Oh, and while I’m at it, I have an Echo Wall Clock that’s only ever used as a wall clock but chews up 2 to 3 sets of 4xAA batteries annually. It keeps accurate time but so do my Atomic clocks which only use 1xAA battery every 12+ to 18 months…
Fair enough. The quality of Alexa and Google devices is (so I understand) far superior to any of the current alternatives. And HA Voice Assist is still being developed, so there are a number of features still to be added.
The reason some of us are enthusiastic about HA Voice Assist is that it does NOT rely on servers owned and operated by multinational companies out of your control.
We accept that it’s not there yet, but check back in 6 or 12 months…
2 Likes
Don’t get me wrong, HA Voice Assist is exciting and I’ll continue to keep tabs on it but it’s just not there yet, for me and my use cases. I bought a Muse Luxe speaker for Voice Assist but it was a major disappointment/failure. Maybe one day Nabu Casa cloud can replace Alexa/Google cloud services thus eliminating the need for expensive local hardware for voice analysis, but they are currently free (although that could change any day now) and Nabu is not. At CA$8.70/month, that’s two fancy coffees at Starbucks!
you don’t need to pay to much to have all your data stolen ![]() go for it
go for it
Just remember you are NOT the customer, Alexa/Google are, that’s why they are prepared to basically give away their expensive hardware.
Hi everyone, I’ve also tried to run the language assistant backend on external servers. I am trying to use a webbased server, though, outside my home network an in a data center. I have read through this thread but have not stumbled upon anyone doing this - or did I miss something?
Either way, I am getting very slow response times on stt and was wondering if any of you have any idea on how to fix this?
Thanks and cheers!
Are you limited to NVIDIA GPUs because of the CUDA requirement?
I would prefer to use an NPU or something less power hungry if possible.
1 Like
CUDA=nVidia.
These GPU solutions take VERY little power to process the short sentences we throw at Assist. They operate at P2 for less than a second and then go back to idle mode. We aren’t playing video games here. FWIW, you can find used nVidia GTX1070 cards on eBay for $50-80 (I bought one a month ago) and they work GREAT. Pop it in an old tower you’re about to chuck out and you’re golden. I’m using an old Dell Optiplex from 2011 and it’s snappy.
Anyone trying to use truly local STT will be required to use a GPU or suffer intolerable delays when processing local speech. The processing power required to do inference on voice patterns is highly processor intensive, and GPUs are perfectly suited for the exactly this. CPUs just aren’t up to the task and likely never will be, at least not with all of the current CPU architectures being used. Good user voice experience requires sub-second response times. This is a very hard problem to solve, both in sw and in hw.
It’s nice to see someone has cracked the GPU nut with Whisper. I got so frustrated with the acrobatics required to do all of this in HA that I’ve jumped on the Willow+HA bandwagon and am not looking back. When I say 15 minutes from setting up the Box3 device to HA recognizing complex commands in Willow in less than 300ms, I’m not kidding. That assumes you have Ubuntu installed. And Willow now allows “Pipeline Chaining” meaning the dreaded “I can’t understand that” gets passed to Alexa or Google if you want an answer to some random question without coding custom intents for days.
All of these voice solutions will RADICALLY improve over the next year. Rome wasn’t built in a day, and just remember when (for some of us) HA was at version 0.0x… it’s progressed by light years since then. The same thing will happen with voice, but on an accelerated timetable.
4 Likes
Interesting, I am trying to power the device via PoE++ (IEEE 802.3bt) which limits me to 60W for the entire machine.
Currently I am running Home Assistant bare metal on a N5105 box powered by PoE which has been great. I have Whisper and such installed, but my CPU usage does not appear to spike over 25% when processing requests (¿single threaded?). The processing time for the request and speech response is too long compared to our existing Amazon Echoes despite using the lightest models.
Ideas on how to create something are welcome. I know it is a near impossible goal (for now).
I set up Wyoming faster-whisper, piper and openwakeword today. All using GPU accel on a GTX 1660 TI. It’s fast, I just need to figure out what models I can use with it. The rhasspy models repo Releases · rhasspy/models · GitHub seems to only go up to medium/medium-int8.
At the moment, pipers python lib doesn’t accept the --cuda arg even though the CPP side of it is implemented. You need to bind mount a custom __main__.py and process.py into the custom-built piper docker container for piper to use GPU. I have the GPU accelerated Wyoming containers on a separate host than HASS. So remote does work. Add whisper and piper using the Devices & Services → Whisper / Piper pipeline. To add a remote openwakeword server, Devices & Services → Wyoming Protocol and enter the remote IP and PORT.
