Hi there,
since the release of the HA Voice Preview Edition I was looking for a possibility to redirect the replies of Voice PE to a Sonos speaker, as the quality of the builtin speaker is not sufficient. There was some information available about how this might be done, but no detailed information how to do it. So here it is (put together with some AI help)!!!
What does it do?
- All replies Voice PE gives to a question are redirected to a sonos speaker of your choice
- Only the mic of the Voice PE is used
- The standard sounds of the Voice PE are output through the builtin speaker as usual
How does it work?
Configuration
- You choose the sonos speaker to output the Voice PE replies
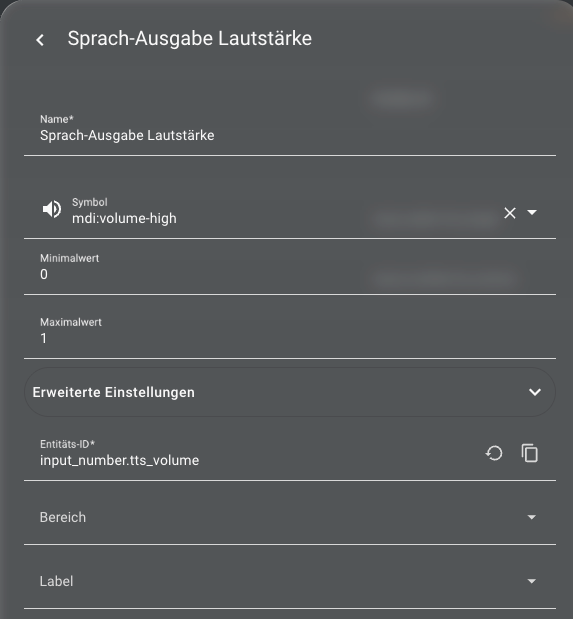
- You choose the volume the replies should have on your speaker
Usage
- You ask Voice PE a question
- The reply is played via the sonos speaker
Flow
- Voice PE mutes the output sonos speaker (to silent the speaker if it is playing, so Voice PE can understand your question)
- Voice PE creates the reply using the LLM you configured (as usual)
- Voice PE speaker is set to 0,0 (this is needed as the output through the internal speaker is not cut, but only muted as long as the answer takes)
- The reply is redirected to a Home Assistant script
- The script
-
- unmutes the output sonos speaker
-
- snapshots the state of the output sonos speaker
-
- plays the reply
-
- restores the sonos speaker state from the snapshot
-
- sets the volume of the Voice PE builtin speaker to 50%
What is the advantage of this solution?
- The sonos speaker can be chosen via HA dashboard
- The volume of the reply on the sonos speaker can be chosen via HA Dashboard
- The HA script can easily be tweaked to your needs without needing to reinstall the Voice PE YAML after every change
What must I do?
- Add your Voice PE to ESPHome Builder (search Web on how to do it)
- Edit your Voice PE YAML
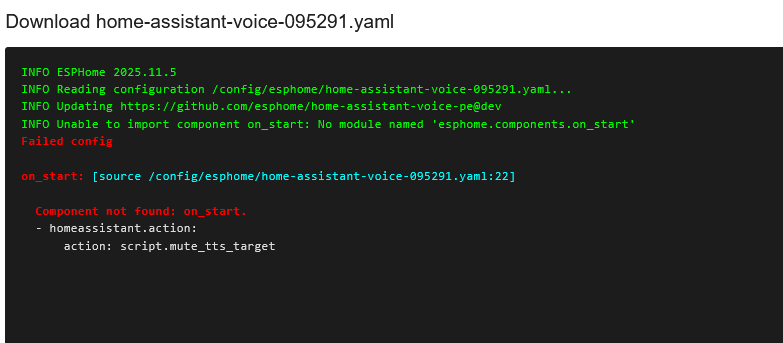
- Add the following lines at the end:
# Mute output speaker
on_start:
- homeassistant.action:
action: script.mute_tts_target
# Mute Voice PE internal speaker
on_tts_start:
- media_player.volume_set:
id: external_media_player
volume: 0.0
# Start HA script and hand over URL with Voice PE reply
on_tts_end:
- homeassistant.action:
action: script.voice_assistant_sonos
data:
url: !lambda 'return x;'
- Install the YAML (may take some minutes)
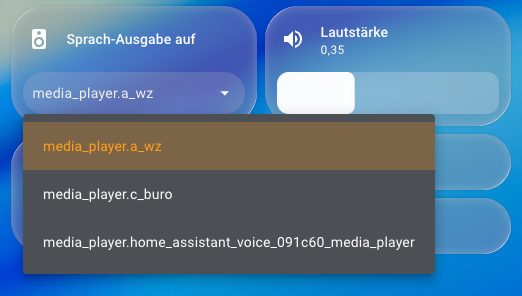
- Create two helpers for speaker select and volume select (Replace the media_player entities with the sonos speakers of your choice)
- Create the HA script “voice_assistant_sonos”:

sequence:
- variables:
target: "{{ states('input_select.tts_target') | default('media_player.a_wz') }}"
vol: "{{ states('input_number.tts_volume') | float(0.35) }}"
- action: sonos.snapshot
data:
entity_id: "{{ target }}"
with_group: true
- action: media_player.volume_mute
metadata: {}
data:
is_volume_muted: false
target:
entity_id: "{{ target }}"
- action: media_player.volume_set
data:
entity_id: "{{ target }}"
volume_level: "{{ vol }}"
- data:
entity_id: "{{ target }}"
media_content_type: music
media_content_id: "{{ url }}"
action: media_player.play_media
- delay:
hours: 0
minutes: 0
seconds: 2
milliseconds: 0
- wait_template: "{{ not is_state(target, 'playing') }}"
timeout: "00:10:00"
continue_on_timeout: true
- data:
entity_id: "{{ target }}"
action: sonos.restore
- action: media_player.volume_set
target:
entity_id:
- media_player.home_assistant_voice_091c60_media_player
data:
volume_level: 0.5
alias: voice_assistant_sonos
mode: queued
fields:
url:
description: Audio-URL of Assist-Reply
example: https://…/tts.mp3
description: ""
This script plays the Voice PE reply on the sonos speaker
Replace media_player.home_assistant_voice_091c60_media_player with the entity of your Voice PE
- Create the script “mute_tts_target”:
sequence:
- variables:
target: "{{ states('input_select.tts_target') | default('media_player.a_wz') }}"
- action: media_player.volume_mute
metadata: {}
data:
is_volume_muted: true
target:
entity_id: "{{ target }}"
alias: mute_tts_target
description: ""
This script mutes the sonos speaker after the wake word, so Voice PE mic can understand you better.
I also created a little dashboard using the Voice PE entities and the helper entitites

That’s it!!
Please share your thoughts and experience if you try it out
Disclaimer: If you try it out this is of course at your own risk!
P.S.: This script is for sonos only, but it should be easy to port it to your speaker type as long as it can play back an URL stream
Cons of this solution
- The reply is starting the after it is completely processed by the LLM (I think that is also happening on Voice PE itself(?) - so no direct streaming)
- You cannot stop the reply by pressing the Voice PE button (This may be implemented in a future release
 )
) - The internal Voice PE speaker is restored to a default 0,5 volume after the reply, but that can be adjusted in the script.