Hi guys,
Since a few days, my node-red is been having some problems. Whenever I restart home-assistant, it is not able to start node-red for some reason. In the log of node-red I see this:
14 Aug 10:15:05 - [red] Uncaught Exception:
14 Aug 10:15:05 - [error] UnhandledPromiseRejection: This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). The promise rejected with the reason "#<Object>".
[10:15:06] WARNING: Node-RED crashed, halting add-on
[10:15:06] INFO: Node-RED stoped, restarting...
s6-rc: info: service legacy-services: stopping
[10:15:06] INFO: Node-RED stoped, restarting...
s6-svwait: fatal: supervisor died
s6-rc: info: service legacy-services successfully stopped
s6-rc: info: service legacy-cont-init: stopping
s6-rc: info: service legacy-cont-init successfully stopped
s6-rc: info: service fix-attrs: stopping
s6-rc: info: service fix-attrs successfully stopped
s6-rc: info: service s6rc-oneshot-runner: stopping
s6-rc: info: service s6rc-oneshot-runner successfully stopped
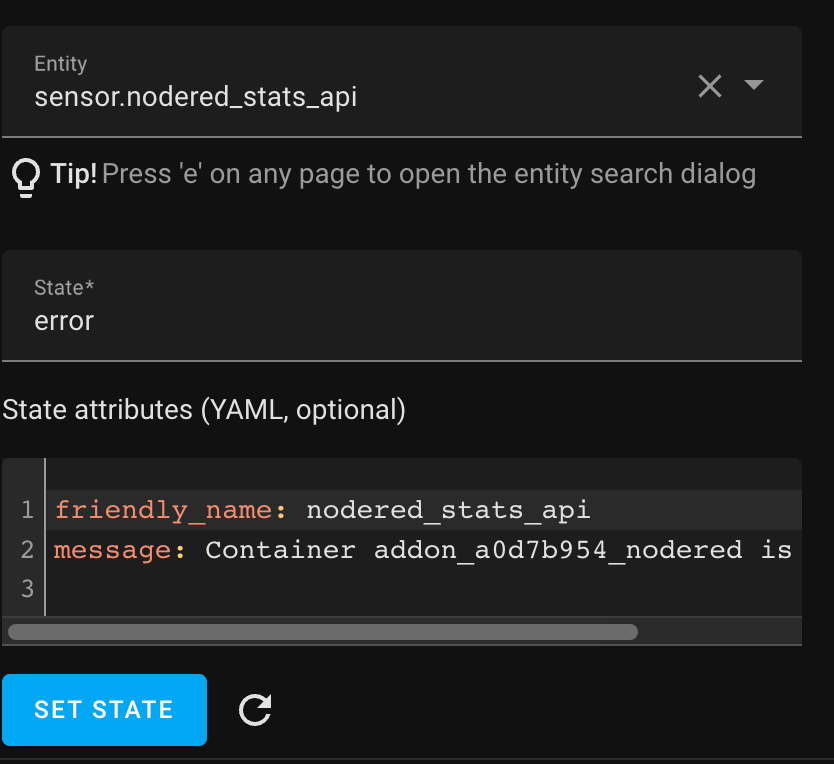
Right before this there are also some entity API errors like this, but I don’t know if this causes the crash:
14 Aug 10:15:05 - [error] [ha-entity:*entity-name*] Entity API error.
After this, I can just start the node-red add-on manually and it runs fine until I restart home-assistant again.
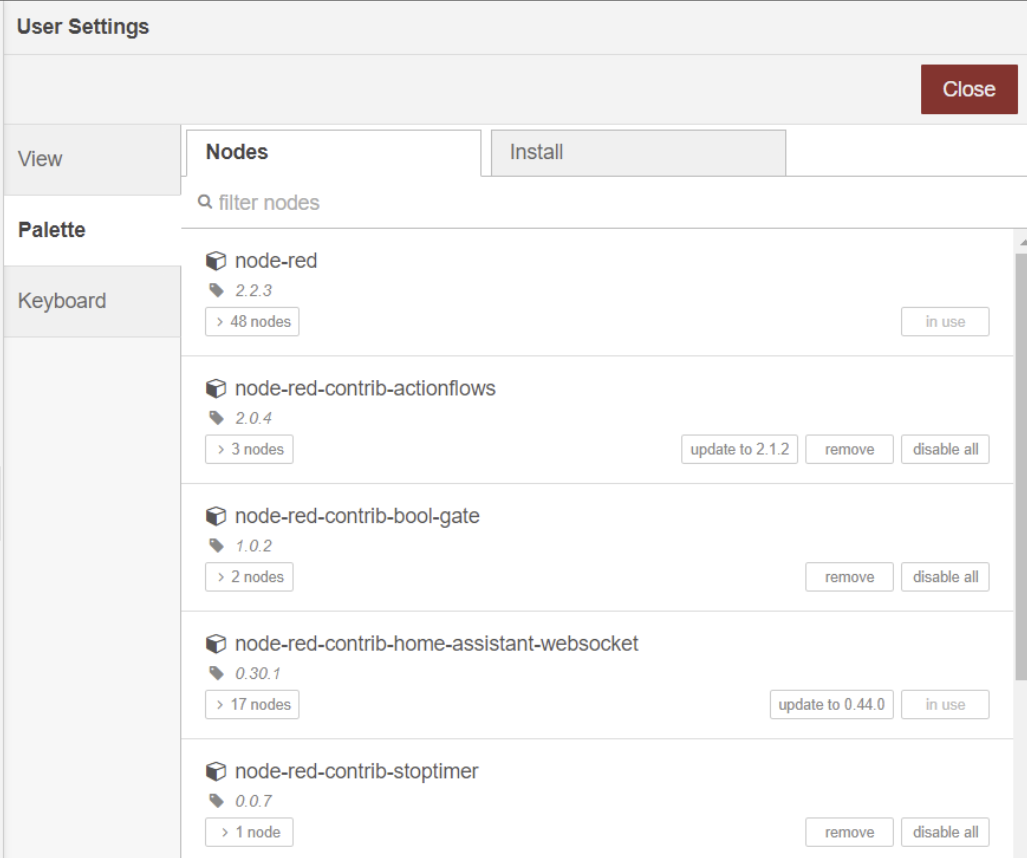
Does anyone have an idea if a faulty node could cause this, and if I can find this node somehow?