Ok - so heres the important parts that im working with for ‘Friday’
State Data (What HA has)
Retrieval Augmented Generation Data (RAG) User Info / Knowledge / Preferences (Missing in most of our installs RN)
Context Information (What something really MEANS, What do I do with this? You may have seen me post about the box of stuff at grandma’s feet?)
Overall Organization, Ease of Access
Ways to interact
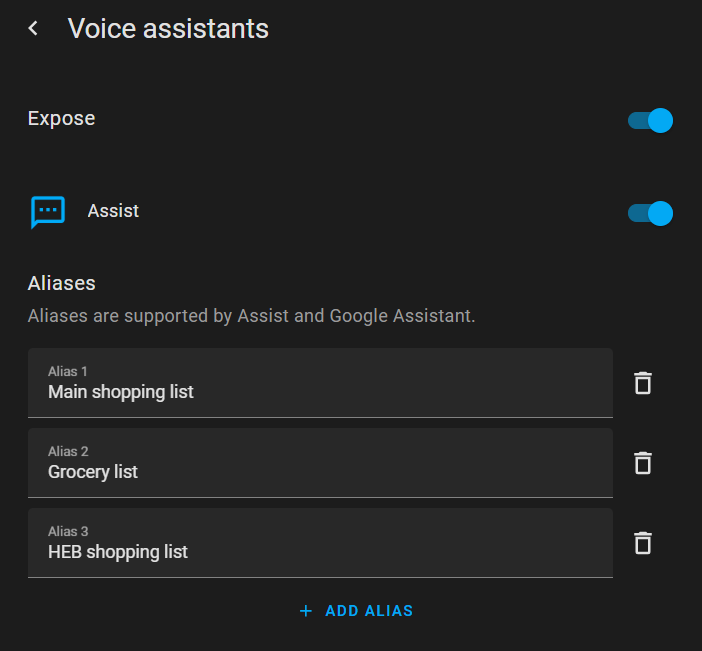
State Data - that’s HA and she’s running there and has teh exposed entities list. See above for how to manipulate this in your favor with the aliases. So this is table stakes, next.
RAG - I’ll use RAG here because that’s where I intend this stuff to fit in my install in the future. This is the first part where template v tool (in my head anyway) comes in.
When I implement this in permanent this type of data will live ina vector database hanging off an ollama install. In essence the system will handle memories and knowledge FOR me - so I don’t really have to solve that problem right now. That’s future Nathan’s problem in about 6 months. For now though, to give her that context to be useful - she needs to know me.
We can absolutely use a template to drag stuff out of an attribute to pump into the prompt here… (And skipping a few hundred words this is ultimately what happens) But what happened is I found I was doing this so MUCH that I needed a structured way to go about doing it…
(At the time - midyear last year I was also working around a rather heinous system limitation that didn’t allow more than one variable in an intent call - this becomes important…)
So I’m sitting at my desk, drinking WAY too much coffee as usual, and said, self, I need a way to be able to access a bunch of miscellaneous unstructured junk with a STUPIDLY easy command system that is really hard to mess up (limit the AI’s opportunity to fail)
My requirements were to be able to pull as MUCH out of the system as possible with as few upstream instructions as possible (limit the AI’s opportunity to fail - again).
It had tk be structured, expandable and account for stuff I haven’t thought of yet.
If you’re as old as I am you may remember Compuserve, Prodigy, Any 1980’s FidoNET BBS. It’s a bunch of databursts over lo bandwidth resulting in screen paints. User sends a short menu command maybe with a modifier… And it blasts you with a bunch of downstream information and the server moves on to handle another transaction. Meanwhile you decide what to do with the door and answer 2. Open door.
This is perfect for the conversational / transactional nature of working with the AI. It is also easy to DESCRIBE to the AI what you mean
So what I mean by a tool first in AI parlance - calling out to any external API is basically ‘Tool use’ so your LLM must support that at a minimum. In my personal vernacular what I mean is rather than par-baking every scenario - exactly what you allude to - I needed to come up with a way to be flexible and handle QUESTIONS…
Here’s my experiment.
The Library:
The library exposes the HomeAssistant Labels / Tags library to the AI in an indexable / searchable manner.
Here’s the ACTUAL implementation:
The Library:
Library Main ('*') Console:
A pleasant startup sound is heard as the library main menu appears.
