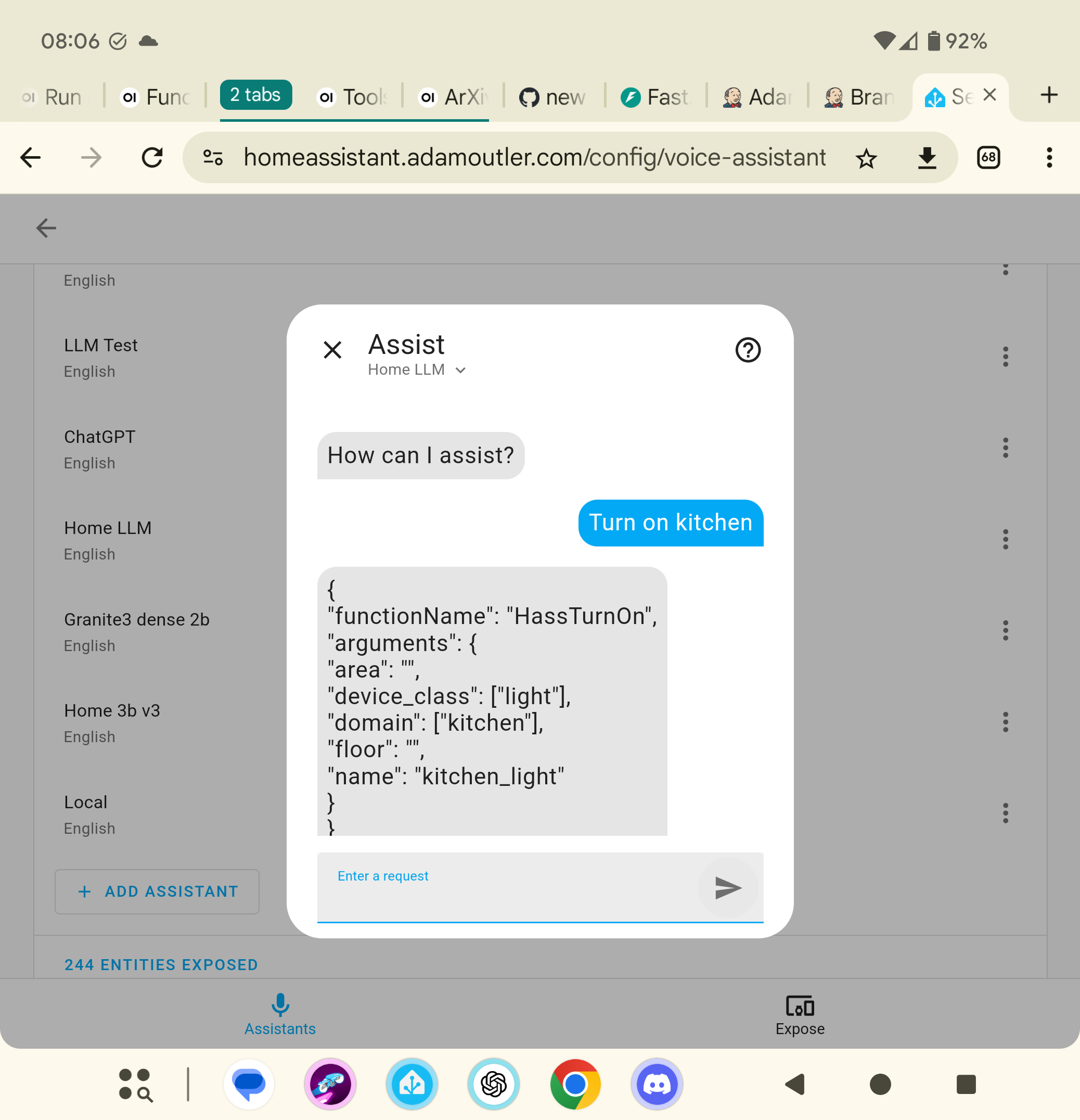
I’ve tried systematically changing each configuration option on multiple LLMs with multiple versions of Ollama and LocalLLM configurations and despite claims from multiple integrations I’ve yet to see any proof Local LLMs work with HA.
What configuration actually works? Where are the LLM expected outputs documented?
Following since I’m getting started on this myself.
Have you verified your local LLM is responding to queries in a timely manner? e.g. if your system is underpowered for the size of the LLM you’re running, it won’t respond or will take many many minutes to respond.
I can get replies too, just it hallucinates the reply. I’m using ollama with llama 3.1. The issue is I have over 100 entities. There is a recommendation for less than 25. What this looks like it needs a new architecture, for example a RAG.
As I understand it, the states are passed as a system prompt to the llm and that will overflow the token count. Doesn’t seem to be well optimized.