I’ve a Proxmox Server, version 8, CPU N100, 16Go in a small mini-pc; i’m running HA in a VM with 2vCPU and 4Gb memory. when I installed Whisper as an add-on module in HA, performance was not at all up to scratch (more than 10 seconds waiting for processing, and a CPU running amok). I’ve tested several conf and never improved performance.
I decided, and thanks to your various conf, to use Whisper on an LXC in my Proxmox. More specifically, I’ve created an LXC (2 vCPU and 8Gb) containing Docker, and I’ve set up the following configuration:
Hi,
At the moment I’m having Hass installed on a virtual machine on my Synology nas.
I‘d like to use the local voice assistant with whisper. My system is not fast enough for processing whisper. Now I’m thinking of getting a Nuc for this topic. Do you thin a nuc with a celeron processor would be enough for this? I read in the official documentation that a nuc processes voice commands in under 1s while a raspi4 takes 4-8 seconds.
Or do I really need crazy gpu for fast processing?
It depends on your definition of fast enough. In my experience that I detailed above, I was not able to get whisper on CPU running fast enough (which for me would be in real time). It always had a noticeable processing delay. You don’t need a crazy GPU though, I used an old GTX 1650 which has made all the difference.
As Rodney says, what is your definition of fast enough ?
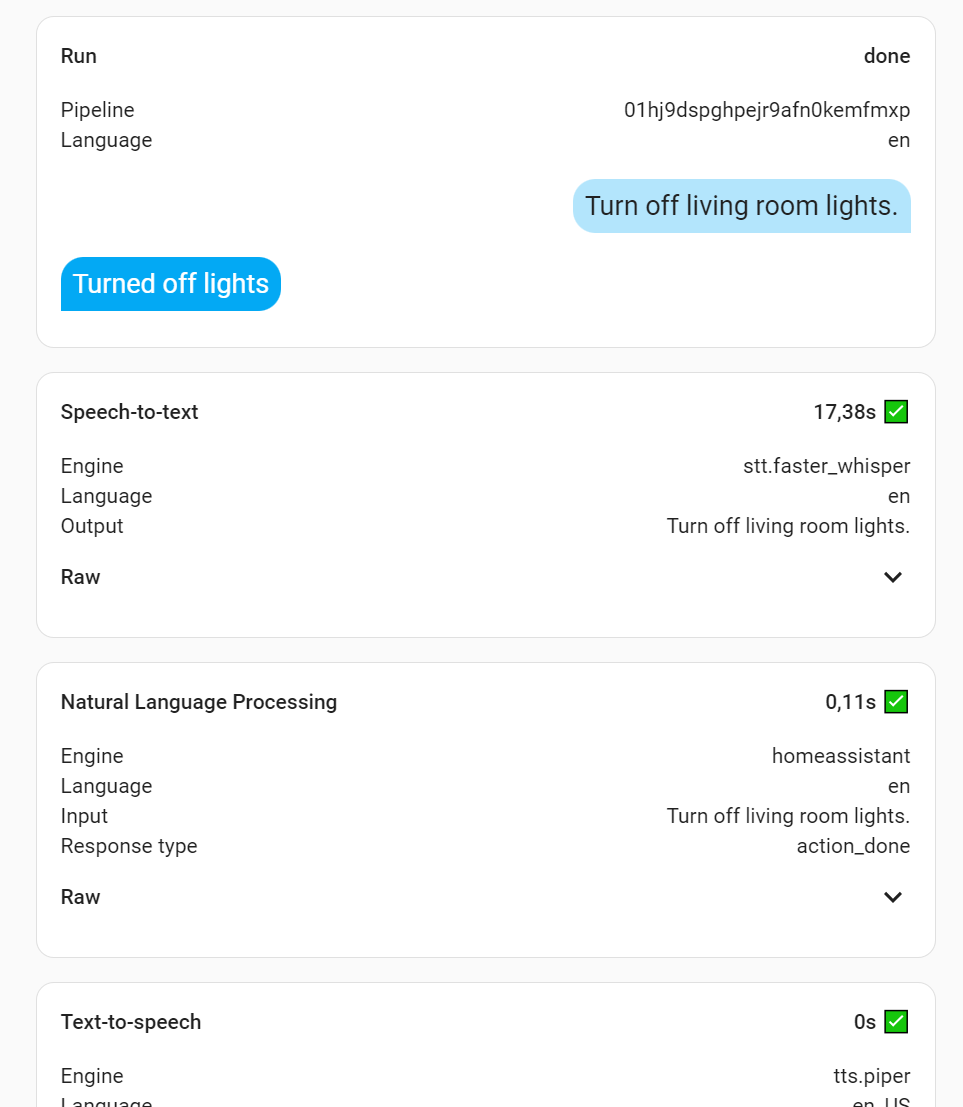
I run HA as the only VM on a Intel i5-7500T based tiny PC which i bought used from ebay. With 2 CPU cores and 8GB RAM allocated to the VM I am able to run the medium-int8 (largest) Whisper model which has improved accuracy (in English) to an acceptable level. As for speed … it is the 15 second delay (VAD) before starting to process which annoys the heck out of me.
