Same on my side after upgrading yesterday to latest version. Only hint I got from logs is “[supervisor.homeassistant.api] Timeout on call http://172.30.32.1:8123/api/core/state”. But I dont know where this IP is configured or to which service it is related.
Guys, please pay attention to Alexa 4.13.3 release. This release has a memory leak which causes the issues. For me, I reverted to a previous release without the Alexa update and updated back to 2024.10.0. I ignored the Alexa update, and everything seems to be running normal.
1 Like
Been having exactly the same issue, and thanks to this thread have disabled Alexa integration for now, problem resolved… Time to look at the native voice integration.
Thanksfor the info.
In that you meant Alexa Media Player 4.13.3, right?
Correct. I’ll edit my post, thanks.
1 Like
Is it safe to update now to 4.13.5? Lol
I am low key nervous.
Unfortunately I still have these same issue and no Alexa Media Player installed.
Started a +/- week ago, seems random, no other hints that sudden timeouts in the supervisor. Some other integrations fail as well during this time. I disabled one but it still happens (so it more a consequence of, not the cause).
Whem I;m not touching the system (at night) it seems to work. As soon as I start tinkering (opening editor, device page, system data, it’s suddenly locks up > high CPU load > timeouts > restart. But I can’t trigger it myself or have any other leads to go on.
Same here. Not sure when exactly it started and nothing in the logs gives me any pointers as to why. I do have AMP installed but I don’t think it’s the cause.
Same way it started, it also ended (hopefully). Issue seemed to have solved itself.
I did a ton of things so I’m not sure if and what solved it.
- I uninstalled some unused HACS compontents (including bublecard that I just installed before issues started)
- Did a database purge+repack
- Uninstalled/installed some integrations, disable/enabled some MQTT components
- Meanwhile installed the newly released updates
- Added more RAM (from 6GB to 8GB) to the proxmox instance
- Installed glances add-on to check on resource usage (however, nu issues since install, maybe it brings some luck)
I encountered the same error, with regular logs “Timeout on call http://172.30.32.1:8123/api/core/state” every 15 minutes.
I have been using HACS and custom integrations without any issues for years.
I started experiencing problems with the 2024.12 release.
The issues disappeared after I disabled an integration (ICS calendar) on my end.
I just tried another integration (iCal) today, and the problem returned.
In my opinion, this means the issue is not with the custom integrations, but rather that there was a change that affects many integrations (like Alexa, which is more widely used than iCal).
So, my advice is: disable your custom integrations, reboot, and test to find the version causing the timeout.
I have 2 official devices Home Assistan Green running all latest versions
In one all normal on the other i also have this error.
All integrations on both devices are the same and in the image below in red are the ones I have added asside the default ones.

I have done a reset from scratch but error still happems
![]()
Having exactly the same issue as others have reported…
Same problems here.
First
“[supervisor.homeassistant.api] Error on call http://172.30.32.1:8123/api/core/state”
then
“[supervisor.homeassistant.api] Error on call http://172.30.32.1:8123/api/core/state: Cannot connect to host 172.30.32.1:8123 ssl:False [Connect call failed (‘172.30.32.1’, 8123)]”
then
“[supervisor.homeassistant.core] Home Assistant has crashed!”
Running on a RPi 4 8GB with external sata-ssd. It just started randomly.
I’ve already tried a clean install and reload of a backup - no success.
I have the same happening to me, i have used 3 different RPi4 (4Gb and 8Gb ram) and no luck even with fresh installs i get this both on sd card and on ssd sata-usb.
To me what i notice is that the WebUI becomes unavailable and takes so long to appear after a reboot or something and sometimes never gets to load.
Same here, Intel NUC running proxmox. Worked fine last reboot (a week ago) and this week boots, shows CLI and observer looks fine but front end not possible to get to. when I had one CPU assigned to it, it maxed the CPU out. When I assigned a second core it shows nothing more than 10% on both but still locks up and locks up my whole proxmox/NUC setup. Turn off the HA VM and everything works fine.
2025.4.3, OS 15.2. Not running Alexa.
