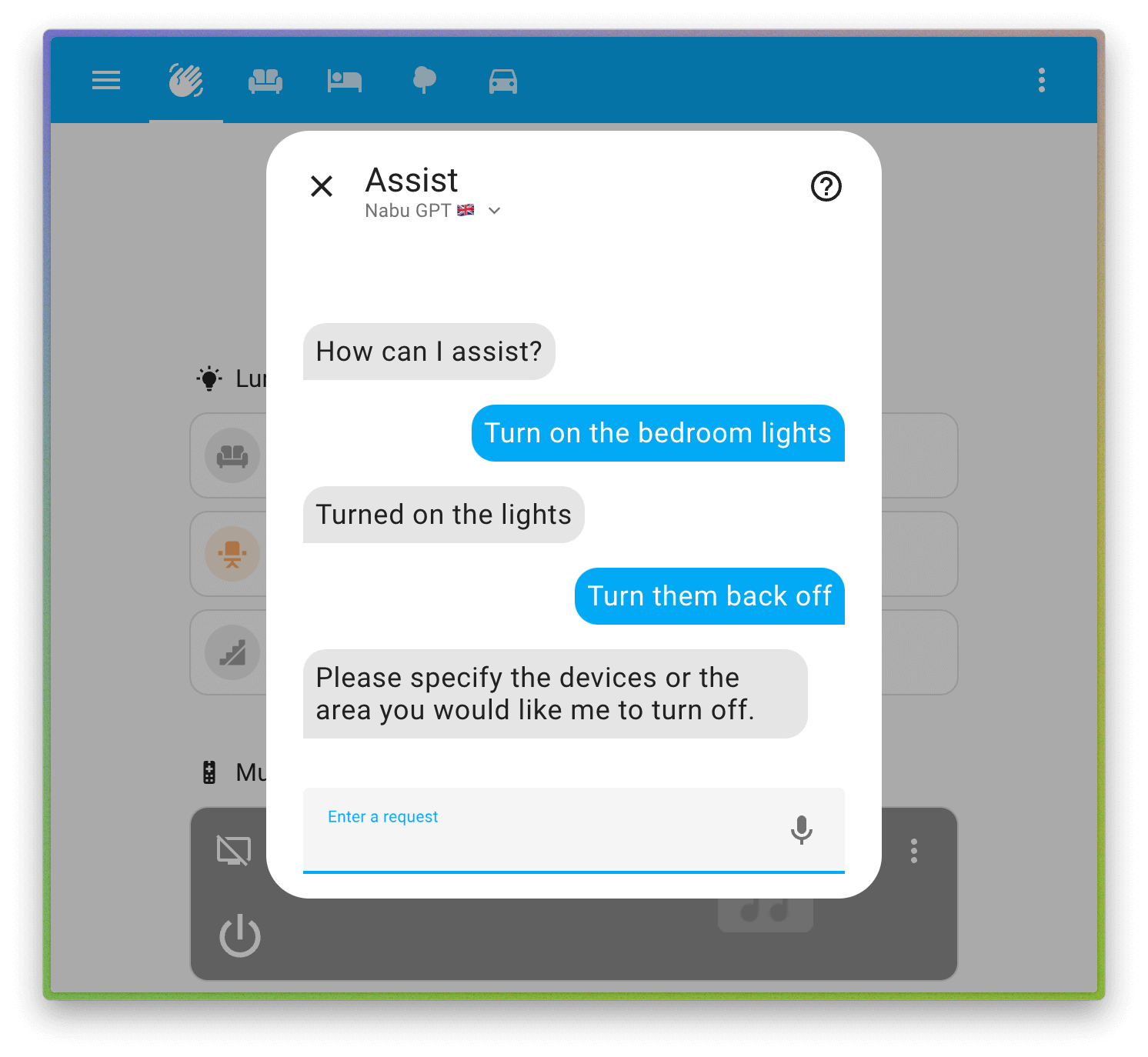
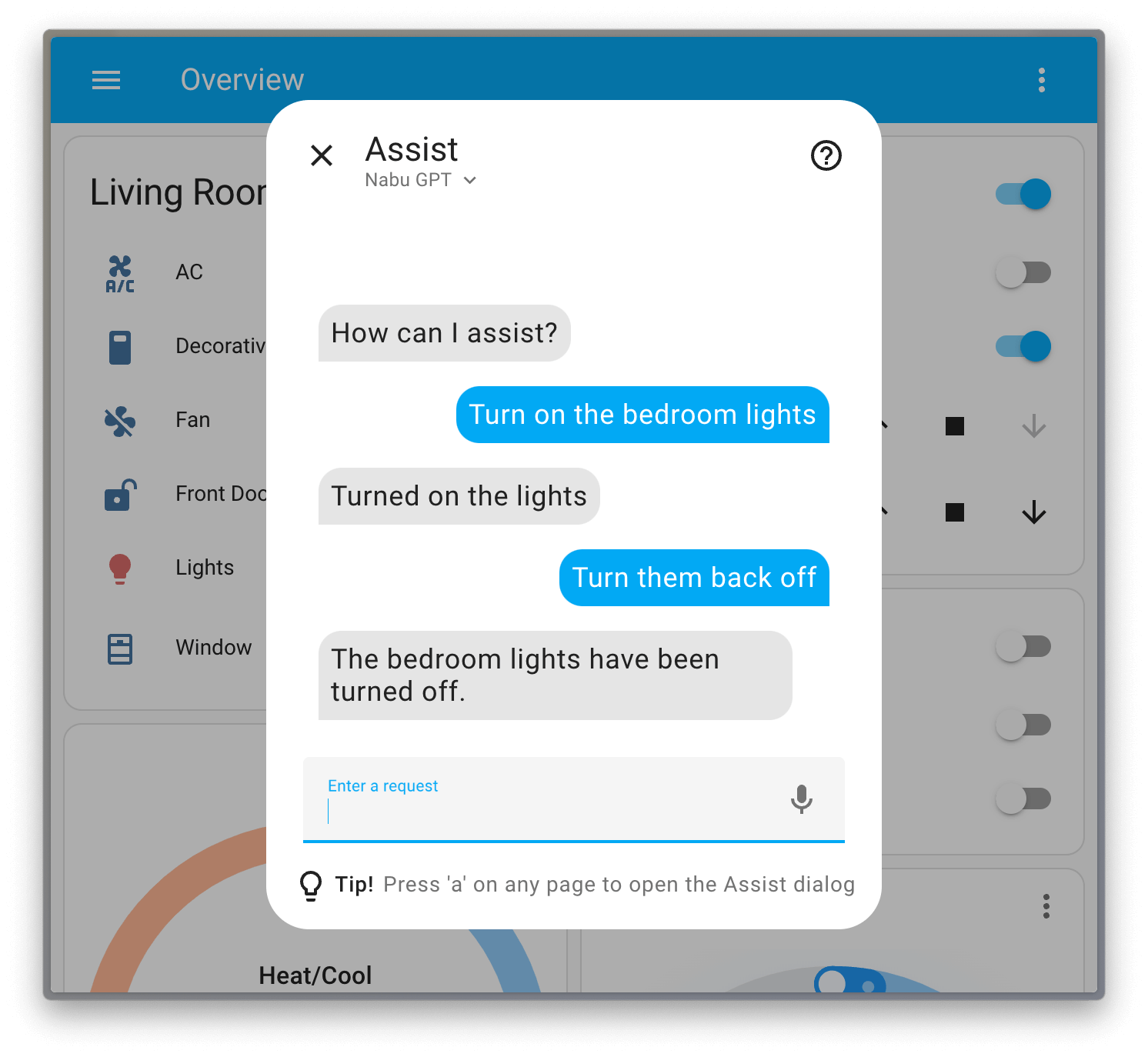
Well now with the launch of the official Home Assistant Voice Preview Edition there is another clear reason for more powerful hardware, it is officially stated that the Home Assistant Green (and Home Assistant Yellow) does not have powerful enough hardware to run the larger Whisper model for Assist locally.
This was also mention multiple times by Paulus, J-Lo and Mile in the video linked here as well as shown in the workflow diagram
”The N100 platform by Intel is our recommended hardware for local voice, that is like the bare-minimum.”
”If you are going to go local then we recommend out-of-the-gate something like an Intel N100 or better, especially for Whisper, if you have a graphics processor with a couple of gigs VRAM then you can get really fast large models that have high accuracy running.”
So if you run Home Assistent OS on hardware with a relativly slow CPU (like the Home Assistant Green) then for voice control you must off-load speech-to-text and text-to-speech to cloud services for it to be fast enough to be usable. If you want to run fully locally then you need a faster computer to run Home Assistent OS and the local Whisper piper on.