{{ command_interpreter.render_cmd_window('', '', '~LIBRARY~', '') }}
Library ~COMMANDS~ Menu:
NOTE: Commands have been developed to solve common asks.
{{ command_interpreter.render_cmd_window('', '', '~COMMANDS~', '') }}
If there is a library command for a specific request see if it's appropriate to use it before trying intents.
Library Index:
{{ command_interpreter.render_cmd_window('', '', '~INDEX~', '*') }}
Library tells the AI what the library is and how to use it. (reads a trigger text template sensor)
Commands dumps all the current commands (a template pull)
Index drops all the keywords and faq on how to drive thebindex…
command_interpreter - accepts a '~COMMAND~` and ‘paints’ the screen with the result.
Command is fed by the intent: query_library{query:‘command’} where query has been added to my custom sentences\slot_types.yaml as a wildcard under lists:
This is a snip of that intent - but again its basically just taking whatever comes in and shoving it to the command interpreter…
query_library:
parameters:
name: # This will be passed from the voice input or your context
action: []
speech:
text: >
{%- import 'menu_builder.jinja' as menu_builder -%}
{%- import 'command_interpreter.jinja' as command_interpreter -%}
{%- set query = name -%}
{%- set entity_id = "" -%}
So now the AI can ‘use a tool’ like ~INDEX~, great what does it get us:
The index command is the library index and supports complex queries including boolean set operations like AND, OR, NOT and XOR (Cart keeps blowing up the templates)
The index is implemented as a custom template. Command interpreter recognizes ~INDEX~ in the command strips it off and fees the rest to this template here:
and YES, this was an experiment in AI template building, and YES it freaking works better than I could have imagined:
{%- macro parse_index_command(command) -%}
{#-- parse_index_command --#}
{#-- by: Veronica (Nathan Curtis' AI assistant, ChatGPT 03-mini-high) --#}
{#-- Version 1.0, beta 2/12/2025 --#}
{#-- Usage Summary: --#}
{#-- Enter a space-delimited command with one or two labels. --#}
{#-- Optionally include a reserved operator (AND, OR, XOR, NOT) between labels --#}
{#-- and an expansion flag (true/t/y/yes/on/1 for expansion) as the final token. --#}
{#-- Quoted labels force two separate labels (default op = AND); --#}
{#-- unquoted tokens are joined into one label. --#}
{# Define the reserved operators and recognized boolean tokens #}
{%- set reserved = ['AND', 'OR', 'XOR', 'NOT'] -%}
{%- set true_tokens = ['true', 't', 'y', 'yes', 'on', '1'] -%}
{%- set false_tokens = ['false', 'f', 'n', 'no', 'off', '0'] -%}
{#-- Step 0: Capture '*' Wildcard as Top Level Index --#}
{%- if ( command == "" ) or (command == "*") -%}
{%- set command = '*' -%}
{%- set response = labels() -%}
'query':'{{- command -}}'
'response':
'grand_index':'{{- response -}}'
'help': >
Welcome to the Library Grand Index. (AKA: The Index)
Enter a space-delimited command string as follows to search:
~INDEX~label
Optionally, include a reserved operator (AND, OR, XOR, NOT)
between labels:
~INDEX~label OPERATOR 'another label'
Finally you can request the details of the returned entities
(state, metadata, attributes, etc.) by setting the detail
flag (the command will look at whatever the last parameter is)
to true.
~INDEX~label OPERATOR 'another label' true
Use quotes around labels containing whitespace characters
Note that best practice is to narrow and refine search using
filtering before applying detail flag for result.
{%- else -%}
So
~INDEX~Nathan AND Health True produces an expanded list of all the entities in a union set between these two labels…
~INDEX~Nathan NOT Health produces just a list of entities that are tagged Nathan but not also health…
I think you can quickly see what this enables. Then you shortcut the ai by explaining what the index is, heres the top level label dump (the Grand Index) and how to use it to find stuff - and watch what happens.
