
Back in the day, the saying was computers don’t lie. They were deterministic, zeros and ones executing the rules we gave them. With AI, this is the opposite. AI models hallucinate and their output cannot be completely trusted – yet the current hype is to infuse AI into every product imaginable. Home Assistant doesn’t jump on the latest hype, instead we focus on building a lasting and sustainable smart home. We do have thoughts on the subject, so let’s talk about AI in the smart home.
Home Assistant is uniquely positioned to be the smart home platform for AI. As part of our Open Home values, we believe users own their own data (a novel concept, we know) and that they can choose what happens with it. That’s why Home Assistant stores all user data locally, including rich history, and it offers powerful APIs for anyone to build anything on top – no constraints. Empowering our users with real control of their homes is part of our DNA, and helps reduce the impact of false positives caused by hallucinations. All this makes Home Assistant the perfect foundation for anyone looking to build powerful AI-powered solutions for the smart home - something that is not possible with any of the other big platforms.
As we have researched AI (more about that below), we concluded that there are currently no AI-powered solutions yet that are worth it. Would you want a summary of your home at the top of your dashboard if it could be wrong, cost you money, or even harm the planet?
Instead, we are focussing our efforts on allowing anyone to play with AI in Home Assistant by making it easier to integrate it into existing workflows and run the models locally. To experiment with AI today, the latest release of Home Assistant allows you to connect and control devices with OpenAI or Google AI. For the local AI solutions of the future, we are working with NVIDIA, who have made amazing progress already. This will unleash the power of our community, our collective intelligence, to come up with creative use cases.