It comes down to the old trade-off … cost versus speed. Spending a bit more now will give you a machine which should satisfy your needs for longer.
Also … many businesses upgrade all their PCs every 3-5 years, dumping plenty of fairly new PCs on ebay - like my Dell Optiplex 7050 micro (very small case and low power requirement) - as an alternative to a new NUC.
Thank you for your responses.
Just read that in the documentation:
The speech-to-text option is [Whisper]. It’s an open source AI model that supports [various languages]). We use a forked version called [faster-whisper]. On a Raspberry Pi 4, it takes around 8 seconds to process incoming voice commands. On an Intel NUC it is done in under a second
So I‘m a bit confused about 15 seconds you tell
As far as I understand the local processing the whisper speech2text will be the most complicated one. So within under 1 second of processing the light should be switched off 2 seconds after my voice commands end. Or am I wrong here?
I think that processing speed depends very much more on whether it’s an intel Celeron or an intel i9 that is inside, than whether its a NUC box
You say the wakeword, pause, then speak the command which is passed to Whisper. Whisper continues listening for 15 seconds after you finish speaking (to make sure it has heard all of your command), and then does its processing and passes the text command to HA. To me this 15 seconds of Voice Activity Detection (VAD) seems overly long. I am confident there is an option to control this, which is just currently not exposed through the UI.
I read your comment about the 15 seconds. I’m running Home Assistant in Proxmox on an NUC 11 i5, and I experienced the same. Once I stop talking, the Atom Echo started blinking faster, then it would take approximately 15 seconds, and then it would execute the command. Those seconds were the reason I was considering setting up Whisper on an external machine after all.
Just a heads up for those of you running a VM HA-instance: Double check that you have the avx -instruction sets enabled for your home assistant VM. This will have a huge impact on inference times.
I’m using Proxmox and by enabling x86-64_v3 for the HA vm, I got the “small” model (and not even the int8 variety) to run with 3-4s delay for most prompts whereas before it would always timeout.
I followed that suggestion, logged into ProxMox, turned off the VM, changed CPU type to x86-64_v3 in the Home Assistant VM, and turned the VM back on. And guess what? The 15 seconds between recognizing I’d stopped talking and executing the command, now is more like 1-2 seconds. (Tiny-int8).
I don’t know if you’re using Proxmox or some other VM, but those 15 seconds annoying you sounds a bit like we had the same issue. If that is so, I may just have found (someone who had found) that option you were talking about. Only, it was in the virtual machine setup.
HI Voltie, Thank you for pointing this out; I had not seen it.
I am indeed running HAOS in a VM under Proxmox. Mine is a used Dell OptiPlex 7050 micro business PC with Intel i5-7500T CPU, running Proxmox Virtual Environment 7.4-16
I currently have only one VM configured - Home Assistant OS package from GitHub - tteck/Proxmox: Proxmox VE Helper-Scripts - so giving it 16GB and all 4 cores from the i5 CPU.
HAOS VM Processor is set to “host”, and I do not see any “x86-64” CPU type or “avx-instruction sets” option for the VM, or Proxmox.
Ahhh, there are updates waiting to install … nope, that didn’t make any change.
