Yes, they are.
Did it on hassos install.
Went through the setup but it is showing as , anything i might be doing wrong?
I had to change the port number because 5000 is taken
- platform: deepstack_object
ip_address: localhost
port: 5001
scan_interval: 5000
target: person
source:- entity_id: camera.front_door
name: person_detector_front
- entity_id: camera.front_door
Do you launch it like below link?
sudo docker run -e VISION-DETECTION=True -v localstorage:/datastore -p 5001:5000 deepquestai/deepstack
1 Like
hi, any updates?
When you update the component are you going to update it to the new development file structure
Been running on Synology NAS and using Node-Red for alerting. Only used a single camera previously, but now expanding to all the cameras on the outside (had our first sunny day and the motion detection was going nuts with the shadows).
It seems a better way to go the setting scan_interval, is use the motion trigger then check if a person is detected before sending an alert. Going to give that a whirl and report back 
Thanks for sharing, SUPER useful and great implementation for non AI folks to pick up!
1 Like
I have created a Node Red flow, inspired from TaperCrimps guide in Improving Blue Iris with Home Assistant, TensorFlow, and Pushover [SIMPLIFIED!]

My problem is that when motion is triggered the image scan in “Deepstack People Scan” does not use the image saved using the camera.snapshot in “Get picture from camera” it uses the picture that were created last time.
But if I after this manually push the timestamp trigger the image scan will use the picture that just were saved using the camera.snapshot service.
I have tried using a delay so that the file should have plenty of time to get saved to disk, but it did not change anything.
What could be wrong, and how should I change the flow?
I have installed Deepstack on a Hyper-v instant of Ubuntu with hass.io installed.
@robmarkcole Would Deepstack be better than tensorflor faster_rcnn_inception_v2_coco in any ways? How would you perceive the differences?
What happens if have two “Get picture from camera”? Would it use the right picture in “created last time” this way?
I still get the the same result from the “DeepStack People Scan” as I got the last time I ran it. Even increased the delay to one minute.

Did some more testing and it seems that the image.processing is only done when I push the timestamp button. Look at the time on this image. The component in home assistent was last updated 19:31 and not 19:38.

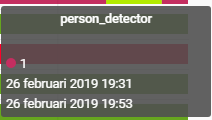
So DeepStack is processing an image from a file that doesn’t exist at the time DeepStack is called. Perhaps try deleting the old file (19:31 one) and the run the automation to be sure.
I use the node wait until - not at my PC atm - but i essentially do the following:
- Motion detected on my camera
- run image_processing.scan (entity_id: the_same_camera)
- wait until node: wait 20 seconds until image_processing > 0 (else timeout)
- if value >0 alert me to person detection
For some reason DeepStack does not seem to process the call if the node is in the same flow as camera.snapshot
I changed the flow so that I have two “Front door motion” triggers and it seems to work better.

I have only been able to fake some test, since I am not at home right now. But the person_detector is now activated when there are motion.
Will test some more when I am home and actually can be in front of the camera and trigger the motion detector.
The image_processing.scan works now Some times I can’t figure out Node-Red…Thanks for the help!
1 Like
Can i ask what made you take the camera.snapshot and then also ask how you image_processing.scan that image? vs using the entity that is created called image_processing.entity and image_processing.scan that? or is the snapshot purely for sending in the notification?
with the below i get an entity called image_processing.location_person and I scan that - but equally interested to see if i can scan the image that was captured from motion
image_processing:
- platform: deepstack_object
ip_address: <IP>
port: 34856
scan_interval: 20000
target: person
source:
- entity_id: camera.location
name: location_person
What I did was first make the snapshop and save it as a localfile. And then use the localfile as source for the image_processing.scan (person_detector)

Using this in the config.yml
source:
- entity_id: camera.local_file
name: person_detector
Then I use the same image and send it as a notification.
After some more thinking I could probably create a config file like this.
image_processing:
- platform: deepstack_object
ip_address: localhost
port: 5000
scan_interval: 20000
target: person
source:
- entity_id: camera.local_file
name: person_detector
- entity_id: camera.frontdoor_camera
name: person_detector_frontdoor
- entity_id: camera.patio_camera
name: person_detector_patio
- platform: deepstack_face
ip_address: localhost
port: 5000
scan_interval: 20000
source:
- entity_id: camera.local_file
name: face_counter
That would create the entitys
image_processing.person_detector_frontdoor
image_processing.person_detector_patio
image_processing.person_detector
That could be used using the image_processing.scan
But I do not know if I would get any advantage using it this way, since the notification will not use the same image as the image_processing.scan. That would make it a bit harder to debug.
This requires a camera I assume?
1 Like
Well you need an image source.
1 Like
Trying the deepstack docker image for a few days no.
It does a pretty good job in detecting the number of persons (when motion is detected, the event is triggered including a telegram message with the amount of persons detected).
It does however take quite some time for processing, but maybe that would be because of resources on the running host?
From the logs, peaks to 20 seconds response time.
[GIN] 2019/03/04 - 10:22:43 | 200 | 8.362751341s | 192.168.1.12 | POST /v1/vision/face/recognize
[GIN] 2019/03/04 - 10:22:55 | 200 | 11.062729551s | 192.168.1.12 | POST /v1/vision/face/recognize
[GIN] 2019/03/04 - 10:22:55 | 200 | 20.225137672s | 192.168.1.12 | POST /v1/vision/detection
[GIN] 2019/03/04 - 10:23:06 | 200 | 10.961049775s | 192.168.1.12 | POST /v1/vision/detection
I do also run ZoneMinder on the same VM (which is the actual camera source) and it’s ‘just’ a Intel C2Quad at 2.4Ghz, but 20 seconds is a bit long?
Nico