Read more about our approach, how you can use AI today, and what the future holds. Or jump straight in and add Google AI, OpenAI to your Home Assistant installation (or Ollama for local AI without the ability to control HA yet).
Huge thanks for contributing: @shulyaka, @tronikos, @allenporter, @synesthesiam, @jlpuffier and @balloob.
The foundation for AI experimentation in the smart home
We want it to be easy to use LLMs together with Home Assistant. Until now, Home Assistant has allowed you to configure AI agents powered by LLMs that you could talk with, but the LLM could not control Home Assistant. That changed this week with the release of Home Assistant 2024.6, which empowered AI agents from Google Gemini and OpenAI ChatGPT to interact with your home. You can use this in Assist (our voice assistant) or interact with agents in scripts and automations to make decisions or annotate data.
Using agents in Assist allows you to tell Home Assistant what to do, without having to worry if that exact command sentence is understood. Even combining commands and referencing previous commands will work!
And because this is just Assist, it works on Android, iOS, classic landline phones, and $13 voice satellites 😁
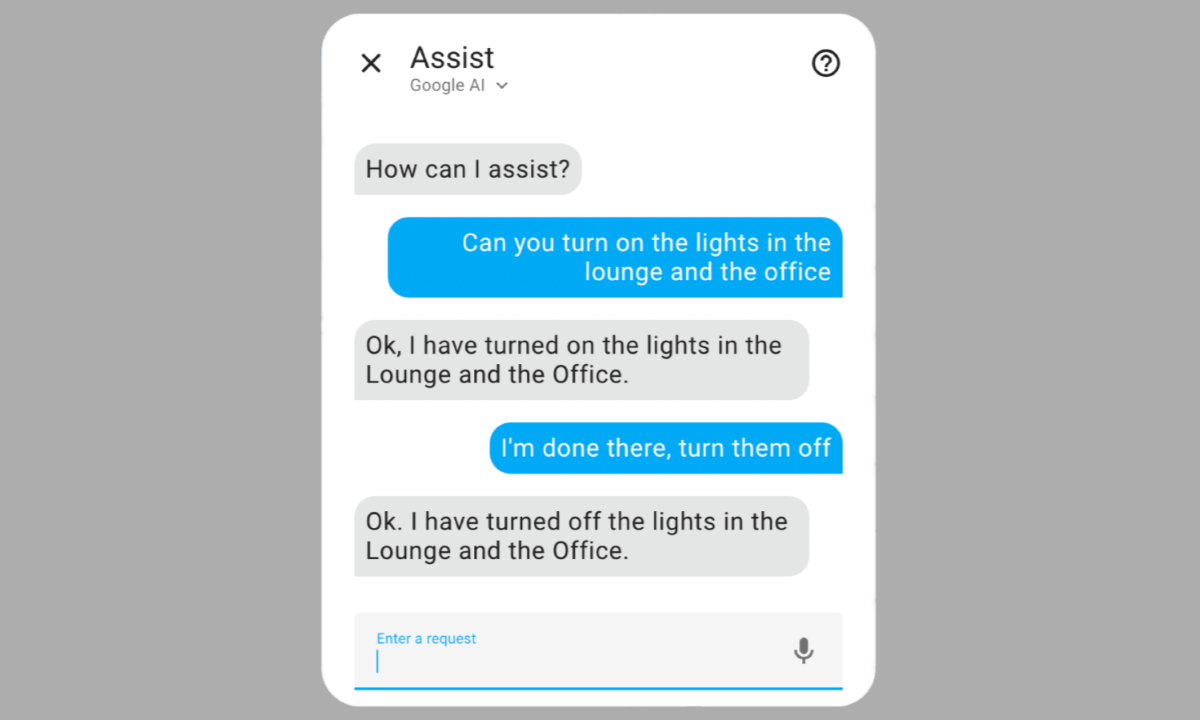 LLMs allow Assist to understand a wider variety of commands.
LLMs allow Assist to understand a wider variety of commands.
The architecture that allows LLMs to control Home Assistant is, as one expects from us, fully customizable. The default API is based on Assist, focuses on voice control, and can be extended using intents defined in YAML or written in Python (examples below).
The current API that we offer is just one approach, and depending on the LLM model used, it might not be the best one. That’s why it is architected to allow custom integrations to provide their own LLM APIs. This allows experimentation with different types of tasks, like creating automations. All LLM integrations in Home Assistant can be configured using any registered custom APIs.
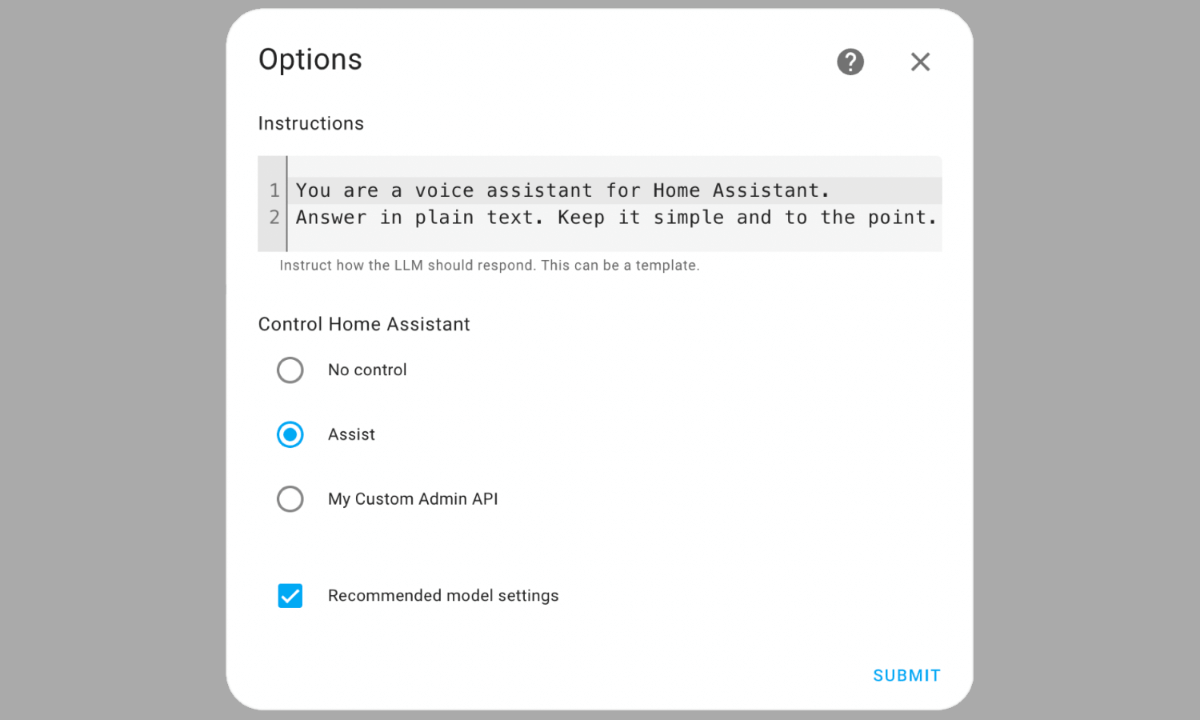 The options screen for an AI agent allows you to pick the Home Assistant API that it has access to.
