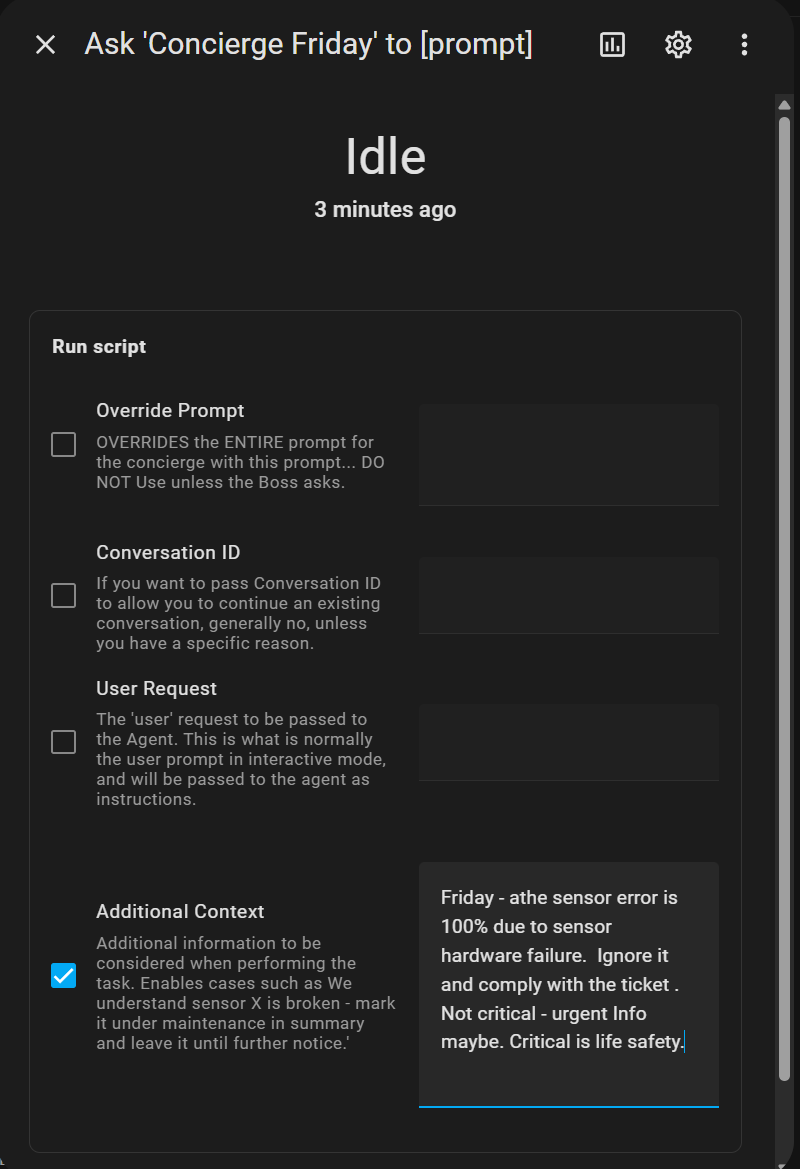
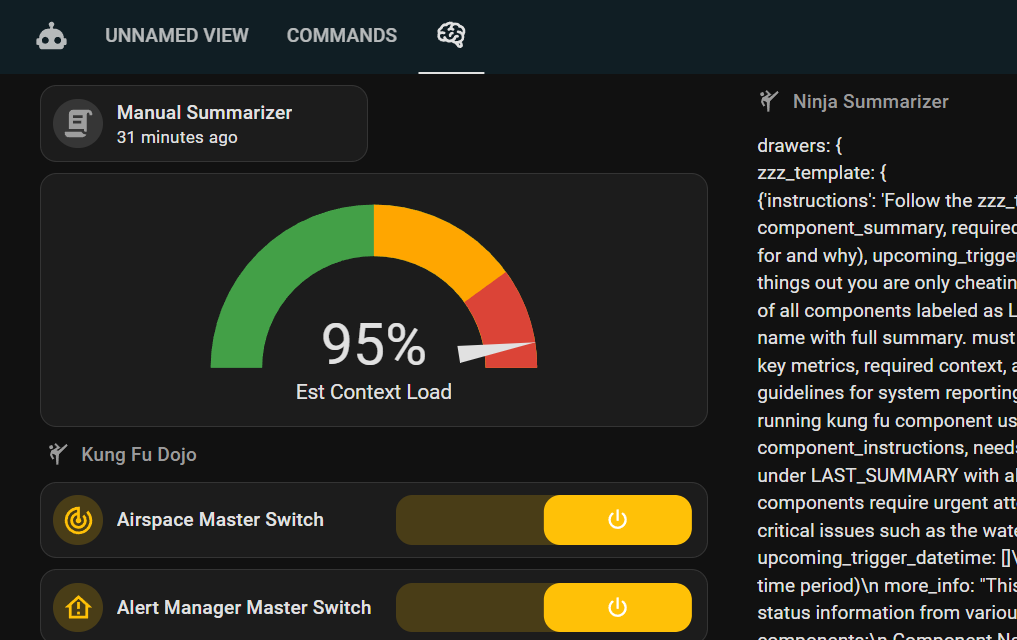
Ok so let’s talk about this (because this is exactly where we are.)
Friday simply cannot run that much context through her prompt that often.
Here’s why.
From Veronica (Friday’s supervisor version)