Note that they are here not even talking about LLMs for AI conversation agents but only the STT and TTS parts. It is the Whisper part, i.e. the Speech-To-Text parts that is usually the bottleneck for local voice control (without LLM). Meaning you will be dependet on the internet and cloud services for voice control if you do not have faster hardware to run everything locally.
Radxa Orion O6 mini-ITX motherboard that allow you to build your own ARM-based mini-PC looks like a a larger very flexible design with a theoretilcal 45 TOPS combined AI compute capability.
It is powered by Cix P1 12-core Armv9 SoC with core Armv9 processor with four Cortex-A720 cores clocked at 2.8 GHz, four Cortex-A720 cores at 2.4GHz, and four low-power Cortex-A520 cores clocked at 1.8 GHz. The Cix P1 SoC also features an Arm Immortalis-G720 GPU for graphics and AI computing, a 30 TOPS AI accelerator. It also features two M.2 socket with PCIe and a full PCIe x16 slot, plus more.
Thwy also plans to sell this board as part of a Radxa AI PC Development Kit with an enclosure some time next year and are already taking preorders.
The prerequisites have changed as you can now run the Deepseek R1 distill model locally on lower-end hardware, including the Nvidia Jetson Orin Nano SBC with only 16GB unified memory. Check out:
I keep getting excited about AI, but almost always realise it doesn’t do what I need.
Playing around with the new Gemini Models is fun, and they tend to be really great at creative stuff like writing stories or even crazy stuff like “create and alternate Ending for the Lord of the Rings”.
However, answering questions that requires some factual knowledge either get blocked completely (ask Gemini who us currently President of the US and it will decline to answer, suggestinf a Google Search instead) or the AI very confidently and adamantly gives you a completely wrong answer and then insists that it is correct.
Back to Home Assistant: having a Voice assistant in HA is nice, but that’s not something I need that much.
What would really be beneficial for me:
An AI “Assistant” that turns my ideas into working automations. That’s Level 1.
Level 2 would be specialized AI Micro Models that act as “dynamic algorithms” and can be tasked with controlling specific parts of your Smarthome.
Example: Tell the AI to keep the air in your home fresh. Assign entities to this specific AI Agent (CO2 Sensors, tVOC Sensors, Outdoor air quality, temperature etc and of course the control of the Ventilation system and it’s Powe Consumption) and the AI would then use the available data and controls to do it’s job. So instead of having a fixed Algorithm and trying to cover as many variables as possible, have your little AI Butler deal with it.
Level 3 would be something like “Sara” from the TV Show “Eureka”. A central AI that controls everything and is intelligent enough to figure out how to best solve various problems. This Level is not very realistic right now😁
Bonus Level:
Use a System Level, specialized AI to monitor the state of the HA Server and Entities. Unfortunately things break in a system as complex as HA, and having a little Watchdog that noticed that an Addon or Integration hasn’t been running properly and informs you (in case it can’t figure out the issue itself) would be reall helpful.
Yeah but that is not the main use case for wanting to use AI with Home Assistant’s Assist, instead the main use case is simply to control your devices or help create automations with natural language and keeping context continously, meaning truely make a smart home platform, as for example described in this new feature to keep conext during conversation that switch between intent engine and an LLM added to the new Home Assistant 2025.2 release under the topic ”SHARED HISTORY BETWEEN THE DEFAULT CONVERSATION AGENT AND ITS LLM-BASED FALLBACK”:
SHARED HISTORY BETWEEN THE DEFAULT CONVERSATION AGENT AND ITS LLM-BASED FALLBACK
In 2024.12 we introduced a lovely feature that allowed you to use our fast and local default conversation agent for most queries while still being able to fall back to a much more powerful LLM-based agent for more complex queries.
This introduced some interesting behaviors. From a user perspective, it looked like you were talking to the same assistant, whereas, in reality, nothing was shared between the two agents. This led to some less-than-optimal scenarios, such as this one:
The first command is processed locally by our default agent, but the follow-up request is processed by the LLM-based agent. Since no memory is shared, it does not understand what device you want to turn off.
Starting with this release, both agents now share the same command history, helping address this issue.
There are of couse also many other great use cases for local AI whhere you probably do not want to upload your data to the cloud, where just one example this custom AI automation suggester integration component:
Now back on-topic to local embedded AI accelerator hardware.
I tried that Automation suggester a while back but deleted it again after a while. It didn’t really offer anything useful for me.
As to embedded Hardware…Gemini suggested the Jetson Nano but also suggested waiting for upcoming Hardware.
