OUARZA
February 10, 2026, 8:21pm
1
Hello,Horoscoop, Rachel’s Horoscope - Radio SCOOP
Here is the configuration that does not work.
Pics of like
Text
Can you help me? Thank you
OUARZA
February 12, 2026, 9:52am
2
I’ve tried several things but nothing is working. Can you help me?
- sensor:
- name: "Horoscope Debug HTML"
state: >-
{% set content = state_attr('sensor.horoscope_raw_data', 'content') %}
{{ content[0:200] }} # Affiche les 200 premiers caractères
# --- Compteurs d'icônes ---
- name: "Horoscope Amour (Icônes)"
unit_of_measurement: "❤️"
state: >-
{% set content = state_attr('sensor.horoscope_raw_data', 'content') %}
{{ content.split('horo_amour.png').length - 1 if content else 0 }}
- name: "Horoscope Santé (Icônes)"
unit_of_measurement: "💪"
state: >-
{% set content = state_attr('sensor.horoscope_raw_data', 'content') %}
{{ content.split('horo_sante.png').length - 1 if content else 0 }}
- name: "Horoscope Travail (Icônes)"
unit_of_measurement: "💼"
state: >-
{% set content = state_attr('sensor.horoscope_raw_data', 'content') %}
{{ content.split('horo_travail.png').length - 1 if content else 0 }}
# --- Texte principal ---
- name: "Horoscope Texte Principal"
state: >-
{% set content = state_attr('sensor.horoscope_raw_data', 'content') %}
{% if content %}
{% set start = content.find('horo_travail.png') + 15 %}
{% set end = content.find('Tirage Belline') %}
{% if start != -1 and end != -1 %}
{{ content[start:end] | replace('<br>', ' ') | replace('\n', ' ') | trim }}
{% else %}
"Texte non disponible"
{% endif %}
{% else %}
"Chargement..."
{% endif %}
# --- Tirage Belline ---
- name: "Horoscope Tirage Belline"
state: >-
{% set content = state_attr('sensor.horoscope_raw_data', 'content') %}
{% if content %}
{% set start = content.find('Tirage Belline') + 14 %}
{% set end = content.find('RACHEL CONSEILS') %}
{% if start != -1 and end != -1 %}
{{ content[start:end] | replace('<br>', ' ') | replace('\n', ' ') | trim }}
