Looking forward to seeing the new stuff.
1 Like
You could be adventurous… ![]()
![]()
Seriously though I had tk shut off the alerter last night because when I built the new taskmaster component I also missed the option thag says get only open tasks not closed ones. Ha… Don’t do that.
So the LLM thought I hadn’t closed any of my tasks (like taking pills or…) and kept sending me increasingly urgent texts all afternoon. Yes I know how to fix it yes I just hit the kill switch for actions…
Good test. Kill switch works.
I may just do that today.
1 Like
I may just do a doc pass and post a build today.
Ecto branch has been running no issues two days. It’s good to send. I wanted to get taskmaster In-build and may still ship it in box (I did, figured out why it was misbehaving, also shipping alert_manager).
Should be later today. (I just pushed the last changes I had to the branch, going to let it sit for a couple hours, touch up the readmes and then push it to main…)
3 Likes
I jumped in even though it isn’t live yet.
1 Like
you shouldnt regret it - well ok unless oyu literally pulled it iin the last 11 minutes in that case theres a cabinets fix comin… Blame Tes. *LMAO
1 Like
I hadn’t done it that recently; the documentation update hadn’t been done yet when I grabbed it.
Gimme about none minutes:
Current version: 2026.4.0 ‘Ectoplasm’
Versioning: Public ZenOS releases follow Home Assistant’s
YYYY.M.patchconvention — if you’re already running HA, you already know this clock. Internal architecture versioning (4.5.xseries) is retained in commit history and internal tooling.
2026.4.0 ‘Ectoplasm’ shipped 2026-04-04 — new zen_dojotools_ectoplasm (Spook/HA extended surface: repairs, areas, floors, entity/device lifecycle, labels, integrations), Index 4.6.3 topology seeds + pagination + registry modes, Inspect 4.6.2 registry enum modes, Ninja run governor, Scribe 1.2.0.
Full notes: Ectoplasm Release Notes | Ready Player Two | 2026.3.1 Patch Notes
This is an interesting project, and I respect the time you put into it.
I’m eager to run AI in my home too, but I’ve kept it on the back burner because the space is still maturing toward what I actually want: local, private, and cost-efficient. Right now, a lot of what we have feels more like compression and workarounds than a truly ideal solution.
With your setup, the core issue is that you’re using a general-purpose model through an API. A model like that was not trained on your house, your entity names, your automations, your devices, or your preferences, so all of that has to be provided at runtime.
You can reduce that gap with scripts, tools, and better prompt design, but that also creates a tradeoff: more token usage, more moving parts, and more cost if the model is hosted remotely.
To me, the bigger point is that needing huge amounts of context is often a sign that the model is too general for the job, or that the system architecture is doing too much through prompting instead of design. A specialized or embedded assistant still needs context, but usually much less of it because more of the task knowledge is already built into the system.
So the real options seem to be:
- run a local model, probably quantized
- use a smaller hosted model
- tighten the architecture so the AI only gets the exact context it needs
At some point, if you have to keep feeding the model a massive amount of information just to make it useful, it starts to feel less like an intelligent home assistant and more like continuously re-teaching a general model how your house works. What’s really needed is partially what you’ve done and a model trained to be a home assistant ai.
That said, I still think this is a very interesting direction, and I appreciate you sharing the work publicly.
2 Likes
The fun part is nothing here precludes a fine tuned model… Or access by mcp…hint hint. Everything in HA needs to be tuned. This is one part.
That does seem like a major advantage going forward. The real question is whether you plan to actually build or fine-tune a model around Home Assistant itself, rather than just adapting a general model to your own home through tooling and context. If you ever chose to pursue that more seriously, I think there would be genuine community interest.
Id donate to said gofundme myself.
Read the thread - this is an ongoing project.
First there is HA itself…- its not optimized for context, that’s where the index came from. this is step 1.