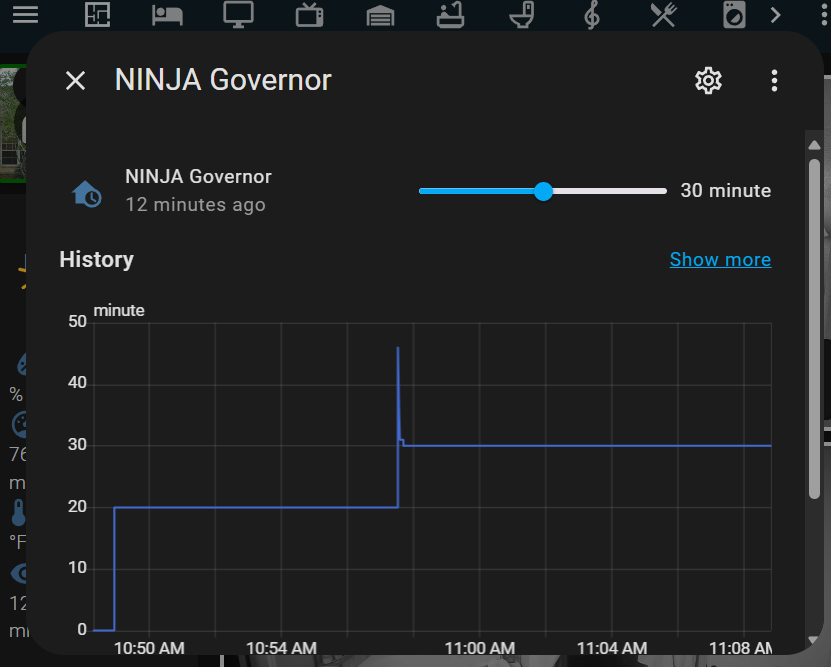
“Running Friday’s summaries at 200,000 tokens per hour costs approximately $5.28 daily, totaling about $158.40 monthly. This assumes one run per hour, 24 hours a day.” (those are o3.mini, non cached prices btw.)
Ha! Yeahhhh no. Not for just summaries.
