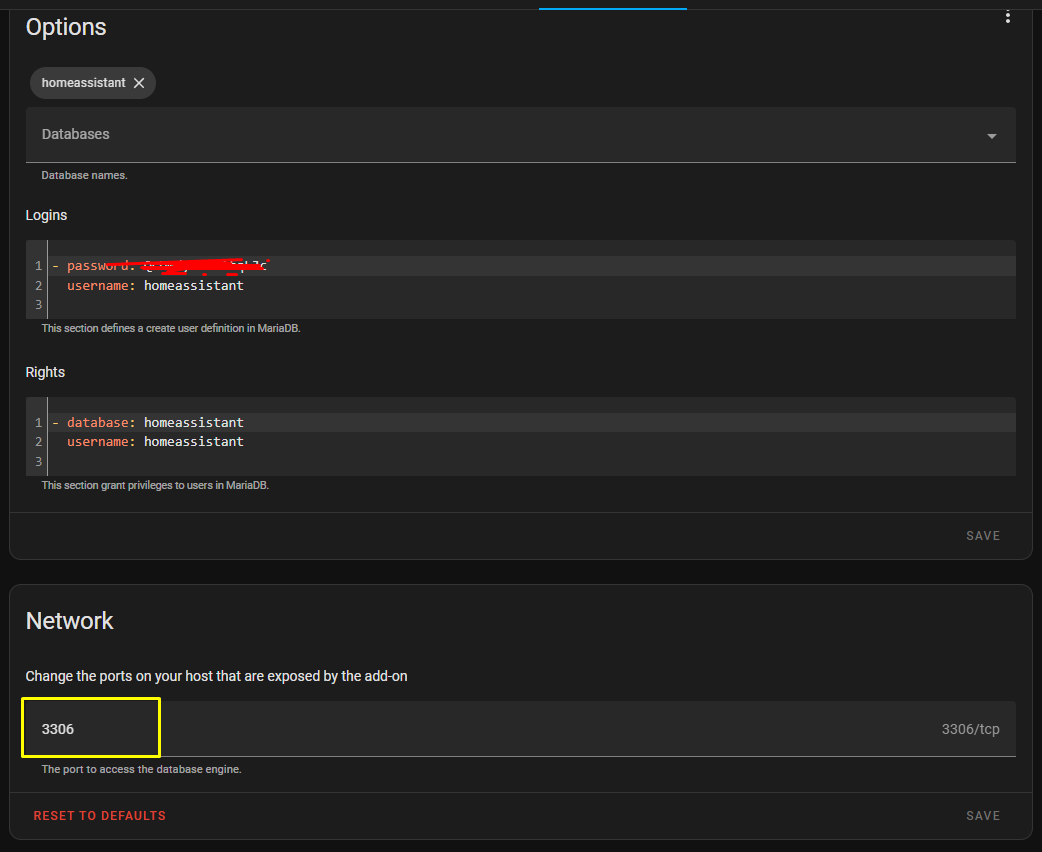
I’m trying to use this addon but it’s impossible to configure. I’m using HA with standard installation (no docker installation) with mariadB as database. The configuration for the adddum is:
- db_password: "12345"
db_username: homeassistant
db_host: 192.168.1.120
db_port: "3306"
db_database: homeassistant
db_type: mariadb
But there are some errors like:
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 868, in _checkout
fairy = _ConnectionRecord.checkout(pool)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 476, in checkout
rec = pool._do_get()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/impl.py", line 146, in _do_get
self._dec_overflow()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/langhelpers.py", line 70, in __exit__
compat.raise_(
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/compat.py", line 208, in raise_
raise exception
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/impl.py", line 143, in _do_get
return self._create_connection()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 256, in _create_connection
return _ConnectionRecord(self)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 371, in __init__
self.__connect()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 666, in __connect
pool.logger.debug("Error on connect(): %s", e)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/langhelpers.py", line 70, in __exit__
compat.raise_(
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/compat.py", line 208, in raise_
raise exception
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 661, in __connect
self.dbapi_connection = connection = pool._invoke_creator(self)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/create.py", line 578, in connect
return dialect.connect(*cargs, **cparams)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/default.py", line 597, in connect
return self.dbapi.connect(*cargs, **cparams)
File "/opt/venv/lib/python3.9/site-packages/pymysql/connections.py", line 353, in __init__
self.connect()
File "/opt/venv/lib/python3.9/site-packages/pymysql/connections.py", line 664, in connect
raise exc
pymysql.err.OperationalError: (2003, "Can't connect to MySQL server on '192.168.1.120' ([Errno 111] Connection refused)")
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/thesillyhome_src/thesillyhome/src/thesillyhome/model_creator/main.py", line 16, in <module>
parse_data_from_db()
File "/thesillyhome_src/thesillyhome/src/thesillyhome/model_creator/parse_data.py", line 73, in parse_data_from_db
df_all = homedb().get_data()
File "/thesillyhome_src/thesillyhome/src/thesillyhome/model_creator/home.py", line 74, in get_data
with self.mydb.connect() as con:
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/base.py", line 3315, in connect
return self._connection_cls(self, close_with_result=close_with_result)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/base.py", line 96, in __init__
else engine.raw_connection()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/base.py", line 3394, in raw_connection
return self._wrap_pool_connect(self.pool.connect, _connection)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/base.py", line 3364, in _wrap_pool_connect
Connection._handle_dbapi_exception_noconnection(
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/base.py", line 2198, in _handle_dbapi_exception_noconnection
util.raise_(
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/compat.py", line 208, in raise_
raise exception
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/base.py", line 3361, in _wrap_pool_connect
return fn()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 310, in connect
return _ConnectionFairy._checkout(self)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 868, in _checkout
fairy = _ConnectionRecord.checkout(pool)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 476, in checkout
rec = pool._do_get()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/impl.py", line 146, in _do_get
self._dec_overflow()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/langhelpers.py", line 70, in __exit__
compat.raise_(
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/compat.py", line 208, in raise_
raise exception
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/impl.py", line 143, in _do_get
return self._create_connection()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 256, in _create_connection
return _ConnectionRecord(self)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 371, in __init__
self.__connect()
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 666, in __connect
pool.logger.debug("Error on connect(): %s", e)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/langhelpers.py", line 70, in __exit__
compat.raise_(
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/util/compat.py", line 208, in raise_
raise exception
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/pool/base.py", line 661, in __connect
self.dbapi_connection = connection = pool._invoke_creator(self)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/create.py", line 578, in connect
return dialect.connect(*cargs, **cparams)
File "/opt/venv/lib/python3.9/site-packages/sqlalchemy/engine/default.py", line 597, in connect
return self.dbapi.connect(*cargs, **cparams)
File "/opt/venv/lib/python3.9/site-packages/pymysql/connections.py", line 353, in __init__
self.connect()
File "/opt/venv/lib/python3.9/site-packages/pymysql/connections.py", line 664, in connect
raise exc
sqlalchemy.exc.OperationalError: (pymysql.err.OperationalError) (2003, "Can't connect to MySQL server on '192.168.1.120' ([Errno 111] Connection refused)")
(Background on this error at: https://sqlalche.me/e/14/e3q8)
Model generation failed.
Starting frontend on 0.0.0.0:2300
Listening on 0.0.0.0:2300
I uninstalled the addon, because is impossible to check…
Jose