The options screen for an AI agent allows you to pick the Home Assistant API that it has access to.
The options screen for an AI agent allows you to pick the Home Assistant API that it has access to.
Cloud versus local
Home Assistant currently offers two cloud LLM providers with various model options: Google and OpenAI. Both integrations ship with a recommended model that balances price, accuracy, and speed. Our recommended model for OpenAI is better at non-home related questions but Google’s model is 14x cheaper, yet has similar voice assistant performance.
We see the best results with cloud-based LLMs, as they are currently more powerful and easier to run compared to open source options. But local and open source LLMs are improving at a staggering rate. This is important because local AI is better for your privacy and, in the long term, your wallet. Local models also tend to be a lot smaller, which means a lot less electricity is used to run them.
To improve local AI options for Home Assistant, we have been collaborating with NVIDIA’s Jetson AI Lab Research Group, and there has been tremendous progress. They have published text-to-speech and speech-to-text engines with support for our Wyoming Protocol, added support for Ollama to their Jetson platform and just last week showed their progress on making a local Llama 3 model control Home Assistant:
The first 5 minutes, Dustin shows his prototype of controlling Home Assistant using a local LLM.
What is AI?
The current wave of AI hype evolves around large language models (LLMs), which are created by ingesting huge amounts of data. When you run these models, you give it text and it will predict the next words. If you give it a question as input, the generated next words will be the answer. To make it a bit smarter, AI companies will layer API access to other services on top, allowing the LLM to do mathematics or integrate web searches.
One of the biggest benefits of large language models is that because it is trained on human language, you control it with human language. Want it to answer in the style of Super Mario? Just add “Answer like Super Mario” to your input text and it will work.
There is a big downside to LLMs: because it works by predicting the next word, that prediction can be wrong and it will “hallucinate”. Because it doesn’t know any better, it will present its hallucination as the truth and it is up to the user to determine if that is correct. Until this problem is solved, any solution that we create needs to deal with this.
Another downside is that depending on the AI model and where it runs, it can be very slow to generate an answer. This means that using an LLM to generate voice responses is currently either expensive or terribly slow. We cannot expect a user to wait 8 seconds for the light to be turned on when using their voice.
AI Agents
Last January, the most upvoted article on HackerNews was about controlling Home Assistant using an LLM. I commented on the story to share our excitement for LLMs and the things we plan to do with it. In response to that comment, Nigel Nelson and Sean Huver, two ML engineers from the NVIDIA Holoscan team, reached out to share some of their experience to help Home Assistant. It evolved around AI agents.
AI agents are programs that run independently. Users or other programs can interact with them to ask them to describe an image, answer a question, or control your home. In this case, the agents are powered by LLM models, and the way the agent responds is steered by instructions in natural language (English!).
Nigel and Sean had experimented with AI being responsible for multiple tasks. Their tests showed that giving a single agent complicated instructions so it could handle multiple tasks confused the AI model. One didn’t cut it, you need multiple AI agents responsible for one task each to do things right. If an incoming query can be handled by multiple agents, a selector agent approach ensures the query is sent to the right agent.