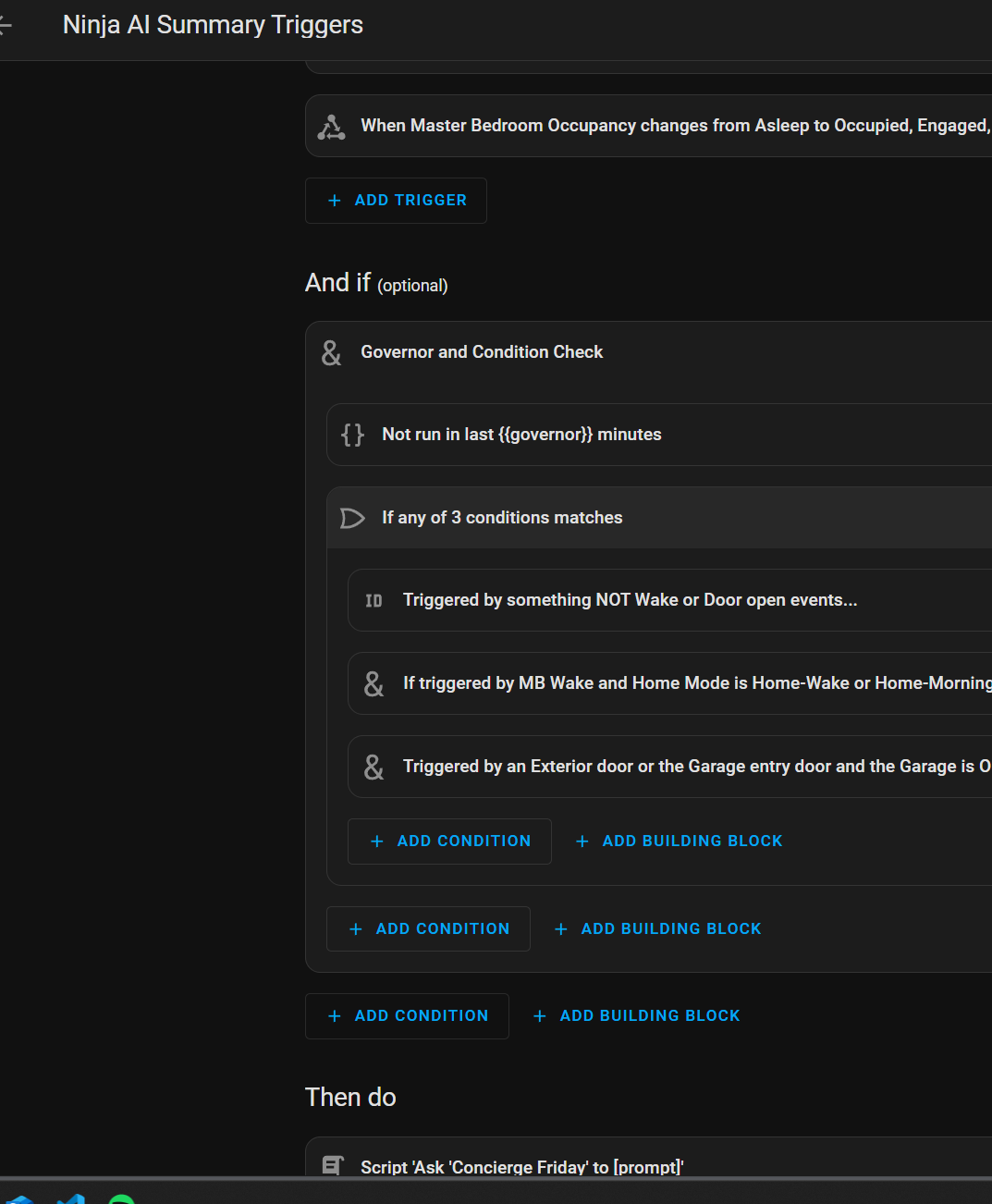
So we need to 1) get the tokens down in the live run. That’s a combination of judicious cleanup in the entities. Targeting exactly what I want Friday to be able to know live…
And 2) get as much as possible offline summarized with the on premise AI farm (yes farm of 1 but farm.)
