Total newb here especially when it comes to programming (but willing to learn), please bear with me!
I want to be able to listen to music using my Sonos speakers and Plex integration, while also receiving TTS announcements. As it is now, the TTS announcement replaces the music being played, and I will then have to pick a new song from Plex manually in order to keep listening.
I realize this has been discussed here before, but the solutions appear mostly quite old and possibly no longer functional. I also didn’t see anything specific to using Cloud TTS instead of Google TTS. I found an integration solution made by kevinvincent. in one of the threads, but while it works great for Google TTS, the problem is that I much, much prefer to instead use the more natural and nicer sounding Cloud TTS that comes with the Nabu Casa subscription.
kevinvincent’s above solution relies on a server being created alongside HA that processes the TTS, and that way as I understand it, it works more or less by simultaneously playing both files, my music on Plex with Sonos, and the TTS clip processed on the lateral server. I can’t find any way to change the setting to Cloud TTS, though.
I’ve been trying to come up with a solution… To start with, there are a few issues that come to mind:
- I have seen no way of editing an integration within HA in order to try and change the TTS service used. It’s currently looking like it’s not worth attempting, considering the below point.
- Ability to use Cloud TTS is tied to my Nabu Casa subscription, which is single user. I would guess that means that this server wouldn’t be able to access it as it isn’t freely available.
- Use “pre-printed” TTS clip sound files. This would sadly remove the ability for the TTS to announce any real time things such as outside temperatures - not ideal.
Two possible solutions come to mind:
- Process the TTS within my HA instance, then send the file over to the server, from where it will then be played over the Plex music playing on Sonos speakers. This seems like a fiddly solution, possibly causing tons of latency on the TTS announcements, but I imagine it’s at least possible?
- Abandon the idea of using this solution and try another script. I have little experience working with scripts so I would have to largely rely on the good community here.
Speaking of trying a script, I found the following from here, posted by @ianadd :
test_tts:
alias: Test for TTS
sequence:
- service: script.turn_on
entity_id: script.say
data:
variables:
where: 'office'
what: 'Test.'
say:
alias: Sonos Text To Speech
sequence:
- service: sonos.snapshot
data_template:
entity_id: "{{ 'media_player.' ~ where }}"
- service: tts.google_translate_say
data_template:
entity_id: "{{ 'media_player.' ~ where }}"
message: "{{ what }}"
- delay:
seconds: 1
- delay: >-
{% set duration = states.media_player[where].attributes.media_duration %}
{% if duration > 0 %}
{% set duration = duration - 1 %}
{% endif %}
{% set seconds = duration % 60 %}
{% set minutes = (duration / 60)|int % 60 %}
{% set hours = (duration / 3600)|int %}
{{ [hours, minutes, seconds]|join(':') }}
- service: sonos.restore
data_template:
entity_id: "{{ 'media_player.' ~ where }}"
It looks like it could work according to my limited knowledge, but I keep getting an error saying “extra keys not allowed”. It could be any mistake, but I’m also wondering if a script all the way back from '19 would still work today as HA is constantly being updated.
I would love some help on this! At this point this feature is pretty much the only major thing I’m missing at the moment. Thanks in advance!
 from what I’ve seen using Google, this could be a spacing issue or something like that, but I wonder why it works for your HA setup and not mine?
from what I’ve seen using Google, this could be a spacing issue or something like that, but I wonder why it works for your HA setup and not mine?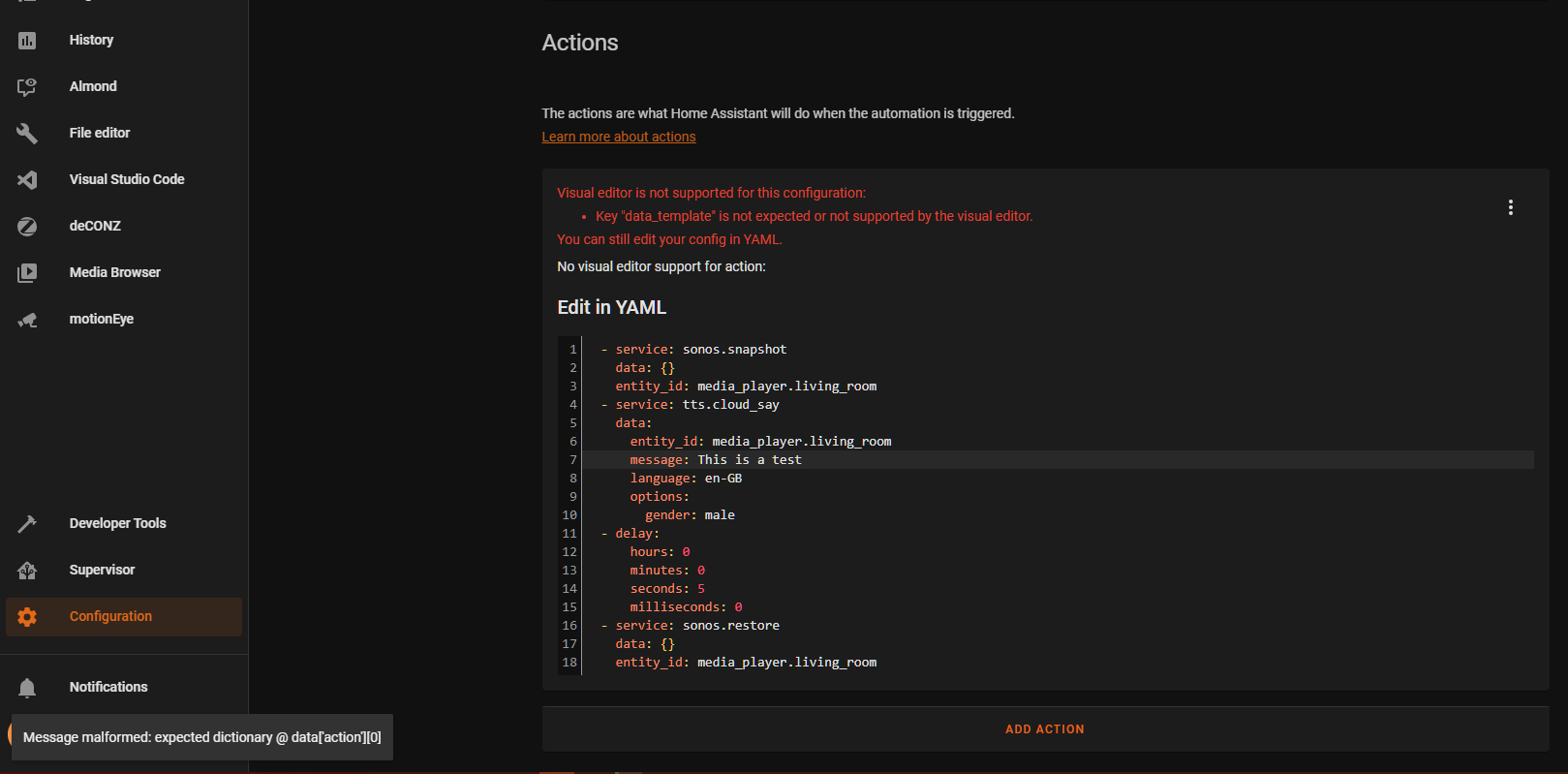

 I’m starting to lose my mind a bit with this to be honest - I can’t wrap around my head why a piece of code works for someone else but not for me once I’ve changed the entities and things to match my setup.
I’m starting to lose my mind a bit with this to be honest - I can’t wrap around my head why a piece of code works for someone else but not for me once I’ve changed the entities and things to match my setup.