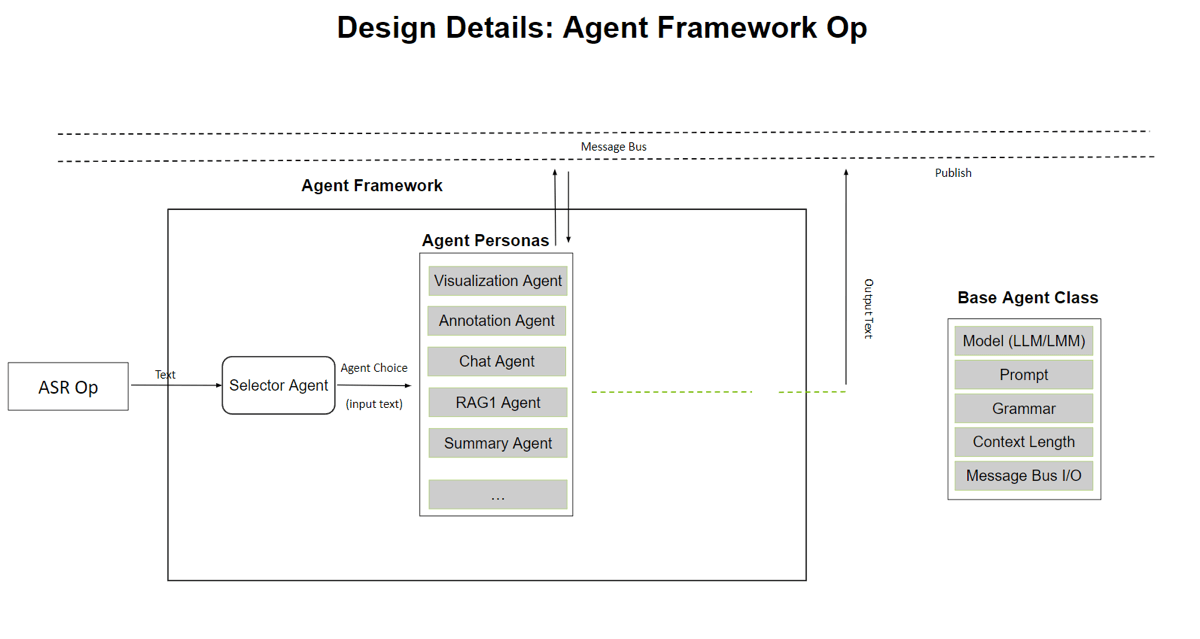 High level overview of the described agent framework.
High level overview of the described agent framework.
The NVIDIA engineers, as one expects from a company selling GPUs to run AI, were all about running LLMs locally. But they had a point: running LLMs locally removes the constraint on what one can do with LLMs. You start to consider different approaches if you don’t have to be concerned about raking up a cloud bill in the thousands of dollars.
For example, imagine we passed every state change in your house to an LLM. If the front door opens at night while everyone is home, is that suspicious? Creating a rule-based system for this is hard to get right for everyone, but an LLM might just do the trick.
It was this conversation that led us to our current approach: In Home Assistant we want AI agents. Many AI agents.
Defining AI Agents
As part of last year’s Year of the Voice, we developed a conversation integration that allowed users to chat and talk with Home Assistant via conversation agents. Next to Home Assistant’s conversation engine, which uses string matching, users could also pick LLM providers to talk to. These were our first AI agents.
Set up Google Generative AI, OpenAI, or Ollama and you end up with an AI agent represented as a conversation entity in Home Assistant. For each agent, the user is able to configure the LLM model and the instructions prompt. The prompt can be set to a template that is rendered on the fly, allowing users to share realtime information about their house with the LLM.
The conversation entities can be included in an Assist Pipeline, our voice assistants. Or you can directly interact with them via services inside your automations and scripts.

As a user, you are in control when your agents are invoked. This is possible by leveraging the beating heart of Home Assistant: the automation engine. You can write an automation, listen for a specific trigger, and then feed that information to the AI agent.