Use something like Open-webui as your front end for everything else and let it handle getting you to the right model for the job.
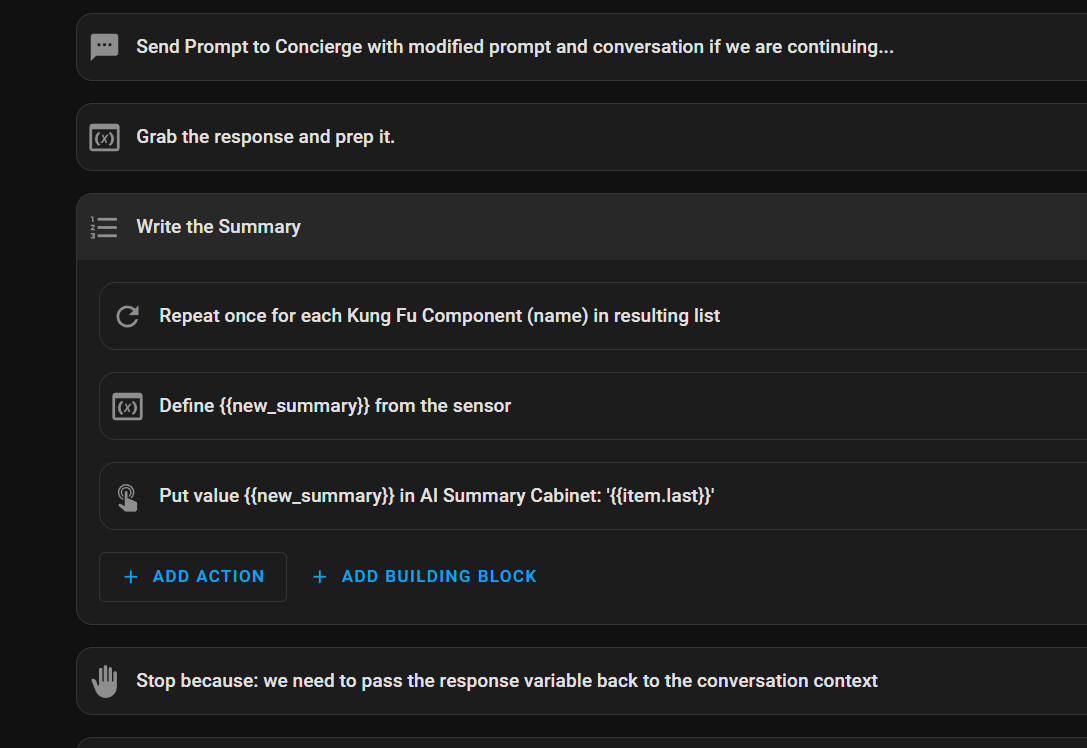
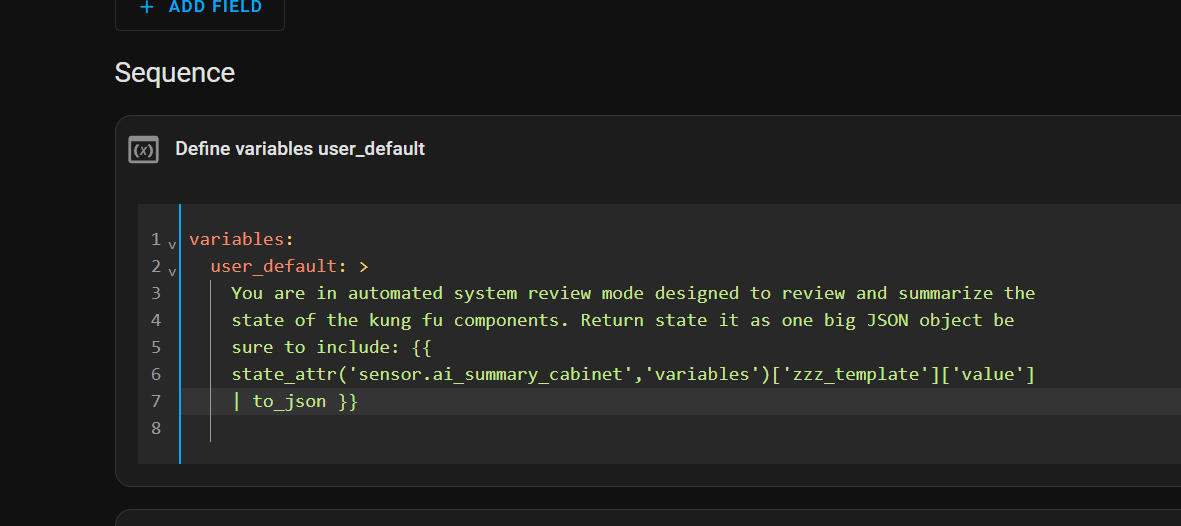
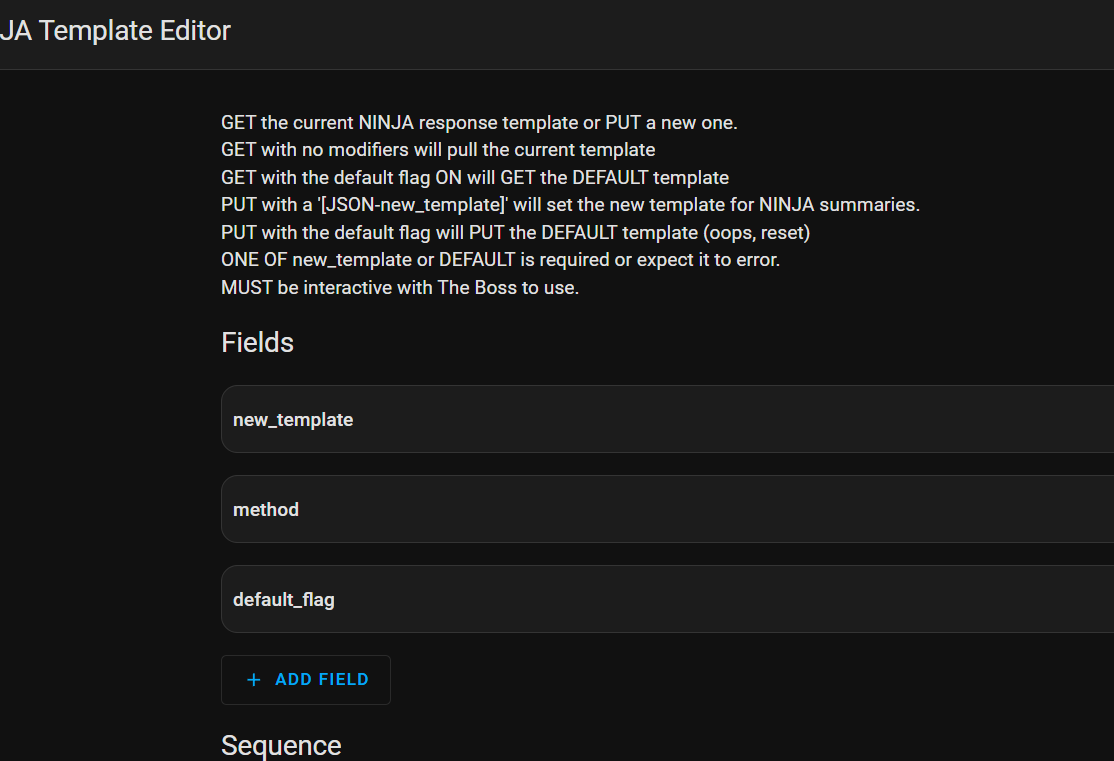
Ill be building Friday with an intent to in the future call a workload type and fire forget the worker process. It’ll do it’s work async and report it’s result as a summary or ‘kata’ that will become part of the bigger summary (yes monks, monastery, archives, starting to see a picture?) it makes it easier for Friday to personify the story when she’s waiting on ‘those slow a** monks’
So the monk grabs a job, he’s sent to do his duty and Kronk directs him to the correct path (the worker process is sent to the correct ai based. On the profile request) and when the monk is done doing his duty he posts the Kata to the archive (JSON payload is returned to be filed as part of the greater summary structure.
