Is it possible to have the template sensors compute over historic data? If not, how do you clean up the starting data that the new sensors had before they started updating (assuming the source of the values).
{ edit } - I really would rather see historic data, but worst case cleaning up that init data allows me to see current data as the graph will be scaled correctly to see the line variances.
Been over 24 hours and they are only showing data from when i created the template sensors.
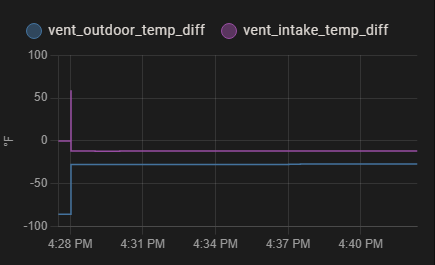
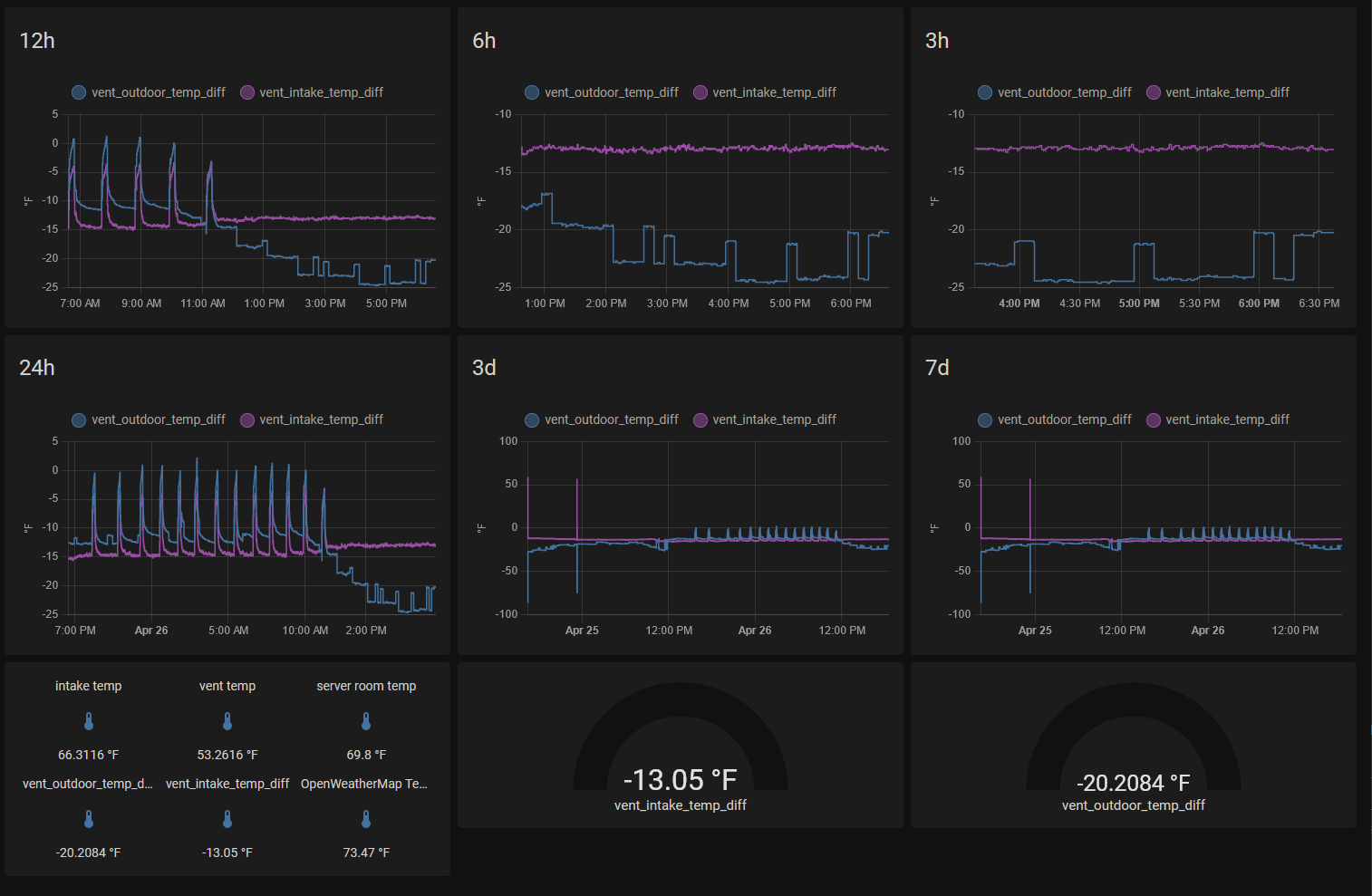
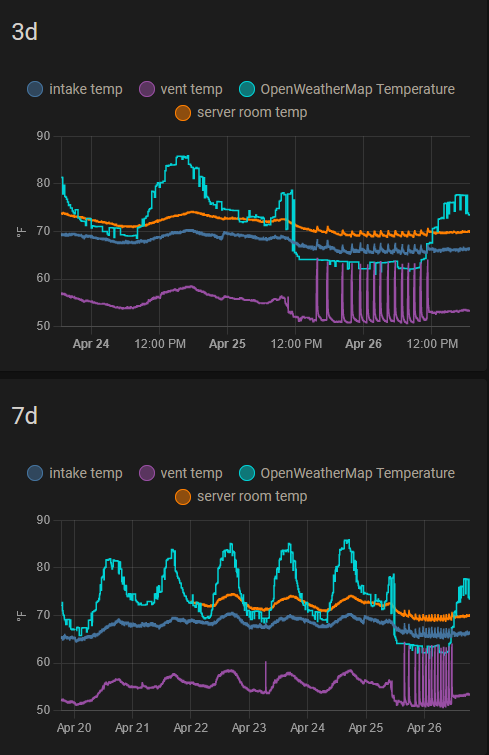
The huge spikes right after they were created and right before the 25th are a bigger problem than lack of historic data. I assume it is some kind of timing thing where one sensor updated before the other causing the template to trigger generating bad data? Second image shows that the data from then is normal.
A cool front came thru so current data is abnormal (2 image for reference on this too).
You could add an availability template to your template sensor to make the state unavailable if either sensor it depends on is unavailable. This will produce gaps in your graph rather than spikes.
i need to add that availability clause to the template sensors to avoid the race condition or whatever is causing spike (and probably a script that fills in the gaps with an average of the values on either side, or just manual if it is a super rare thing (so far only the 2 have happened))
template sensors do not retroactively fill data even if the sources that they pull from do have historic data. I would need to edit the db to back fill it in