Maybe HA/Nabu will launch something in cooperation with Nvidia. Or some ultra-efficient ARM NPU will show up.
For me, the main issue is idle power consumption. I have a Gaming PC with a 4080 Super that could probably run some local AI stuff, but having it on 24/7 when it only needs to handle a few requests a day at most would just be wasting electricity since it idles around 60Watts minimum.
By the way; I also think that LLM agent(s) that have all Home Assistant data and can reason and thus unlock the reasoning ability of LLMs within its context could become the next great leap for true “smart home” automation. As described in this blog post by Paulus Schoutsen (Home Assistant’s founder):
In summery LLM agents are advanced AI systems designed for creating complex text that needs sequential reasoning. They can think ahead, remember past conversations, and use different tools to adjust their responses based on the situation and style needed.
FYI, only the most powerful of Nvidia’s Jetson modules can use up to 60Watt/h, while most of their modules uses much less, such as for example Nvidia’s Jetson Orin Nano Super Developer Kit which at most uses 25Watt/h (and at ideal uses only around 7Watt/h). Check out his chart:
Having it be a dedicated stand-alone appliance could mean that it will probably be pre-configured to use less power when idle and only draw more power on-demand in bursts when it is actually computing AI stuff.
Brad btw also had other use cases other than just home automation, like example (I am paraphrasing):
Local LLM that could talk to about private stuff (i.e. private conversations with context).
Tracking people’s faces and motion detection in cameras.
Have an AI (LLM agent) that have all data from Home Assistant and can help you write and improve automations in YAML.
Upload photos to it and have it even adjust photos
You could upload financial documents to it and have a conversation with it about how to optimize your taxes right it’s usually a personal conversation where you would hire a professional it’s very expensive to have, or legal advice.
He referered the concept on of such dedicated stand-alone local AI/LLM network-attached appliance-like AI-box products as “ChatGPT in a box” (and the industry calls it on-premies “Edge AI”), so recommend check out all of his comments and related ideas starting after the 17:00 timestamp:
Thanks. Great comment! The Jetson stuff is definitely interesting, but I am hoping that we will see more variety soon-ish when it comes to local LLM Servers.
For now I will experiment with running an Ollama Server on my Gaming PC and see what kind of Performance it yields. This would just be an experiment though, due to the high idle power draw of my PC.
I installed Ollama on it yesterday, but couldn’t figure out how to make HA Ollama Client access it. I think I found the answer to that today, but didn’t have time to test it yet.
Ok…so I got my local LLM running on my Gaming PC. Downloaded llama3.2 and it works quite smoothly. Sadly it’s also extremely limited, but as a first test it was OK.
Now I need to find a model that actually works well with Home Assistant…
I am looking at this sort of thread.
Selling an item MUST be profitable. It must appeal to a wide audience. It must be easy to implement and support.
From the way I see it, only a small number of Home Assistant users care to run experimental stuff and LLM’s locally. This is not what majority of people just wanting motion controlled lights or to turn their heater on and off would want.
Now I am a tinkerer. I am a nerd. I love the high end, experimental stuff. I just don’t see how something high end would be economically viable to Nabu Casa, who ultimately needs to make money to pay staff to do the software development for a program they give out for free. Nabu Casa survive on the Home Assistant Cloud, and the odd main stream style hardware components they sell. Deveopment, support, approvals and all that stuff need to be done for every piece of hardware they create, especially if the hardware has radios in it. It literally took years to develop and get the Home Assistant Yellow fully approved for world wide sales.
I agree, would be nice to see Nabu Casa cater for all the different people with custom hardware, but the reality is a mini PC, that costs 1/4 the amount of proprietary hardware and is 100% reliable and currently supported, would be more beneficial for most experimental stuff. Not to mention your mini PC would be more powerful than any “Green Plus / Max” hardware option. It just is not economically viable for a company to support every niche use case with custom hardware.
I’d rather see the focus on the development of Home Assistant as a software package than to see energy put into niche hardware that will be very low volume sales
FYI, Orange Pi just announced their ”Orange Pi AI Station” single-board computer based on an Ascend 310 series processor with 16 CPU-cores and the initial SBC model designed for either 48GB or 96GB of RAM soldered to the board:
Bad timing now that RAM-prices are going up lile crazy, but something like this might be a good as an all-in-one appliance platform a couple of years from now if RAM price has gone down by then, or?






")