I’ve been experiencing poor performance from HA lately. I have a lot of devices connected, I’m not sure how many, but it’s probably over 500. I’m wondering if I’m just taxing my system too much, although I don’t seem to be based on the stats.
I’m running HA on a PC with 16GB of Ram and a pretty new i7 CPU (I can’t remember the exact model). I also have a Google Coral to handle all the Frigate processes.
Some of my issues:
I see this screen frequently when trying to log in. I need to hit “retry now” 1-3 times to get it to go away.
Devices take a while to update. For example, if I turn off a switch (Kasa) from the HA dashboard the light turns off but the dashboard still shows the light on for 15-45 more seconds.
Scripts take a while to process. If I hit the “Movie” script to turn off 12 lights and turn 4 to red color and 50% brightness (all lights are Tuya can lights flashed with ESPhome) it can take a minute or more
Devices seem to fall offline frequently. I have several ESPhome devices that go unavailable frequently (like every 10 minutes) when they use to be rock-solid. I use ESPSomfy RTS devices for my Somfy shades. They were perfect for 4 months, now 1 or more of the devices (I have 7) seem to go unavailable daily.
Are you up to date with your esphome nodes (2012.12.x) and HA core also? Maybe some bug is in the soup?
I’m on the most recent HA core but running some couple of month old versions on my (around) 50 esphome nodes. Everything rock solid like always for me.
HA is mostly a single threaded application - in that most processing / state updates / automations / device io take place in a single thread. So while you have a bunch of core on the i7, HA can only utilize one. So let’s say you have 4 cores and the overall CPU utilization is 30%, it is possible that the core being used by HA is 100% utilized. It’s also possible there is a poorly written integration that is slowing everything down. Try disabling the integration integrations one by one.
What do your Integration Startup times look like? (Settings - System - Repairs - 3 dots in upper right corner). That might show if one or more integrations are slowing things down.
When you hit that “Retry Now” login screen, have another browser tab open and point it to the HA Observer URL to see if it shows everything connected and healthy: http://homeassistant.local:4357/
Set up a continuous ping to one of your ESP devices and see if there are dropped packets: ping ipaddress -t
What’s the signal strength when you look at the ESPHome logs?
I suspect this is more a WiFi issue than an HA issue. Try rebooting your router and any access points to see if the response improves, even if for just a short time before all of those WiFI devices reconnect.
Yea, having both HA and your computer wired seems to rule out the WiFi side of things. When my ESP devices were going unavailable I could see the dropped ping replies, and power cycling my Unifi AP resolved it. My slowest integration startup time is about 21 seconds, but I’ve seen that vary by ± 25 seconds after any restart, so that doesn’t seem to be an issue.
What’s your default Logger level set to? Might want to set it to debug temporarily to see if anything unusual shows in the logs. Disabling all or most integrations and re-enabling one-by-one may be your best bet.
I think you could do that (make a backup first!). Once you reinstall ESPHome it should pick up all of your ESP’s connected to your network and prompt you to configure them. I think you’ll need to copy/paste the api encryption key from each one to get them to re-join.
500 devices connected? Are those mostly via wifi? That sounds like a lot of traffic being sent to HA. You could look at your ESP code and see if you can reduce the update_intervals.
Take a look at the Glances Add-On. It shows network utilization and TCP connections.
500 may have been a high guess, although it’s probably in the ballpark. I have 71 ESPhome devices in HA, 106 TP-Link Kasa devices, 34 Google Cast devices, 19 Onvif Cameras, and several other integrations with 1-20 devices.
