I’ve tried every single URL under the sun that I can think of for the ha_url. Currently this is the IP of the box itself. HomeAssistant is configured to use HostNetwork in its docker setup
The other thing that is interesting is that appdaemon is using 100% cpu in top
I have no while loops. I do use for quite a bit but only on listen events when I have multiple devices configured for an app such as my alarm system app where I want it to monitor a list of contact sensors.
I can’t find anything outstanding in my HA dashboard that looks like its a resource hog of any sort
If I’ve reached some sort of limit with appdaemon and I need to split it apart into another instance I’ll gladly do so but at the moment I’m sitting here just racking my brain trying to figure out what could be causing these symptons.
Ok I’ve completely removed all apps from my apps.yaml and from the folder and no disconnects so now I’m going to add them back in 1 by 1 to figure out where the problem child is at.
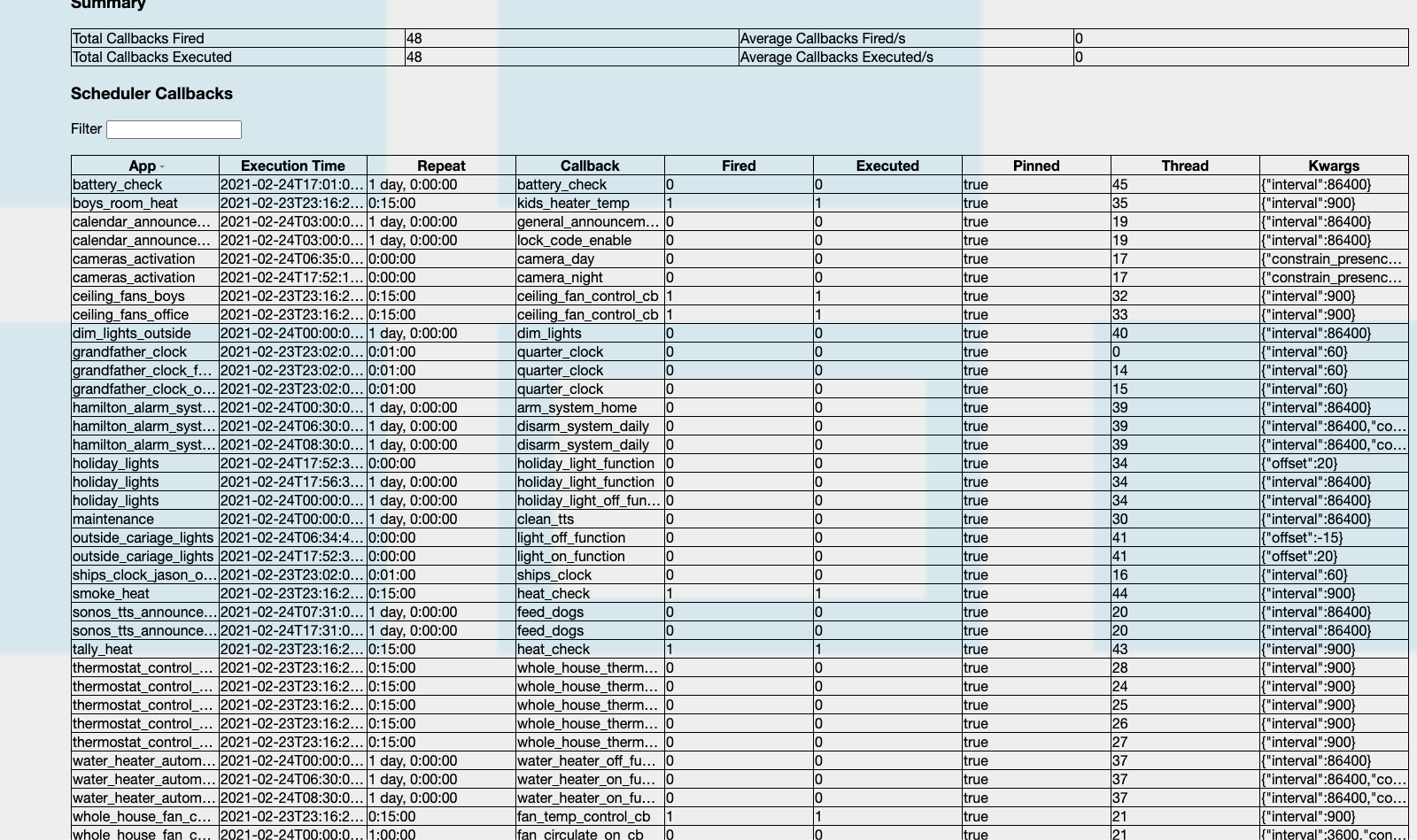
Ok so I’ve readded all of the apps back into appdaemon. I didn’t add some that I know haven’t been in use as of late. When I hit the 34app mark I started to get the “Excessive time” warning which I do handle with a production mode app that I use to enable/disable prod mode on appdaemon. But there have not been any disconnects from HA as of yet. So I’m hoping that this helped to clean it up. I’m going to let it run like this for a little while then I’m going to bounce the container and see if that has any impact of spinning up all the threads at once vs the incremental increase that I did here.