For the person asking about the remote data center stuff, you would need a VPN connection as I don’t think there is any auth mechanisms for the Wyoming containers but, it is technically possible and latency would be whatever your pings are + processing time.
Here is my repo that I used to deploy the GPU accelerated containers (don’t forget you need nvidia-container-toolkit installed to pass GPU to docker): GitHub - baudneo/wyoming-addons-gpu at gpu
You should only need to clone the repo: git clone https://github.com/baudneo/wyoming-addons-gpu, cd wyoming-addons-gpu into it, make sure you are using the gpu branch: git checkout gpu, and then run docker compose -f docker-compose.gpu.yml up and see if it builds properly. You can add the docker compose -d flag after you know the containers are built properly.
git clone https://github.com/baudneo/wyoming-addons-gpu
cd wyoming-addons-gpu
git checkout gpu
docker compose -f docker-compose.gpu.yml up
If the container builds fail, you need to remove the build envs that are cached. I had to remove the containers, then the custom-built images and run docker system prune to remove the cached build environments before I could rebuild the containers when there were issues. To rebuild, I was using docker compose up --build --force-recreate.
The piper --cuda arg should be implemented soon so the bind mounting of __main__.py and process.py int the piper container shouldnt be needed in the future but, it is for now.
Edit: I tried using ‘large-v2’ as the model parameter, and it throws an error:
__main__.py: error: argument --model: invalid choice: 'large-v2' (choose from 'tiny', 'tiny-int8', 'base', 'base-int8', 'small', 'small-int8', 'medium', 'medium-int8')
So it seems medium(-int8) are the best choices ATM. medium-int8 is taking up 908MB of GPU memory →
Tue Dec 26 18:23:33 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1660 Ti Off | 00000000:3B:00.0 Off | N/A |
| 0% 41C P2 24W / 130W | 1859MiB / 6144MiB | 2% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 81077 C /usr/bin/zmc 70MiB |
| 0 N/A N/A 193753 C /opt/zomi/server/venv/bin/python3 474MiB |
| 0 N/A N/A 2115758 C python3 908MiB |
| 0 N/A N/A 3022347 C /usr/bin/zmc 246MiB |
| 0 N/A N/A 3022370 C /usr/bin/zmc 158MiB |
+---------------------------------------------------------------------------------------+
3 Likes
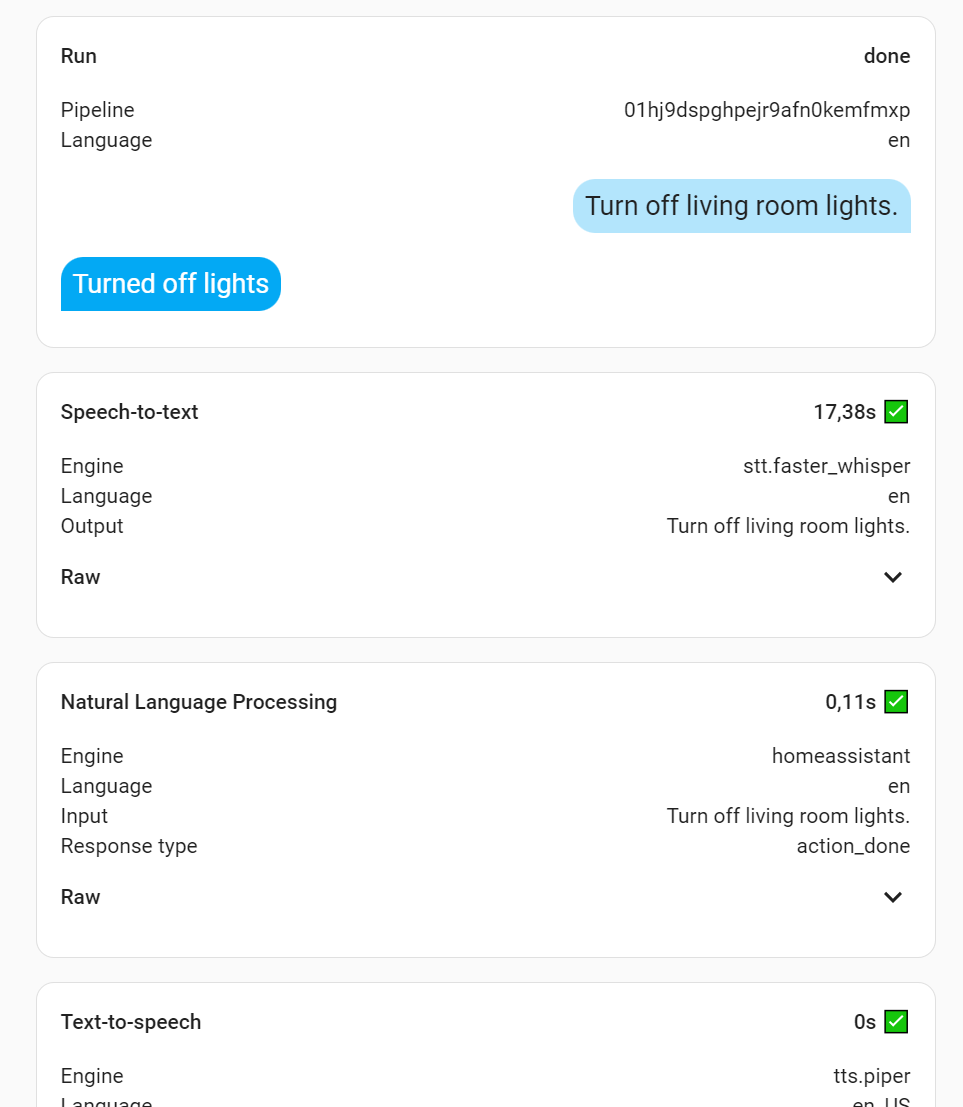
How did you get the performance numbers in your post? I’ve set up an external whisper and I’d like to see how much time is being spent in each step of the pipeline.
Go to Settings → Voice Assistants → Click on your faster-whisper assist pipeline. When the pipeline modal pops up, there will be a 3 dot menu button in upper right hand corner, click it and select Debug.
