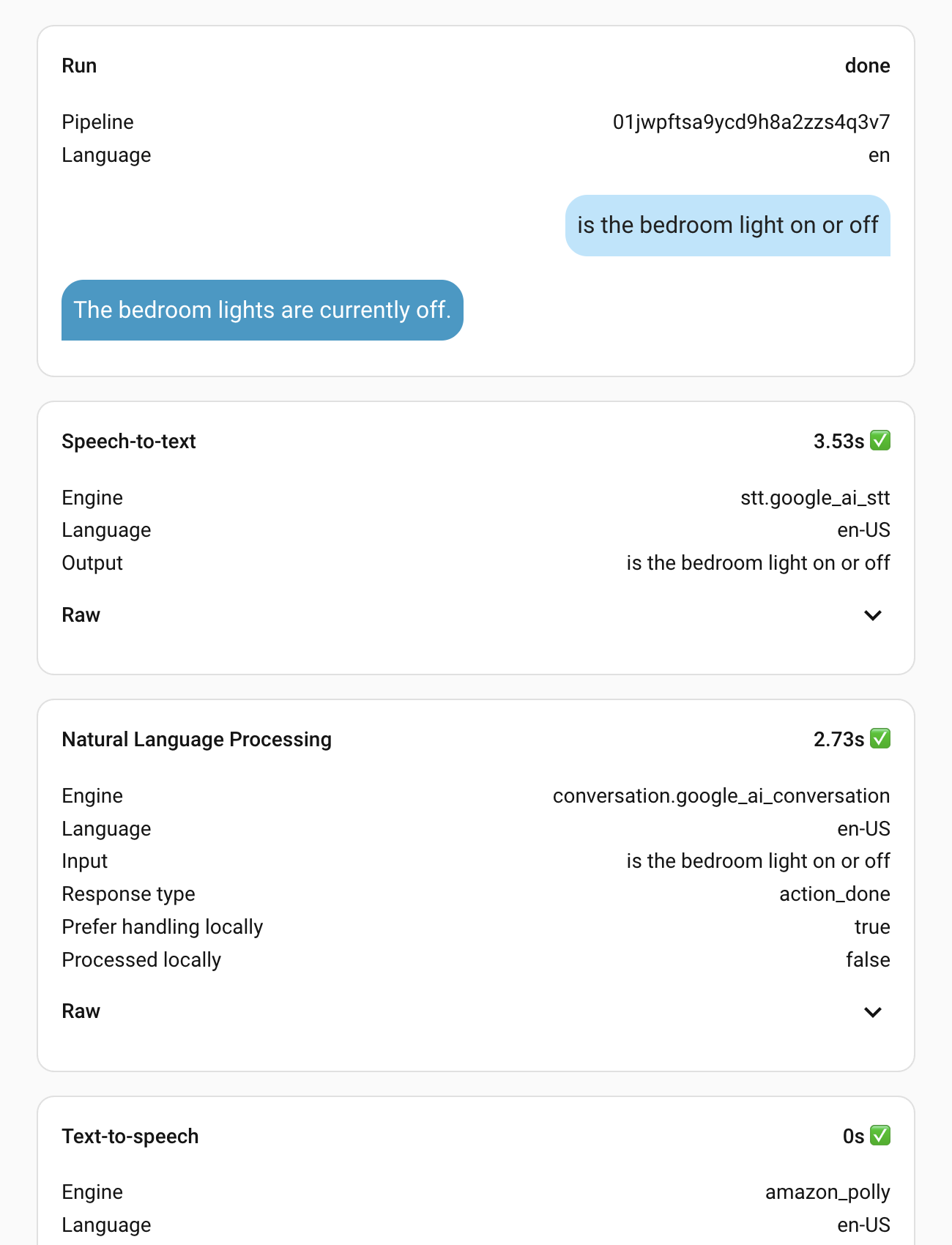
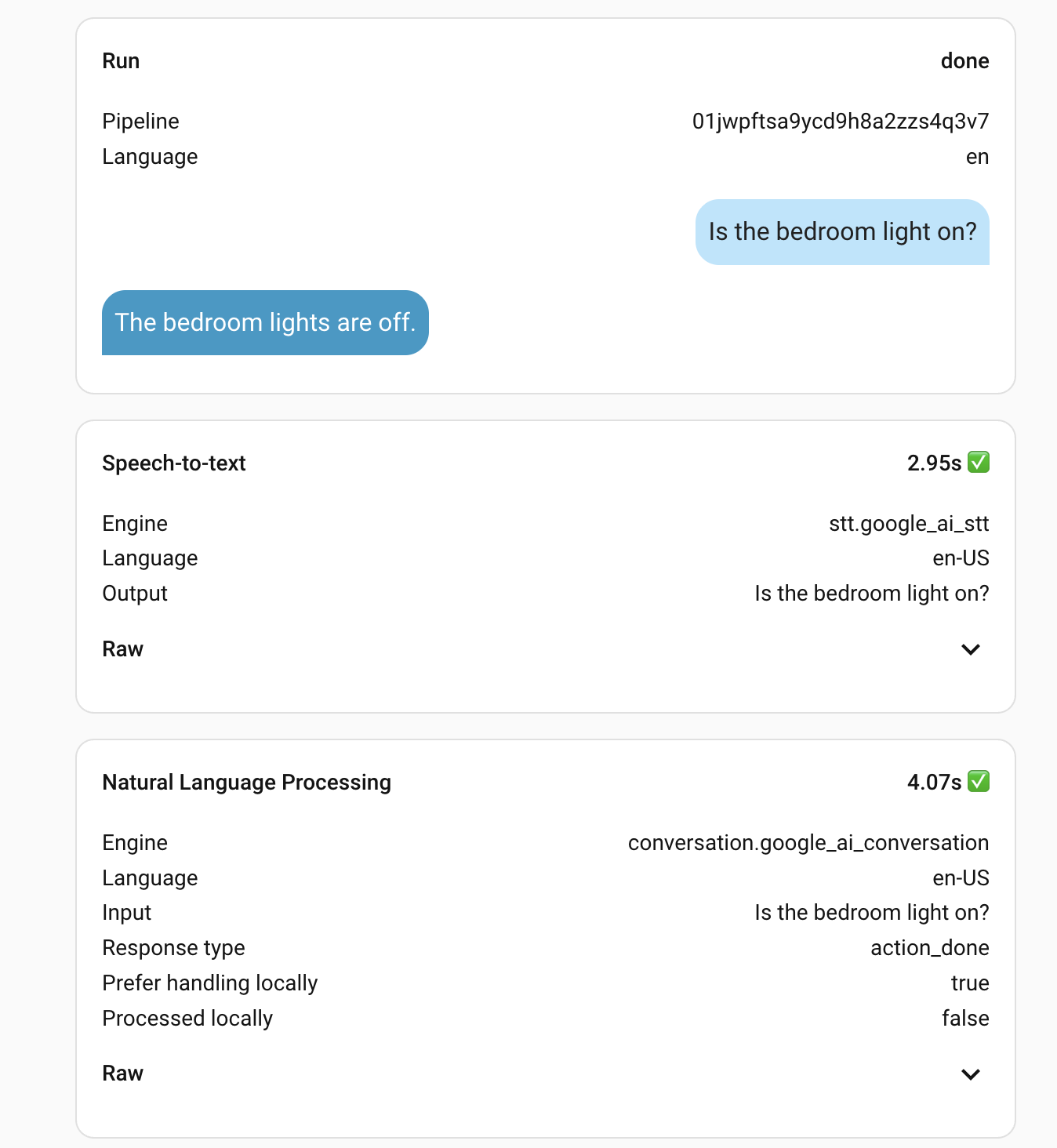
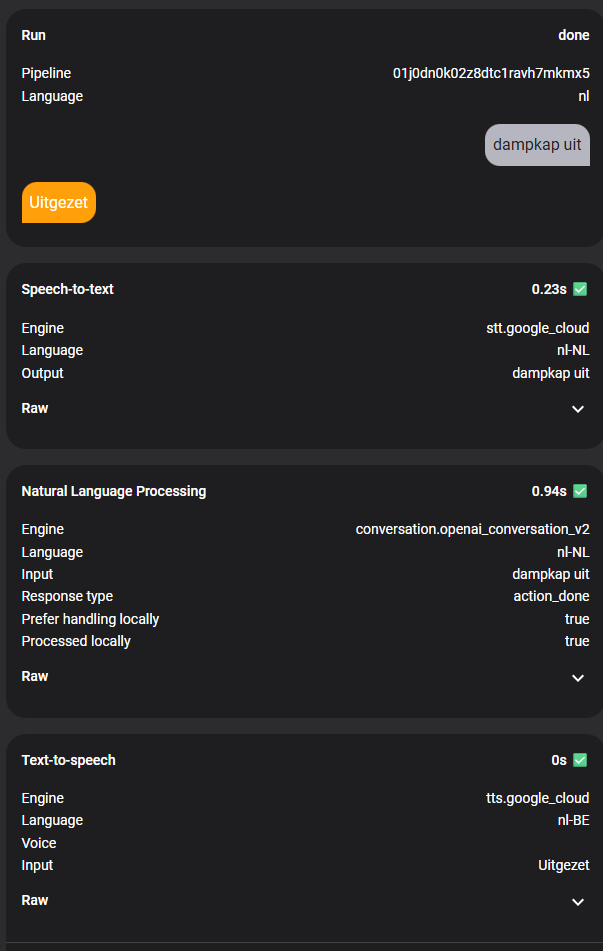
Just got my HA voice hardware and started to play with voice assistant. I’m using Google Gemini AI as the STT and NLP engine. However, I often have to wait for nearly 8~9 seconds to get the response. The debug shows that STT takes ~3 seconds and NLP takes 3~4 seconds.
