Is that something that can be changed via the UI somewhere?
With Gemini model I am getting an “unsupported action” when trying to set a timer. Is that expected? Thanks
it’s hardcoded:
@jose1711 Unfortunately HA doesnt have a good timers framework that assist can connect into yet. There are tools for start and stop, but not for create or managing notification etc.
@sparkydave @jose1711 - I’ve added a setting to adjust the entity limit - Release v0.15.4 - Configurable Entity Discovery Limit · mike-nott/mcp-assist · GitHub
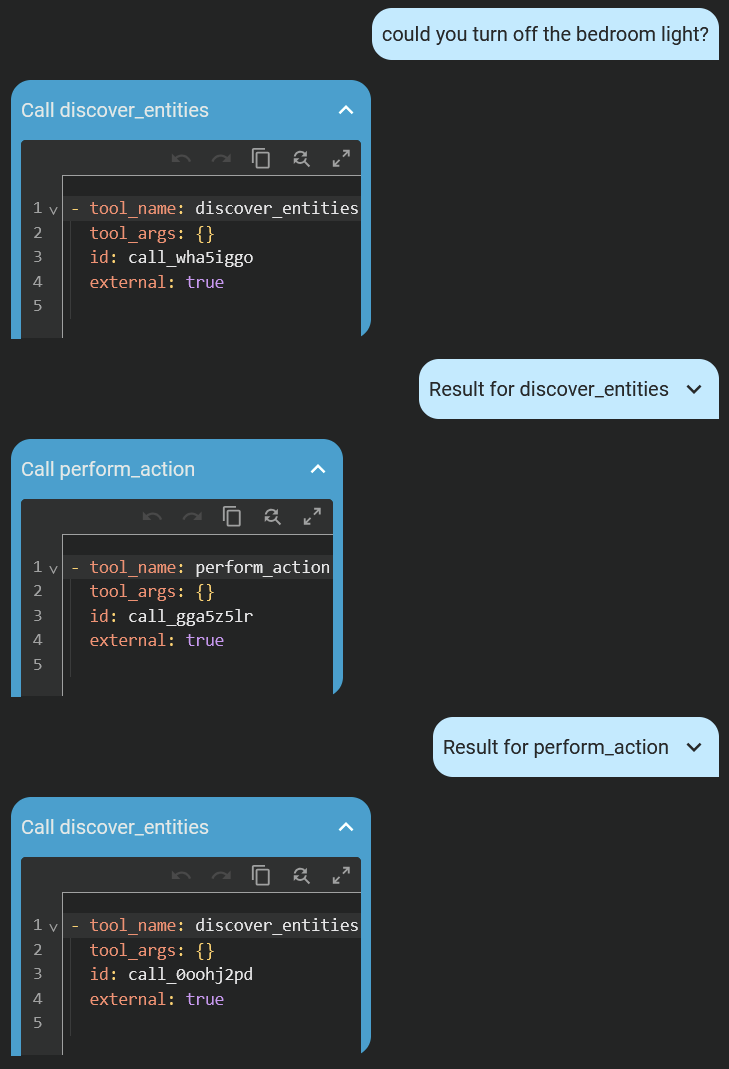
@mikenott Hey, I’m not sure why but it looks like the AI isn’t sending arguments to the tool calls so it justs keep executing them over and over until it reaches the limit
related. I use a local LLM with a cache. I have about 90 entities exposed, a few are extensive. I just asked about the rain totals and then answered one question. 2040 tokens were pulled from the cache and 112 were produced. Between HA and openclaw the LLM server runs 90-94% cache rate. oMLX for MacOS. (qwen3.5 35b for HA and Qwen3,5 122b for openclaw).
I don’t know my final architecture, but openclaw looping ability has possibilities that HA doesn’t. For example, “Check the rainfall totals every 30 minutes and turn on the bedroom lights if rainfall exceeds 4 inches. Delete this check at 7am” actually works so far.
I can’t find a place to put the API key for llama.cpp when adding my model. I can get everything added initially but get the error about the API when trying to use the assistant.