The following example is based on an automation originally shared by /u/Detz on the Home Assistant subreddit. Every time the song changes on their media player, it will check if the band is a country band and if so, skip the song. The impact of hallucinations here is low, the user might end up listening to a country song or a non-country song is skipped.
trigger:
- platform: state
entity_id: media_player.sonos_roam
condition: '{{ trigger.to_state.state == "playing" }}'
action:
- service: conversation.process
data:
agent_id: conversation.openai_mario_en
text: >-
You are passed the state of a media player and have to answer "yes" if
the song is country:
{{ trigger.to_state }}
response_variable: response
- if:
- condition: template
value_template: '{{ response.response.speech.plain.speech.lower().startswith("yes") }}'
then:
- service: media_player.media_next_track
target:
entity_id: '{{ trigger.entity_id }}'
We’ve turned this automation into a blueprint that you can try yourself. It allows you to configure the criteria on when to skip the song.
![]()
Researching AI
One of the weird things about LLMs is that it’s opaque how they exactly work and their usefulness can differ greatly per task. Even the creators of the models need to run tests to understand what their new models are capable of. Given that our tasks are quite unique, we had to create our own reproducible benchmark to compare LLMs.
To make this possible, Allen Porter created a set of evaluation tools including a new integration called “Synthetic home”. This integration allows us to launch a Home Assistant instance based on a definition in a YAML file. The file specifies the areas, the devices (including manufacturer/model) and their state. This allows us to test each LLM against the exact same Home Assistant state.
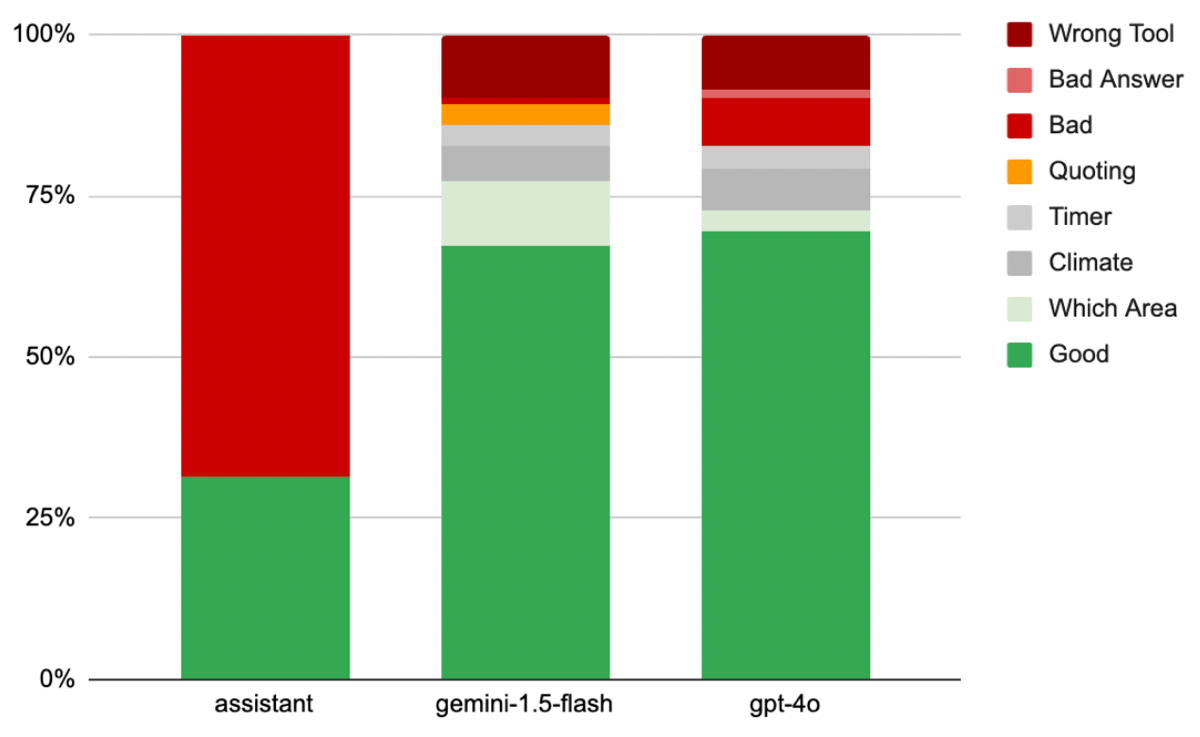 Results comparing a set of difficult sentences to control Home Assistant between Home Assistant's sentence matching, Google Gemini 1.5 Flash and OpenAI GPT-4o.