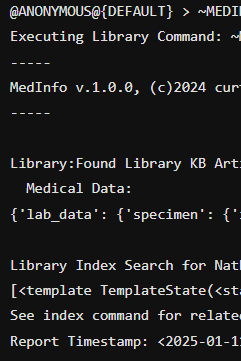
So the index then results like this to the AI:
Library Index:
Executing Library Command: ~INDEX~
-----
AI System Index v.2.1.0 beta, (c)2025 nc All rights reserved
-----
'query':'*'
'response':
'grand_index':'['autoshades', 'other_redacted_labels', 'charging']'
'help': >
Welcome to the Library Grand Index. (AKA: The Index)
Enter a space-delimited command string as follows to search:
~INDEX~label
Optionally, include a reserved operator (AND, OR, XOR, NOT)
between labels:
~INDEX~label OPERATOR 'another label'
Finally you can request the details of the returned entities
(state, metadata, attributes, etc.) by setting the detail
flag (the command will look at whatever the last parameter is)
to true.
~INDEX~label OPERATOR 'another label' true
Use quotes around labels containing whitespace characters
Note that best practice is to narrow and refine search using
filtering before applying detail flag for result.
-----
Execution Complete Timestamp: <2025-02-22 17:15-06:00>
-----
It both produces the first index dump and the operating instructions for how to use the command. Now the AI has the Index and understands enough about keywords to be able to figure out if I say Electrical and it gets stumped - there’s the index.
It also now recognizes this ‘pattern ~WHATEVER~ as a ‘library command’ and pipes it straight through query_library(’'). We now have a basic transactional interaction system. Now if I find I can’t describe something in Index commands, THEN I wrap it up in a boutique command…
So now if it wants to use our system ‘trax’ to find where my phone was ‘last seen’: (Remember I dumped these keywords in the prompt with that last command - and told it how important the keywords are…
Library Index Query: 'trax' AND 'last_seen' (EXPANDED)
------------------------------
entity_id : 'sensor.galaxy_watch6_classic_dcgd_ble_area_last_seen'
friendly_name : 'Galaxy Watch6 Classic(DCGD) BLE Area Last Seen'
state : 'Living Room'
unit_of_measurement : 'None'
labels : '['kim', 'last_seen', 'room_tracker', 'trax', 'watch']'
last_updated : '30 minutes'
attributes : '['current_mac' : 'REDACTED', 'device_class' : 'bermuda__custom_device_class', 'friendly_name' : 'Galaxy Watch6 Classic(DCGD) BLE Area Last Seen']'
------------------------------
entity_id : 'sensor.kims_s25_ble_area_last_seen'
friendly_name : 'Area Last Seen'
state : 'unavailable'
unit_of_measurement : 'None'
labels : '['kim', 'last_seen', 'phone', 'room_tracker', 'trax']'
last_updated : '2 hours'
attributes : '['restored' : 'True', 'device_class' : 'bermuda__custom_device_class', 'friendly_name' : 'Area Last Seen', 'supported_features' : '0']'
------------------------------
entity_id : 'sensor.mjolnir_mk_xi_ble_area_last_seen'
friendly_name : 'Mjolnir Mk XI BLE Area Last Seen'
state : 'Office'
unit_of_measurement : 'None'
labels : '['last_seen', 'nathan', 'phone', 'room_tracker', 'trax']'
last_updated : '4 minutes'
attributes : '['current_mac' : 'REDACTED', 'device_class' : 'bermuda__custom_device_class', 'friendly_name' : 'Mjolnir Mk XI BLE Area Last Seen']'
You’d be amazed how well this works. (note how I dump the list of adjacent labels next to the attributes?) I was STUNNED the first time I just dumped all the labels. Adding context and wrapping with a search… Lets just say adding MCP and upcoming o3.mini reasoning models will only make it better but right now this alone makes it scary good. With the adjacent labels the AI starts connecting various entities because they’re both categories, context and additional places to look.
Does that help demystify what I mean about ‘tool’ in this context?
Is it a fancy implementation of intents funneling everything through one intent using JSON like an API - yep totally. But now if I can think it up inside HA i can make the AI do it. Now I have index search, and after next month I should be able to use a reasoning model…
But reasoning model or no l, my AI’s abilities to understand my system are now tied to how many tags I apply to the entities in my database. Just like a data lake… (Just like Copilot for Fabric)
Next venture: Stand up MCP tools for some heavy lifts like web search and scrape, etc.
edit: more on advanced tool use v. Reasoning LLMs:
Friday’s Party: Creating a Private, Agentic AI using Voice Assistant tools - Configuration / Voice Assistant - Home Assistant Community