{% else %}
"Tirage non disponible"
{% endif %}
{% else %}
"Chargement..."
{% endif %}
# Début Horoscope ----------------------------------------------------------
rest:
- resource: "https://www.radioscoop.com/horoscoop.php?id=19"
scan_interval: 3600
headers:
User-Agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
Accept: "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
Accept-Language: "fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7"
sensor:
- name: "Horoscope Raw Data"
value_template: "OK"
json_attributes_path: "$"
# Fin Horoscope ----------------------------------------------------------
multiscrape:
- name: radioscoop_horoscope
resource: "https://www.radioscoop.com/horoscoop.php?id=19" # ID 19 = Sagittaire (à adapter)
scan_interval: 3600 # Met à jour toutes les heures
sensor:
- unique_id: horoscope_sagittaire # Identifiant unique pour Home Assistant
name: "Horoscope Sagittaire" # Nom du sensor
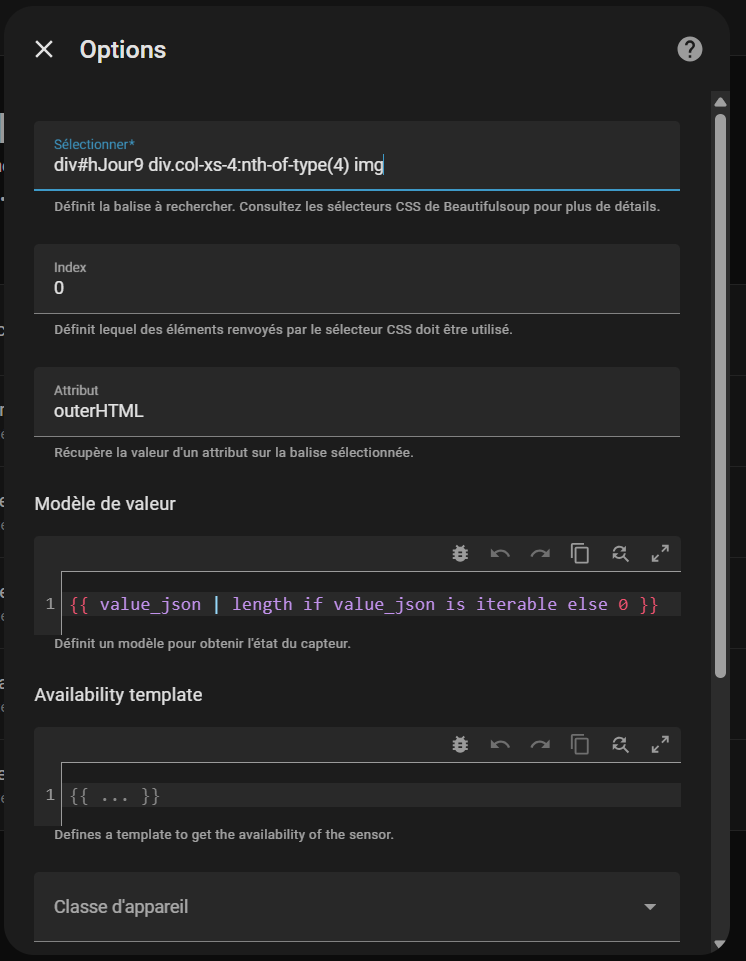
select: "#hJour9" # Sélecteur CSS pour extraire l'horoscope
value_template: "{{ value | regex_replace('<[^>]*>', '') | trim }}" # Nettoie le HTML
attributes: # (Optionnel) Pour extraire d'autres infos si besoin
- name: "amour"
select: ".amour" # Exemple : si tu veux extraire une section "Amour"
multiscrape:
- name: radioscoop_horoscope
resource: "https://www.radioscoop.com/horoscoop.php?id=19"
scan_interval: 3600
headers:
User-Agent: "Mozilla/5.0"
sensor:
- unique_id: horoscope_sagittaire
name: "Horoscope Sagittaire"
select: "#hJour9"
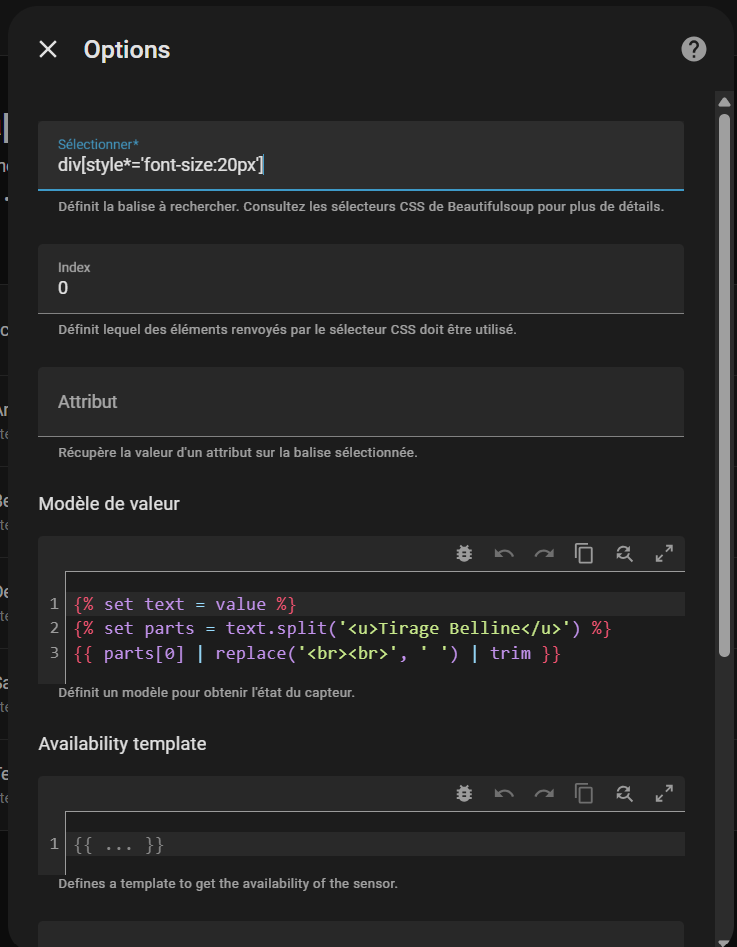
value_template: >-
{% set raw_text = value %}
{% set clean_text = raw_text.split('Tirage de cauris')[0] | trim %}
{% set parts = clean_text.split('Travail') %}
{% set travail = parts[1] | regex_replace('[\n\s]+', ' ') | trim %}
{% set parts = parts[0].split('Santé') %}
{% set sante = parts[1] | regex_replace('[\n\s]+', ' ') | trim %}
{% set parts = parts[0].split('Amour') %}