the db only holds 10 days, so if i want full data kept i need to either write an export thing to keep it backed up on a db i spin up elsewhere (or local file to be ingested later), or change the back end db? I’m looking at migrating my from scratch thermostat (GitHub - G4te-Keep3r/thermostat) to home assistant (for a variety of reasons). Part of the eventual plan with that project is applying some machine learning, which in the way i want to use it requires the historical data. I’m at a different place than where that was done so currently learning the nuances of the new place and looking at how to evolve the project. Can I just set the recorder db to keep indefinite or does it cause performance issues and i need to look into using a different db backend?
It’s not a race condition, you will get spikes if one of the sensors is unavailable.
Correct. Template sensors only record states from when they were first loaded.
You can increase the recorder purge_keep_days option. I wouldn’t recommend more than a month or so though, unless you have fast hardware. Use InfluxDB and Grafana for long term storage (if long term statistics does not fit your needs). Takes about 15 minutes to set up. My only additional advice to this tutorial is to use includes in the InfluxDB configuration to only include entities you are interested in long term storage for. https://youtu.be/m9qIqq104as
With the advanced functions in grafana, at some point i will remove the diff sensors. Currently grafana/influx are working, but data is still going into recorder while also going into influx. I haven’t yet migrated historic data to influx, so purge_keep_days is set to 60 (at 30 and 43 days didn’t seem like a problem, it is running in a VM on unraid server). Is my configuration wrong that is causing it to write data to both places still?