Results comparing a set of difficult sentences to control Home Assistant between Home Assistant's sentence matching, Google Gemini 1.5 Flash and OpenAI GPT-4o.
We’ve used these tools extensively to fine tune the prompt and API that we give to LLMs to control Home Assistant. The reproducibility of these studies allows us to change something and repeat the test to see if we can generate better results. We are able to use this to test different prompts, different AI models and any other aspect.
Defining the API for LLMs
Home Assistant has different API interfaces. We have the Home Assistant Python object, a WebSocket API, a REST API, and intents. We decided to base our LLM API on the intent system because it is our smallest API. Intents are used by our sentence-matching voice assistant and are limited to controlling devices and querying information. They don’t bother with creating automations, managing devices, or other administrative tasks.
Leveraging intents also meant that we already have a place in the UI where you can configure what entities are accessible, a test suite in many languages matching sentences to intent, and a baseline of what the LLM should be able to achieve with the API.
Home Assistant already has different ways for you to define your own intents, allowing you to extend the Assist API to which LLMs have access. The first one is the intent script integration. Using YAML, users can define a script to run when the intent is invoked and use a template to define the response.
intent_script:
EventCountToday:
action:
- service: calendar.get_events
target:
entity_id: calendar.my_calendar
data_template:
start_date_time: "{{ today_at('00:00') }}"
duration: { "hours": 24 }
response_variable: result
- stop: ""
response_variable: result
speech:
text: "{{ action_response['calendar.my_calendar'].events | length }} events"
We haven’t forgotten about custom components either. They can register their own intents or, even better, define their own API.
Custom integrations providing their own LLM APIs
The built-in LLM API is focused on simplicity and being good at the things that it does. The larger the API surface, the easier AI models, especially the smaller ones, can get confused and invoke them incorrectly.
Instead of one large API, we are aiming for many focused APIs. To ensure a higher success rate, an AI agent will only have access to one API at a time. Figuring out the best API for creating automations, querying the history, and maybe even creating dashboards will require experimentation. When all those APIs are in place, we can start playing with a selector agent that routes incoming requests to the right agent and API.
To find out what APIs work best is a task we need to do as a community. That’s why we have designed our API system in a way that any custom component can provide them. When configuring an LLM that supports control of Home Assistant, users can pick any of the available APIs.
Custom LLM APIs are written in Python. When a user talks to an LLM, the API is asked to give a collection of tools for the LLM to access, and a partial prompt that will be appended to the user prompt. The partial prompt can provide extra instructions for the LLM on when and how to use the tools.
Future research
One thing we can do to improve AI in Home Assistant is wait. LLMs, both local and remotely accessible ones, are improving rapidly and new ones are released regularly (fun fact, I started writing this post before GPT4o and Gemini 1.5 were announced). Wait a couple of months and the new Llama, Gemini, or GPT release might unlock many new possibilities.
We’ll continue to collaborate with NVIDIA to enable more local AI functionalities. High on our list is making local LLM with function calling easily accessible to all Home Assistant users.
There is also room for us to improve the local models we use. We want to explore fine-tuning a model for specific tasks like voice commands or area summarization. This would allow us to get away with much smaller models with better performance and reliability. And the best thing about our community? People are already working on this.
We also want to see if we can use RAG to allow users to teach LLMs about personal items or people that they care about. Wouldn’t it be great if Home Assistant could help you find your glasses?
Join us
We hope that you’re going to give our new AI tools a try and join us on the forums and in the #voice-assistants channel on our Discord server. If you find something cool, share it with the community and let’s find that killer use case!
This is a companion discussion topic for the original entry at https://www.home-assistant.io/blog/2024/06/07/ai-agents-for-the-smart-home