Maybe the avx-instruction set is considered automatic in the later generations of CPUs ? Whatever … but thanks for pointing it out
For anyone who is using Proxmox and who does not want to use Docker, it is possible to run the Whisper add-on in a container or VM if you have another more powerful node. I just got whisper up and running in a container on another machine, with GPU passthrough and now my Assistant responds faster to commands than Google. Used to have to wait about 2-3 seconds for the command to be executed, now it feels immediate.
the tiny-int8 model on the j4205 (the main mini pc with proxmox&HA) in the docker handles recognition in a 4-7 seconds. But there are a lot of mistakes in complex words.
I launched a whisper on gtx1070 (host with debian) according to the instructions from the previous post. The medium-int8 model performs identical tasks in half a second. Almost error-free.
As for power consumption, this 1070 card consumes 20 W at idle (аnother 10 consumes CPU, memory, disk…).
In my opinion, the last problem remains the sensitivity of the microphone on the esp32. The experience of using it does not compare with proprietary solutions that can hear your whisper at a great distance.
I located the setting in Proxmox 8.0.4 and then 8.1.3.
This may or may not help you, but I found the setting to change the CPU here:
Proxmox VE Web UI > Virtual Machine > (Machine name) > Hardware > Processors (click to change) > type or scroll to find the X86-64-v* line.
I don’t know if the list of CPUs change if you change the “Machine” setting, mine is set to q35 (which I read somewhere I should for some other hardware passthrough stuff).
Edit: I tested on a VM that’s not set to q35, and it still had the same processor type options. I also looked up which Intel processors supports X86-64-V3 and AVX, and as far as I can tell, your i5-7xxx should be supported. I think it’d be supported as far back as i3-4xxx. So it may just be a case of finding this setting in Proxmox 7. (Hopefully not too different from what I showed you in Proxmox 8.)
Not sure where you got Q35 from … I guess “NUC 11 i5” means its a low power computer with 11th gen i5 CPU ?
I did check my VM settings, but there is no x86 option, and I assumed that “host” would reduce the chance of proxmox doing unexpected emulation translations.
Maybe after tomorrows next chapter of HA Voice i’ll be motivated to have another look at it. In the meantime, Rhasspy is still working for the rest of my home.
I really only use voice (Alexa) to run Good Night/Good Morning scripts from the bedroom echo but I could do that with a Zigbee button on the nightstand, and to turn lights off/on. When I arrive home the garage echo asks if I want her to close the garage door but I could just press the button on my car’s visor or the pad by the door into the house. I sometimes play Spotify via their Windows app on my office echo dot stereo pair which I can’t emulate in HA plus why do I need to? I just spent the evening trying in vain to get HA Music Assistant integration to play music via the only available media player it presented which is my LG WebOS TV, which turns on/off and selects sources just fine from HA but no music. I sometimes have questions for Alexa which I don’t think Assist could answer. That $200 for just the GPU could buy me better sounding echos for the office, and then there’s the cost of a Core i5 plus new speakers, and microphones! I think I just convinced myself that HA Assist is not worth it for me…
< end of rant >
Oh, and while I’m at it, I have an Echo Wall Clock that’s only ever used as a wall clock but chews up 2 to 3 sets of 4xAA batteries annually. It keeps accurate time but so do my Atomic clocks which only use 1xAA battery every 12+ to 18 months…
Fair enough. The quality of Alexa and Google devices is (so I understand) far superior to any of the current alternatives. And HA Voice Assist is still being developed, so there are a number of features still to be added.
The reason some of us are enthusiastic about HA Voice Assist is that it does NOT rely on servers owned and operated by multinational companies out of your control.
We accept that it’s not there yet, but check back in 6 or 12 months…
Don’t get me wrong, HA Voice Assist is exciting and I’ll continue to keep tabs on it but it’s just not there yet, for me and my use cases. I bought a Muse Luxe speaker for Voice Assist but it was a major disappointment/failure. Maybe one day Nabu Casa cloud can replace Alexa/Google cloud services thus eliminating the need for expensive local hardware for voice analysis, but they are currently free (although that could change any day now) and Nabu is not. At CA$8.70/month, that’s two fancy coffees at Starbucks!
Hi everyone, I’ve also tried to run the language assistant backend on external servers. I am trying to use a webbased server, though, outside my home network an in a data center. I have read through this thread but have not stumbled upon anyone doing this - or did I miss something?
Either way, I am getting very slow response times on stt and was wondering if any of you have any idea on how to fix this?