I have rewritten all my apps to async mode instead, and it helped with similar issues. I think @ReneTode has a larger number of running apps than you, so the number of apps shouldn’t be an issue. Are you sure you don’t have any blocking code in your apps?
For the async do you have an example of what that looks like?
Yeah I don’t think I have any blocking code I don’t have any while loops, no sleeps. Anything that needs a sleep I have a run_in set for it instead so that it goes into the scheduler and chills there until its needed. I’m no amazing code writer and I’m sure that some of my apps could probably be optimized but I optimized them to the best that I could think of. Any lookups that need to be done are done once per function at the beginning so that throughout the rest of the function it has the info it needs. I pass things along through kwargs if I can. Any other tips you got I’m down for it. Yeah @ReneTode is the app master
in my eyes thats a bad solution.
if you got excessive time warnings that can point to several things:
way to much I/O that the disk cant handle
a large number of apps doing the same thing or things that holdup the AD core.
both wont get better when you use async. but async will make that if 1 app happens to be in trouble all other apps are at risk also. because all async apps and tha AD core run in 1 thread.
you are right that i got way more apps.
1 run 1 app over 300 times, but all and all im near 750 apps.
at some point i also get excessive time, but mostly because without production mode AD checks to much files. thats why i also use production mode. (thats why its there)
i got 7 AD instances running now and not even on 50% from my CPU.
so i dont know what is the problem at your case @TheFuzz4 but its not an AD limit but something in your code.
i advise you not to start with async if you got so much going on and you are not familiar with async.
to work with async you really need to know what you do, and secure everything yourself.
i only advise it for people who have no problem that AD can stop on any error they made themselves at any time. (i personally cant risk it because all my lights and heating depend on AD)
what i would advise is to start looking at apps that run heavily.
listeners for entities that are updating very frequent.
for example i got shellies. they tend to send state updates 30 to 60 times a minute!
for me that results in that for now im at 13.3 million callbacks (talking about heavy use )
So I think that my issue lied in some app that wasn’t being used. My CPU usage now idles around 4% for appdaemon. So apparently cleaning everything out and then starting over and adding things back in helped. I did have like 5 apps that were in the folder but not in the apps.yaml so while it did know they existed there was no reference to them. Perhaps now that they’re not even in the folder that will help.
Apart from loops and sleep, you should wrap any i/o code such as request.get/post and file system operations in async by using aiohttp instead of requests. This is just good practise and not specific to appdaemon. As Rene writes, async is not the easiest thing to master, but for me it works fine. Of course, only apps that need async should be async and most of my apps do as I am doing a lot of i/o. I don’t use async for simple automation apps with no i/o calls.
I have one app that manages docker containers through the docker rest api which is quite slow. The only way to get it working was to use async.
i got such apps also. so i dont suspect it was that.
its possible though that something was keeping everything busy. maybe a name that gave trouble.
but glad that its working again.
im glad its working for you too @tjntomas i guess you know what you do with async.
and you probably also know how to debug when you run into trouble and interfere with the core.
it is possible now with AD, but in my eyes the implementation was never really finished to a good endpoint. (because the lives from the devs took over )
Yeah I’m not doing any i/o that I can think of other than writing to logs. Otherwise I let service calls back to HA do what I need such as taking pictures and things. But that happens seldom only when the conditions are met.
i needed to start splitting up because i use to heavy, and i needed to make sure that important systemparts could never be effected by unimportant ones.
the amount did also grow because its easy and i needed to work out different issues.
so now i got:
AD entities (does all my entity work for over 700 entities. replaces HA intergrattions like milight, mysensors, shelly, etc.)
AD actions. (1 app that is used over 300 times)
AD dashboard (takes care of all tablets, dashboards, and related apps)
AD heating (my heating systems)
AD alexa (my alexa app was unstable at some point, thats why i did split it off)
AD rest (all kind of sensor creations, and apps that dont belong to anything else)
AD controlboard (also dashboard, but i use that instance mostly for developing)
and then i got 2 other instances on 2 other devices.
1 AD on my synology
1 AD on a PI zero.
but like i said: i got around 10.000.000 callbacks every month. and thats quite a lot
yeah i noticed yo got cam use in AD also. dont forget that cam use is heavy I/O, even when its not AD that is doing it, the I/O can be very busy. causing that AD needs to wait to do things like logging etc.