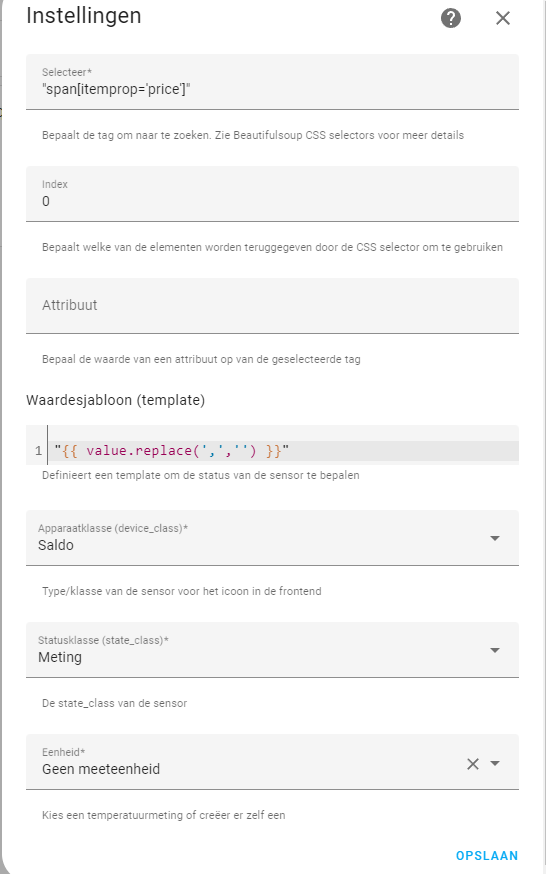
Hi
I want to know what my BTC balance is with the scrape functionality, but I’m unable to get the correct outcome unfortunately. The sensor is showing me unknown.
The website I’m trying to scrape (just an example of a wallet, so not mine ) 3FupZp77ySr7jwoLYEJ9mwzJpvoNBXsBnE - Bitcoin Address
When I open the developers view it’s showing me a valid html page (without cookie notification) so I think it’s OK for use.
Look at the page using View Source, not DevTools. Can you see the data in that HTML? If not, scrape cannot help you, because the data is being dynamically inserted using (probably) AJAX.
Reload the page in DevTools with the Network tab active, and look for requests of type xhr. One of those is probably a JSON or XML data set containing the data you want. Then use a rest sensor to read that — ask for help here if needed, but you’ll need to provide the data that’s being received. Redact anything confidential without changing the data structure.
Hi troon thanks for the reply. It looks like the data is still there when opening the page with View Source, but not readable. All those lines are displayed next to each other like this:
 ) 3FupZp77ySr7jwoLYEJ9mwzJpvoNBXsBnE - Bitcoin Address
) 3FupZp77ySr7jwoLYEJ9mwzJpvoNBXsBnE - Bitcoin Address