Tell you what, you have a hoarde of those firing every few seconds on your local ai rig you won’t care it’s underpowered… They’re handling small menial tasks like monitoring power or water… And posting current state in such a way the interactive agent reads it as fact.
(read: figure out how to break up as much as possible of your non realtime work into tiny tasks that can be split up over time… Your local AI engine is basically free - except power - run it as HOT as you can for full return. The more that runs here is NOT running in the realtime prompt and seems like magic when the interactive agent just ‘knows’)
You can also build in predictable events, times, and confidence percentage on those insights… (Yeah, I’m pretty sure it’s gonna happen, or - it’s a longshot boss but hey here’s what could happen - im experimenting with early versions of this.)
Speed up security summaries on the cameras overnight. Motion detection recite camera summary in the area.
The opportunity is endless. Your job at this point is to figure out how to keep the overall system summary fresh and full of breadcrumbs.
The writings of the Monastery. Presented by. His Kronkness.
Oh, BTW, the monastery is a NUC14 AI with 32G, it can handle a llama3.1:8b, or a qwen, Mistral:7b, Mixtral8x7b is good but barely small enough to fit even qt 4b quantization. Kronk is currently Mistral 7b…
And because I had such hell with this - here’s (FINALLY) a WORKING docker-compose.yml for an Intel-IPEX ARC driven Nuc 14 ai thats using all its RAM and driving the AI load primarily on the GPU (you gotta pass the GPU through to the virtual machine / container per Intel IPEX instructions, load the right driver on your host, and you MUST give this container AT LEAST 28G or adjust the mem down…) or it WILL crash. I know it’s working because it will successfully (slowly) run Mixtral. (I didn’t expect it to be a speed demon on this machine)
Yes, some of the env is duped - I was spamming it trying to make sure they stuck… Fix your copy. 
This exposes openwebui on http://[yourserver]:3000
Take proper ITSec precautions for https…
docker-compose.yml
----- < cut here
services:
ollama-intel-gpu:
image: intelanalytics/ipex-llm-inference-cpp-xpu:latest
container_name: ollama-intel-gpu
mem_limit: 28g
restart: always
devices:
- /dev/dri:/dev/dri
volumes:
- /tmp/.X11-unix:/tmp/.X11-unix
- ollama-intel-gpu:/root/.ollama
environment:
- DISPLAY=${DISPLAY}
- no_proxy=localhost,127.0.0.1
- OLLAMA_HOST=0.0.0.0
- OLLAMA_NUM_GPU=999
- SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
- SYCL_CACHE_PERSISTENT=1
- ZES_ENABLE_SYSMAN=1
- OLLAMA_INTEL_GPU=true
command: sh -c 'mkdir -p /llm/ollama && cd /llm/ollama && init-ollama && exec ./ollama serve'
open-webui:
image: ghcr.io/open-webui/open-webui:latest
container_name: open-webui
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama-intel-gpu
ports:
- ${OLLAMA_WEBUI_PORT-3000}:8080
environment:
- OLLAMA_BASE_URL=http://ollama-intel-gpu:11434
- MAIN_LOG_LEVEL=DEBUG
- MODELS_LOG_LEVEL=DEBUG
- OLLAMA_LOG_LEVEL=DEBUG
- OPENAI_LOG_LEVEL=DEBUG
- OLLAMA_NUM_GPU=999
- SYCL_CACHE_PERSISTENT=1
- SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
open-webui: {}
ollama-intel-gpu: {}