Second it’s not optimized for secure access. This is step 2 (SP1 will bring most of it and the plumbing is there now) - and will be done before I EVER look at tuning a model. (If you want to knock yourself out)
Third - HA sucks at providing a way for users to add written context. The cabinets solve that. (Yes, they can be in a DB in the future, thanks for asking. Redis probably, definitely a link to Obsidian vaults with a neo4j+Opensearch index)
The purpose of this is to reduce the context in an average home to something that can be consumed by a commodity tool use model in UNDER a 64K context)
As of this week I can consume the context from a 25000 entity richly instrumented HA install in under 64K. This includes enhanced controls such as hot tub chemistry and full alert and task monitoring. STRONGLY suspect I can get it under 48K and no rag implementation comes close to the capability.
WHY. Nathan…
Because most (vast majority of people) don’t know training a model is a thing or that specific models are required, or desired for certain tasks or that that those models have limits or things called quantization… Or the first thing about what’s REQUIRED for context in the first place. This does that part for you.
Because at those sizes I listed above, you can run a fully local commodity model that doesn’t HAVE to be tuned on a 16G card. And it’s even pretty snappy. (rn i just deal with a 1-2 second lag as the ctx/kv loads)
Why else, this way…
- If you choose to BYO tuned or superawesome model - it only makes it better. Use my tools your model, woot!
- If you choose to use someone’s plugin MCP - then the tools still work. IN FACT I plan on making them more secure than any other tool you can currently use on HA. See that caller token? Yes I plan to make the caller ID itself for tool perms.
- If you choose to do this then it standardizes the tool use format and gives the model some incredibly neat tricks… Index can tell you if you have an appointment if its tagged correctly.
- It also helps the model onboard understand the system, making it wayyyy easier to instruct said model without having a PHd. in machine learning
 It can troll all the context sources you didnt know you had like label details.
It can troll all the context sources you didnt know you had like label details.
Its the framework of what HA should have for users to be successful with the base - purpose built to drag context out of ha SECURELY then you plug in what you want from there.
2 Likes
There are Home Assistant fine-tuned models, but only in a couple of languages.
Personally, I think it’s better to go uber than under. To boldly go etc.
2 Likes
Acorn was nice when the best we had was llama3 but honestly now the Qwen 3.5:4b model will kick its ever loving tail from here around the planet three times and back for a very small size increase (acorn is 3b, the small Qwen is 4b and Google just released a 2b thats supposed to actually work…)
I think ultimately Mark the models will get to the point where fine tuning simply, wont be necessary - just pick a really good tool user and some good manuals. Because that’s ALL a HA workload really is.
Now if you want a REALLY GOOD agent - also make it a badass personal assistant that knows how to keep its mouth shut… ![]()
I mean my mom doesn’t want to worry about which model she’s running - she just wants the darned lights to not turn off when she’s in the kitchen… She just needs to know its faster than Alexa, more relevant to her, and doesn’t sell her info to Bezos…
Where I THINK we’re quickly heading is yes there will be a commodity AI box that will sell for sub-$5000 usd. and you can run a subscribe here for AI model in the :30b size range (Qwen 3.5 A3b runs butter smooth on a DGX Spark 128 - so does Gemma 4) think hardware subscription… For the layperson who doesnt want to pay Anthropic or Google or…
For the flexibility a general inference box like that offers I can easily see it as part of every household in 5 yrs like the beige IBM AT or trash 80 was in the 80’s when they started to pull away from Commodore.
(Yes it was approximately the same cost in adjusted 1984 dollars, so for less than a small Harley, you too can have your own private AI assistant… Yeah it’ll happen. That’s an easy bet.)
1 Like
It also becomes much more expensive to run a fine tuned model. If you can get a fine tuned model for your home, that certainly can get you some legs up for that use case, but then what happens when you want to use that model for world knowledge or something unrelated? Now its performance suffers in that area. Sure, you could run another model if you have the VRAM for another model, context, etc. But to me when the current generation of models can run quickly while following instructions and accurately interacting with your home… there really is no downside to having that along where it is also fairly good at local coding or video analysis as well.