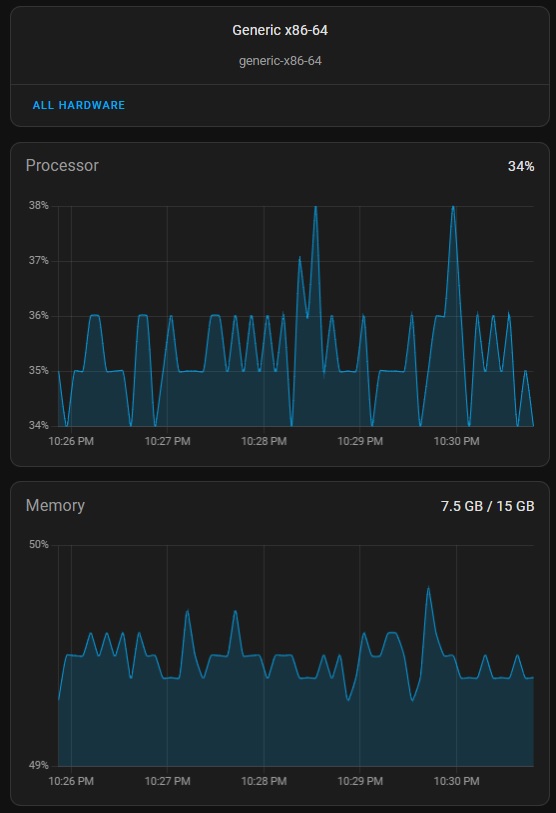
Here is the info from Glances. I’m not sure how to read this.
I see that Frigate is using a ton of CPU, but I have a Google Coral and I have the Frigate config setup to use the Coral
# Optional: Detectors configuration. Defaults to a single CPU detector
detectors:
# Required: name of the detector
coral:
# Required: type of the detector
# Valid values are 'edgetpu' (requires device property below) and 'cpu'.
type: edgetpu
# Optional: device name as defined here: https://coral.ai/docs/edgetpu/multiple-edgetpu/#using-the-tensorflow-lite-python-api
device: pci
For comparison, I’m running HA inside of Proxmox on an Intel NUC i5 running at 2GHz. My NIC shows 28 Kb receive per second while yours is 97.5Mb. My hassio shows 627 Kb transmit per second while yours is 85Mb. I only have 2 ESP devices and about 60 z-wave and zigbee devices. The other thing that stands out is your /config folder is 44.8 Gig and mine is 33.3 Mb. Take a look in that folder and see what file or folder is taking up all of that space.
Depends of what you are expecting. Deleting you sqllite ha database will certainly improve performance but you will loose your recorder, history, state, etc. data.
Your log file size on the other side should make you think. No doubt you have some serious misconfiguration in your system and your log probably contains lot’s of information how to tackle this down.
Also check out your recorder configuration (the docs explain this in detail) as it looks like you have a little too much recording going on inside ha (judging from a 17GB db file). For long term statistics you rather might want to check out a time series database like influxdb.
The .log file can’t be deleted as it’s the active logging file. It’s renamed to .log.1 at every restart. So you could delete that .log.1 file. It could be considered ‘large’ depending on how long HA was running before your last restart. You can open either one in Notepad and see what sort of events are being logged, and you can control the logger level by changing that value in configuration.yaml.
The .db file is your HA database file that contains all of your historical data. You would lose all of that if you delete it. I’m using the MariaDB Add-On instead, and my database size is 750MB keeping 7 days of history. 17GB sounds like a lot of history recording to me. You can control how long history is kept by using the purge_keep_days Recorder setting, as well as excluding entities that are filling that database with history that you don’t really require.
What does your HA NIC show for transmit and receive retries in Unifi network console? I would temporarily pause your camera streams and see if ESPHome starts responding quickly. I only have 2 camera feeds into HA just to provide a live view, and use Synology NAS to record everything. Wondering if 19 camera feeds are choking the NIC.
I think I’m at the point where I want to delete my Database file to see if that fixes it. I was keeping 60 days worth of recorder data due to some automations I’m running (like tracking my irrigation water usage. I lowered that to 40 days for now.
Do I need to do anything special to delete that file? Or can I just delete it and restart HA?
Instead of deleting it you could try lowering the number of days being recorded and then use the purge and repack options in config.yaml (followed by a restart):