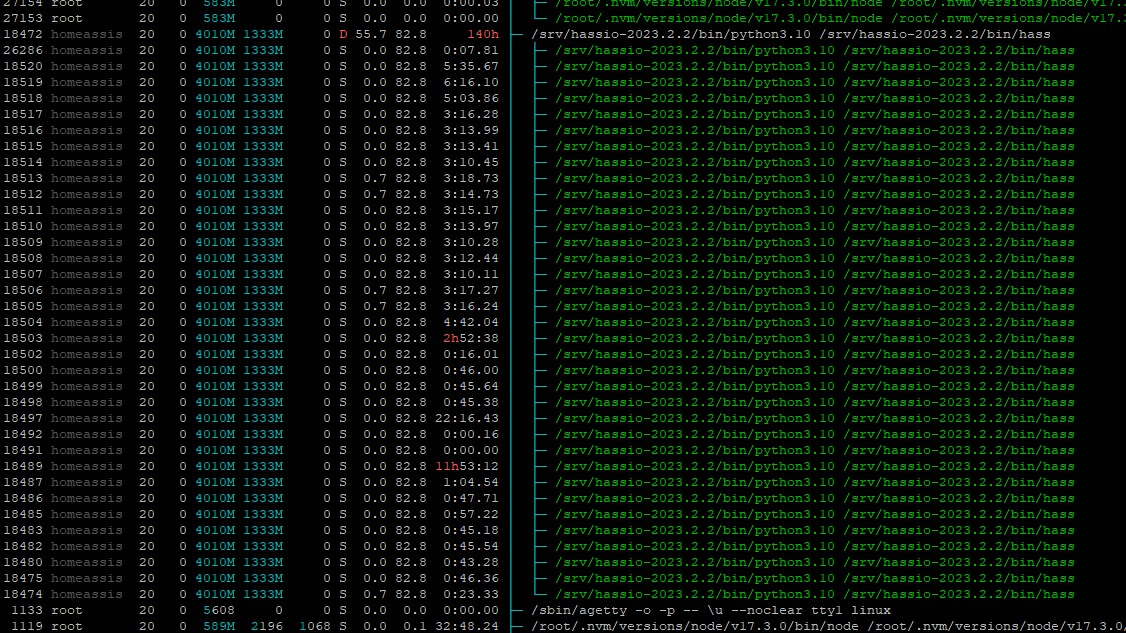
At least on my end it seems to be correlated to third party integrations. My advice would be disabling them all and adding them back one by one until you identify a culprit.
For me, it was the Wyoming Protocol integration that produced a memory leak. No matter how much RAM I allocated (up to 16GB in my proxmox setup), the memory always reached 95% utilization after a short period of time. By disabling the Wyoming Protocol integration, I was able to resolve the issue on my end. Now, my total memory consumption remains stable around ± 1GB.