3 Likes
Waiting patiently for the next update.
1 Like
You should get it today… Just put in a minor tweak but don’t see anything that should hold me pushing it to main within a few hours.

2026.4.0 laid the groundwork, 2026.4.1 ‘Action Jackson’ puts the ‘Action Pipeline’ to work. The summarizer stack starts to act like an actual managed pipeline. Instead of every component trying to speak the instant it has a thought, the scheduler now looks at queue pressure, component tier, trigger type, and forced-target rules before dispatching work. That means the system can stay responsive under load, shed lower-priority work when needed, and recover skipped work cleanly when the pressure drops.
Once you have enough useful components in play, “just let them all run” stops being clever and starts becoming noise. What I wanted here was not more activity. I wanted more MEANINGFUL activity…
Queued ninja summarizers generate per-component katas, stamp them for staleness, and optionally pass high-urgency results through a gated emission path. Those katas can then be rolled up by components like trapper_keeper, (Yes Trapper Keeper you want to name it something else you write it.) and are ultimately fed into supersummary to produce the household-level context Friday actually uses. Sooo. Traffic cop.
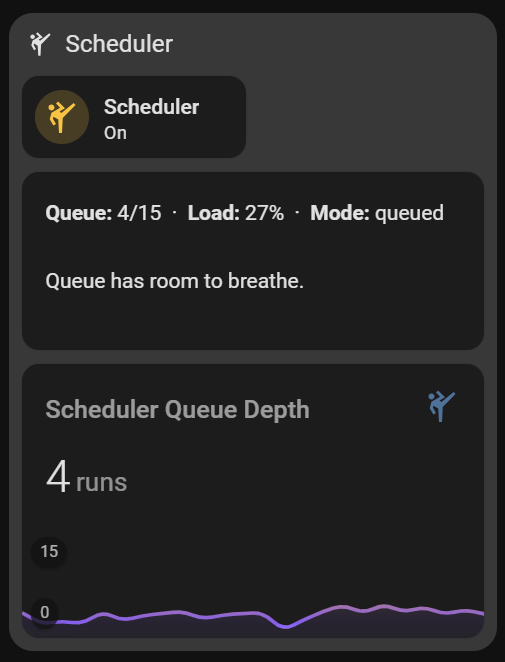
The fun part is that most of this is not hardcoded drama. It is tunable.
You can control shed thresholds, burnout windows, staleness timing, cooldown behavior, urgency floors, trigger subscriptions, and pipeline tier on a per-component basis. One summarizer can behave like critical infrastructure. Another can quietly back off under pressure. Another can be held in reserve unless explicitly forced. Same pipeline, different behavior, no explosion. (I’ll doc all the controls in the docs)
So now, a component can be skipped under queue pressure, recovered later by the drain router, prevented from spamming actions unless it clears the emission gate, and still contribute to a higher-order rollup that shapes live assistant context.
So in practical terms, 2026.4.1 turns on:
- pressure-aware dispatch
- tier-based shedding
- drain recovery for skipped work
- per-component staleness and cooldown handling
- gated action emission
- rollup from component katas to household summary
We’ll be going through how to make the router behave in a future episode. ![]()
'Action Jackson 2026.4.1" is live on Main: nathan-curtis/zenos-ai: Friday’s ZenOS-AI: Modular AI Home Automation Core inspired by Friday, Kronk, Rosie, and the High Priestess. Home Assistant-native, ultra-flexible, and delightfully over-engineered.
