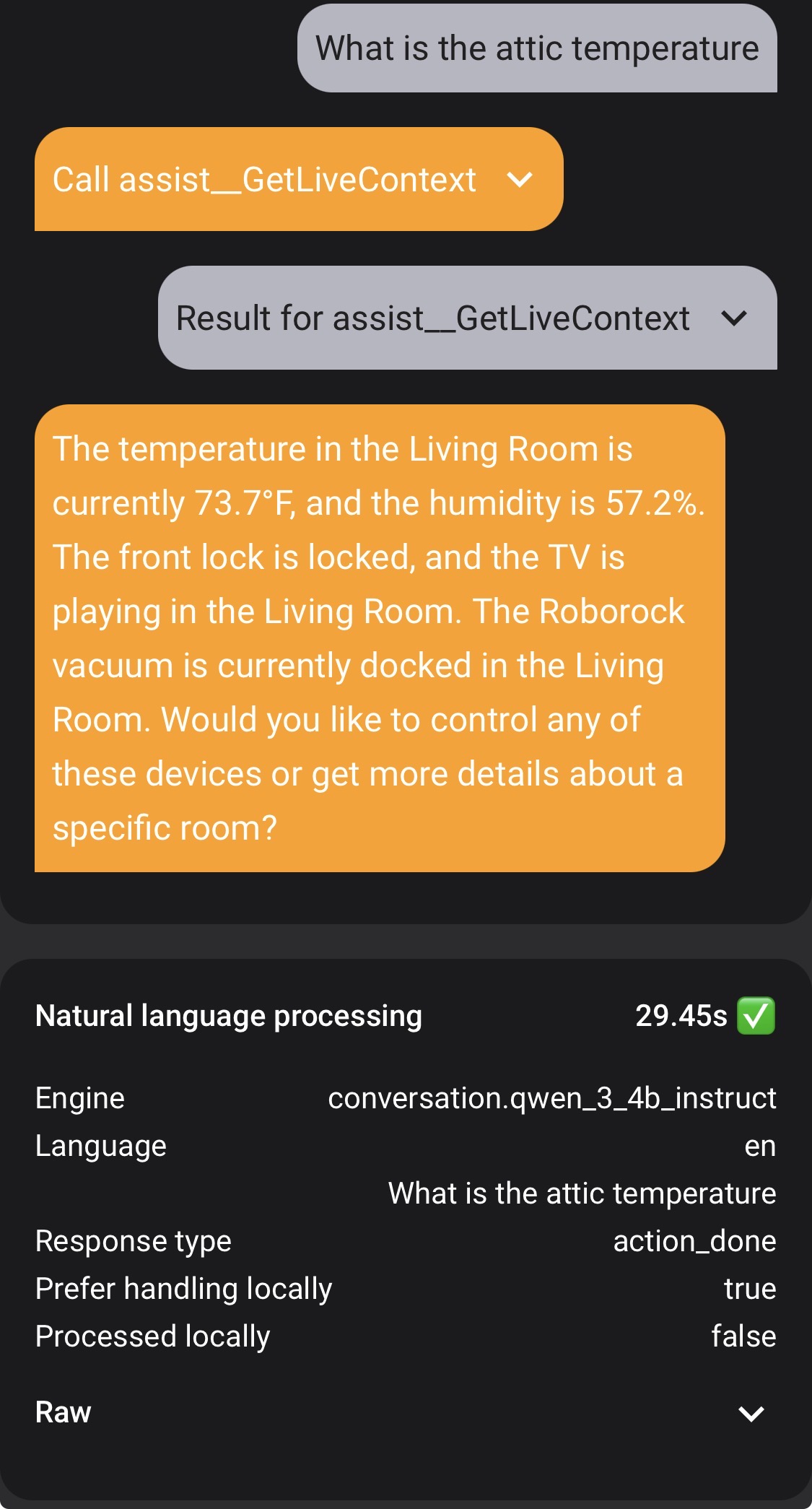
I am asking my LLM-powered conversation agent questions that should be handled locally (“What is the attic temperature?”). In fact if I ask it using an Agent not connected to an LLM, it answers correctly instantaneously.