{% set amour = parts[1] | regex_replace('[\n\s]+', ' ') | trim %}
{{ (amour + " " + sante + " " + travail) | trim | truncate(255) }}
attributes:
- name: "amour"
value_template: >-
{% set raw_text = value %}
{% set clean_text = raw_text.split('Tirage de cauris')[0] | trim %}
{% set parts = clean_text.split('Amour') %}
{{ parts[1].split('Santé')[0] | regex_replace('[\n\s]+', ' ') | trim }}
- name: "sante"
value_template: >-
{% set raw_text = value %}
{% set clean_text = raw_text.split('Tirage de cauris')[0] | trim %}
{% set parts = clean_text.split('Santé') %}
{{ parts[1].split('Travail')[0] | regex_replace('[\n\s]+', ' ') | trim }}
- name: "travail"
value_template: >-
{% set raw_text = value %}
{% set clean_text = raw_text.split('Tirage de cauris')[0] | trim %}
{% set parts = clean_text.split('Travail') %}
{{ parts[1] | regex_replace('[\n\s]+', ' ') | trim }}
OUARZA
February 13, 2026, 5:15pm
3
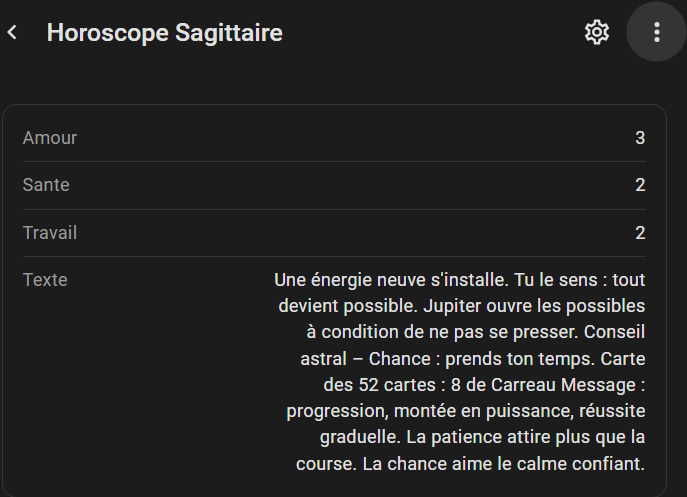
Nailed it
command_line:
- sensor:
name: "Horoscope Sagittaire"
unique_id: horoscope_complet_json
icon: mdi:zodiac-sagittarius
# On remplace <br> par \n\n pour forcer le saut de ligne dans la carte Markdown
command: >
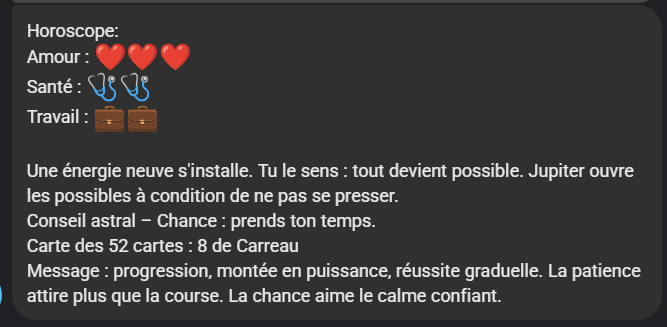
curl -s 'https://www.radioscoop.com/horoscoop.php?id=19' | python3 -c "import sys, re, json; h = sys.stdin.read(); amour = h.count('horo_amour.png'); sante = h.count('horo_sante.png') + h.count('horo_forme.png'); travail = h.count('horo_travail.png'); m = re.search(r'style=\"font-weight:bold ; font-size:20px ; font-style:italic ; padding:10px\">([\s\S]*?)<\/div>', h); t = m.group(1) if m else 'Non disponible'; t = re.sub(r'<br\s*/?>', '\n', t); t = re.sub(r'<[^>]+>', '', t); t = re.sub(r'\n+', '\n', t).strip(); print(json.dumps({'amour': amour, 'sante': sante, 'travail': travail, 'texte': t}));"
value_template: "Mis à jour"
scan_interval: 86400
json_attributes:
- amour
- sante
- travail
- texte