1 Like
One other thing that’s not in the notes…
Most of last week I spent digging through the prompt engine trying to cut things down in what we inject into the prompt to get the magic…
Basically, I successfully cut it by more than half. Slightly over 16k toks for my home. (this is the amount we cause in the prompt not exposed ents or tools) Down from… Ok we won’t talk about from how many. Ok. Let’s just say she got the help she needed… ![]()
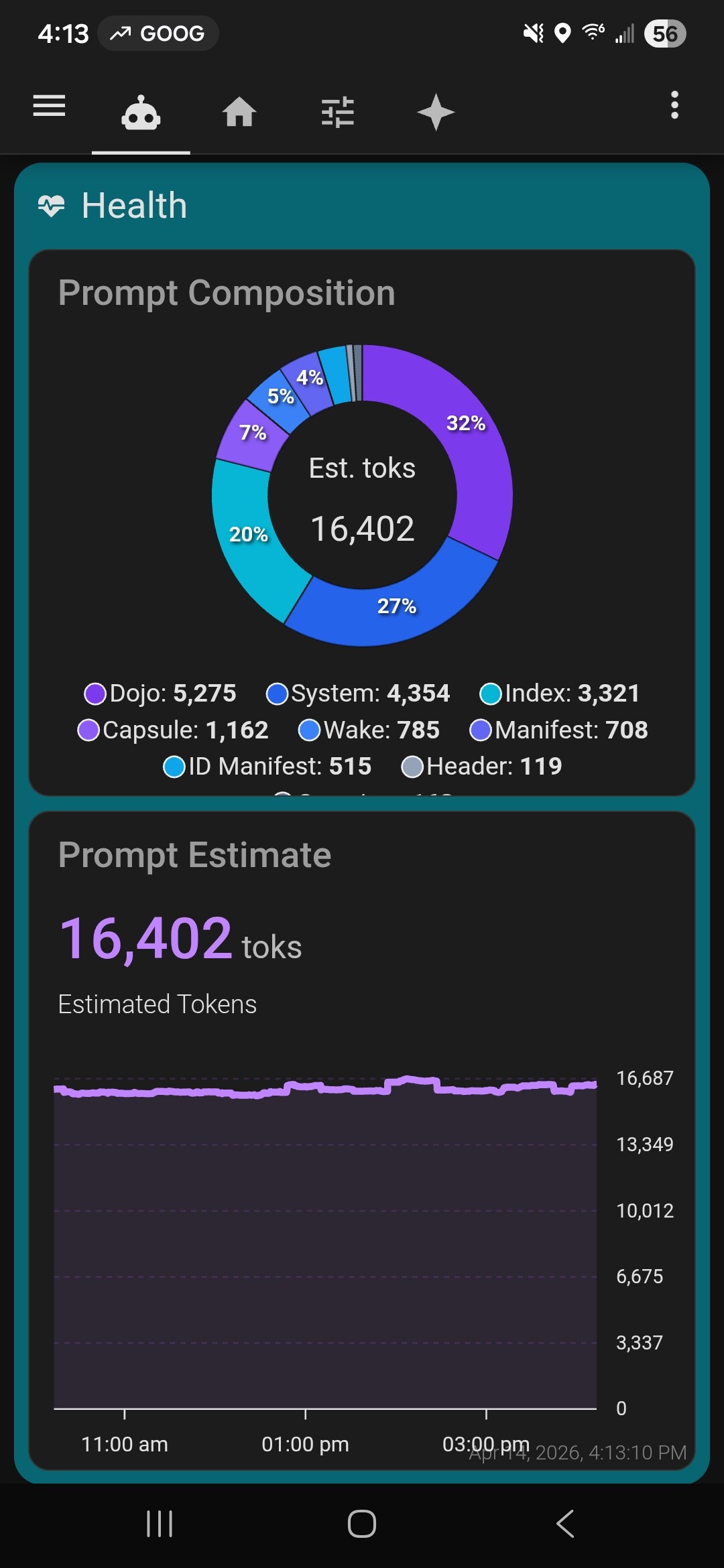
To do that I cast a lot of things out of the prompt and made a few assumptions I setup in cortex V35 so - if you upgrade. Go to the prompt loader and punch in latest cortex (35) to get full net effect… ![]()
Yeah I can totally load context on a 16g card with the right model now. 4.1 enabled fully local for my install… ![]()
In this case the ‘current right model’ is the 4b variant of either qwen35 or Gemma4. Both are just… Wow.