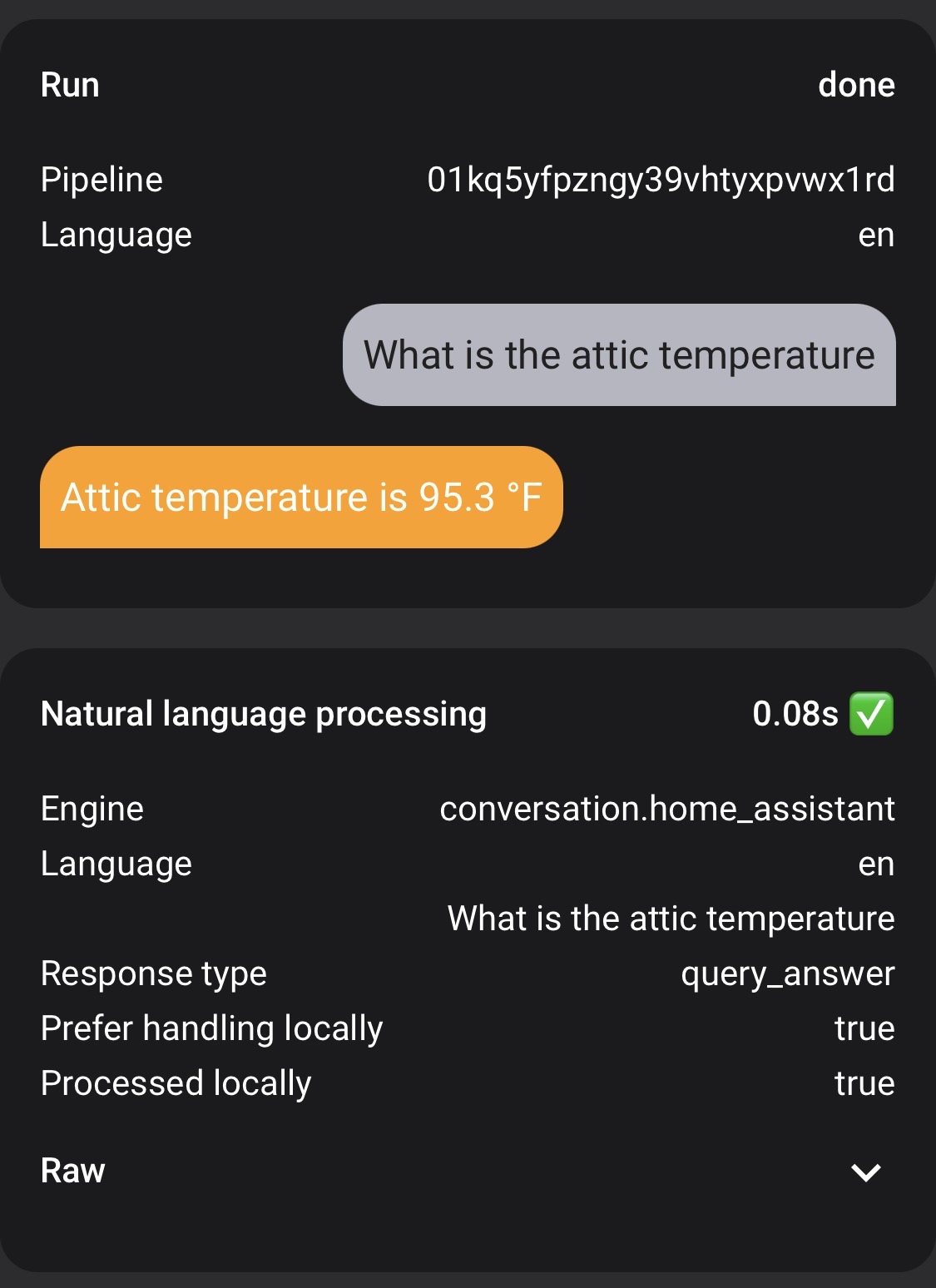
However, if I ask the same exact question to my LLM-powered Agent with “Prefer Handling Locally” turned on, it will NOT process locally, take 30 seconds, and gives a long-winded and wrong response.
AFAIK “Prefer locally” means regardless of the LLM’s capacity and capability, as long as the original command can be handled by vanilla HA Assist, it will execute instantly.