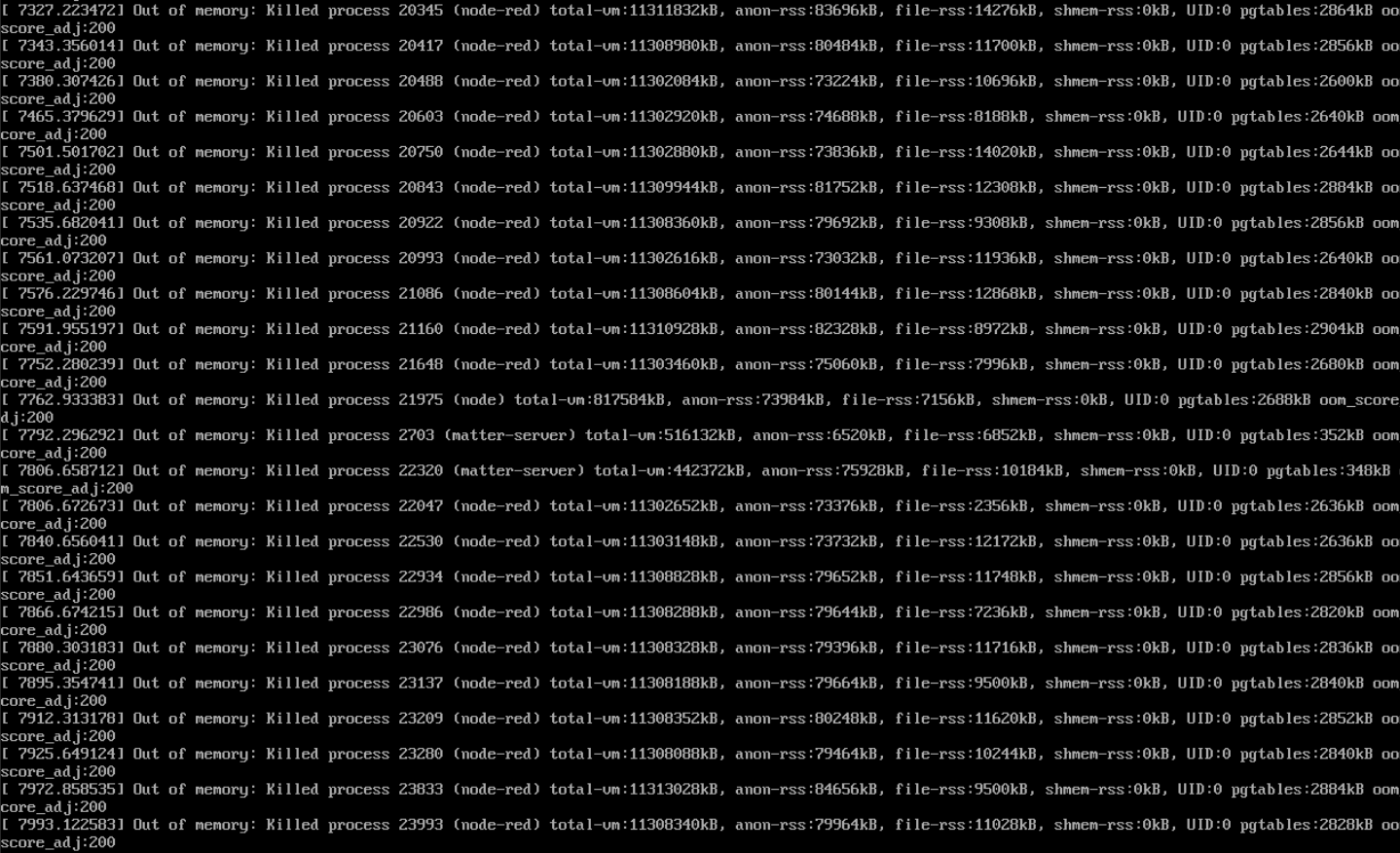
Further digging shows what seems to be memory leaks on dozens of items. if I can get into the linux cmmandline, and run top, I get dozens of out of memory warnings where add-ons like node-red, influxdb, grafana etc are repeatedly killed and restarted. watching them they don’t seem to take much memory in the top listings and watching my VM stats in proxmox shows no problem with memory - I have 3 gig assigned and it rarely goes over 900mb, never approaching 3 gig.