Looks like coming up this week, I get to play with wake words and local streaming voice.
Edit: Patched the ninja summarizer this morning. Apparently the monks need to know what time it is to reliably answer what’s LATE and not consider anything on the list CRITICALLY OVERDUE before I’ve had my coffee. There will be some tuning to the taskmaster component in v.next but the time should do it for now in most cases.
Edit 2: Action Jackson pt. 2: Pushed a cabinets patch to a 2026.4.2 branch this evening to fix an issue reported with a new install. If you’re installing new use that. If you’re upgrading I’m merging a minor cabinet patch in tomorrow…
4 Likes
Dangerous Pass… er - Action Jackson II 2026.4.2
Fixed some bugs…
Grand Champion, Breed Winner Regional, National Winner Princess Donut the Queen Anne Chonk appeared, (see above, she was not amused, not nearly critical but still a side effect of that…) we subsequently cleared a deadlock fixed up some docs etc. Health sensors and Flynn get quality of life while I was in there and maybe moved a hard instruction into the Directives:
- Thou Shalt not use GetLiveState without consulting the index first
Or something… Not exactly that but close enough. I THINK I got it to stick this time. It has a real effect on how many Toks are injected in from tool use. Meanwhile I chopped about another 1K Toks out of the functional prompt with little/no change I can detect. This is in Cortex v.36, If new you get it by default upgrades pop it yourself. I also dropped old cortex packs prior to 30 from the script - if you need an old one, go to a release, it’s in there. I’ll keep N-2 in the script.
Ahead
(No, I wont promise ‘soon’ - some will be delivered soon, some when they make sense, some when I wake up at 2a and can’t sleep… You get the point.)
- More prompt tuning / trimming.
- Even more of that…
- Performance (A third way of saying it. I’m trying to make 16G single card real not just -it works?!? Maybe?)
- Start SP1 work (fer realz, tool/cab ACL gates?)
- A few neat tricks… New notification router
2026.4.2 live on main. Both doesn’t eat cabinets AND lets you actually USE them - how droll! ![]()
1 Like
Up late. Need more coffee. Action Jackson is running. Time to give our girl some eyes and a mouth.

Tonight: vision and voice. Cameras, context, and communications. Friday’s about to get a whole lot more aware.
New DojoTools [TITLE of TOOL] (Camera Tool)
(Yeah I know, name sucks… still workshopping…)
This tool should be able to operate any and all things about the camera domain - especially grabbing LLM snapshots and caching them to the household cabinet and managing the cache ![]() (We don’t infer around here and waste the toks…) I’m also adding the ability to add a default index set to query and pass along with the image to the inference core. Some one standing at your door while its unlocked at night while away has a whole different meaning than middle of the day locked package delivery…
(We don’t infer around here and waste the toks…) I’m also adding the ability to add a default index set to query and pass along with the image to the inference core. Some one standing at your door while its unlocked at night while away has a whole different meaning than middle of the day locked package delivery…
DojoTools Postman
is the start of a notification router so the llm doesn’t have to ‘guess’ where you are and how to reach you. It will just target a person or room or whatever and set preferred mode and urgency.
- Voice in the Kitchen midday - yep
- Voice in the bedroomat 2a Nope.
- Text to your phone followed by a TTS when urgency = 9 and breakthrough selected… Yup…
- Send the picture of the burglar. Sure! Here’s a pic of fido chowing down on the steak the burglar fed him because the cached state from the camera tells Friday where the pic to send you lives…

So you can probably imagine what happens when you mix these with a kung fu component and a few cool custom triggers. ![]()
I’ll also probably move a few remaining functions from Ecto into the label core tool. I’m targeting per-prompt customization and a way to tune for specific models as I continue the SP1 plumbing.
I’m dangerously close to having all the tools I initially planned after adding the number, text and select tools and these - so if you think I’m missing something - except timers. LMK
Coming - when it’s ready. ![]()
…OK, fine, soon - dev branch this week for those of you who like new shiny’s…
4 Likes