It will take you to the debug screenw here you can see runs and proc times.


3 Likes
I’ve set up piper, whisper and openwakeword using your repo as a git submodule (my own docker-compose file extends your docker-compose.gpu.yml) and everything works great. I get almost instantaneous responses with the tiny-int8 model. Using the medium-int8 model, the processing time is around 4 seconds which is reasonable considering I’m using a Nvidia Quadro P400.


Thanks a lot for sharing your work!
For a quick experiment I had my Raspi connect to the data center unencrypted, the whisper processing just took forever, 4 times as long as compared to local on Raspi. Not sure what was going on here, the connection was fine. Maybe my virtualised server environment is really not well equipped for the respective processing.

Is your VPS GPU accelerated? Or cpu only? Try going into the assist pipeline debug and seeing how long each step is taking.
If your VPS is GPU accel, run watch -n .1 nvidia-smi and watch the GPU mem and GPU utilization % during voice processing to make sure the GPU is handling the calls.
If it’s cpu based, than the cpu or network connection is probably the bottleneck.
No, I don’t have any Jetson hardware to test with. It shouldn’t be too hard to modify the custom GPU Dockerfiles for Jetson though.
If I do ever get Jetson hardware or ssh access to one, I will try cooking up a recipe for them.
I am running the Wyoming GPU accel containers on amd64 arch.
1 Like
There is a closed PR in the wyoming-faster-whisper repo to add the ability to load models from hugging face. It will allow you to use ‘large-v2’ and anything else on hugging face that is compatible (CTranslate2 compatible).
Ill try and whip up a custom repo for now, this will give users some more choices on models until more models are in the models repo that faster-whisper pulls its models from.
1 Like
This is a simple CPU accelerated VPS. I have posted a assist pipeline debug above:
What I do not understand is how the initial whisper time is slower than on my Raspi4 but the other two components are fast. So the network does not seem to be an issue. And surely the CPU is not slower than my Raspi4?
Proof is in the pudding, VPS CPU is being throttled.
The 2 other components aren’t as compute intensive. What I would do is open an ssh connection to VPS, run tmux or screen with a few panes.
Have htop and systemd’s joirnalctl -f running and do a voice command, watch how the system resources are being used. If the cpu gets pegged at 100% for all the time that the speech to text is being computed than you know you need more cpu.
Natural language processing and TTS don’t use much resources at all so they will compute fast, it’s the ml model crunching STT that needs power.