I’m on 1Gbps AT&T fiber plan so I’m sure the network isn’t the bottleneck(latency < 6ms for google.com).
Has anyone tried other cloud-based STT service and how’s the experience?
For the local alternative, I’m trying Wyoming integration + home assistant itself as conversation agent. It is indeed faster but the recognition success rate is lower than Gemini.
I guess one can’t get both speed and performance at the same time.
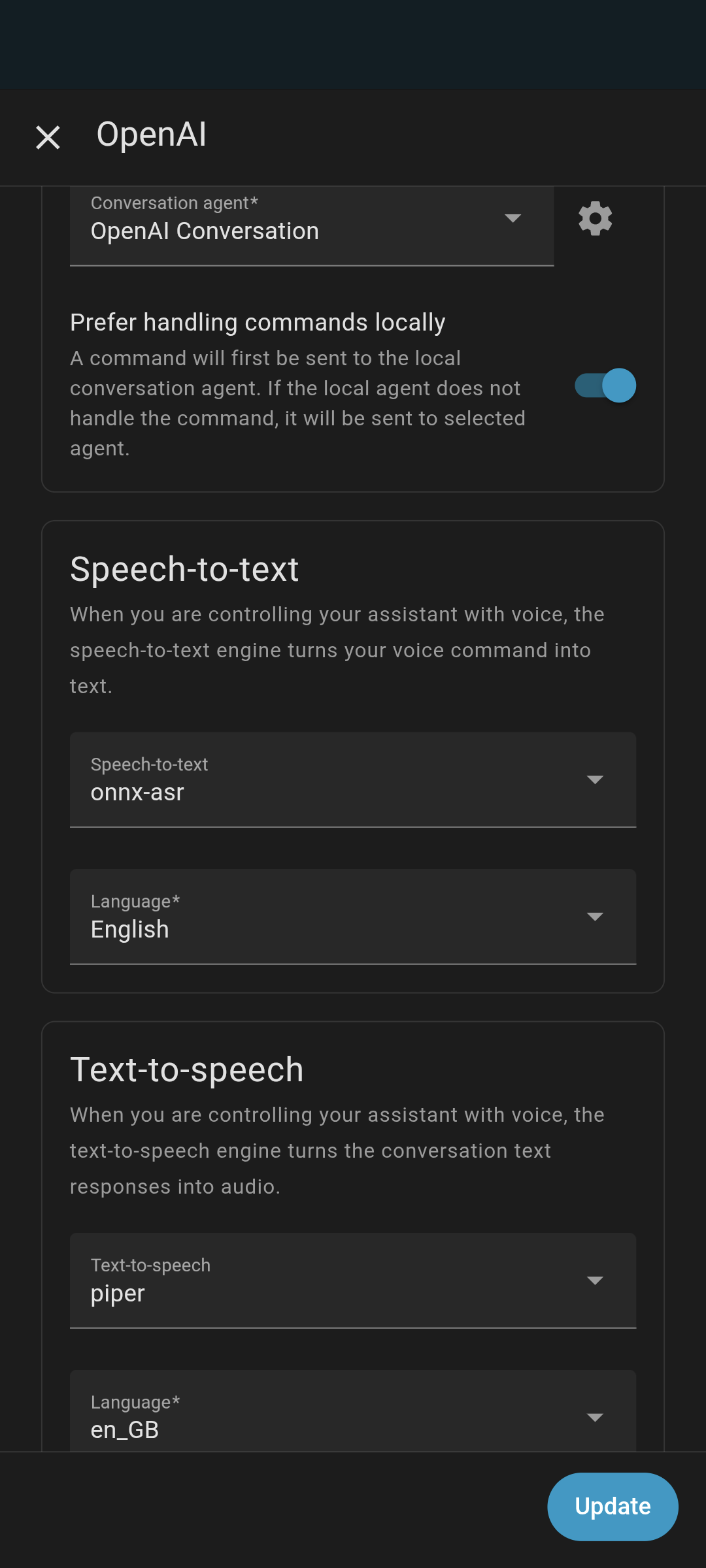
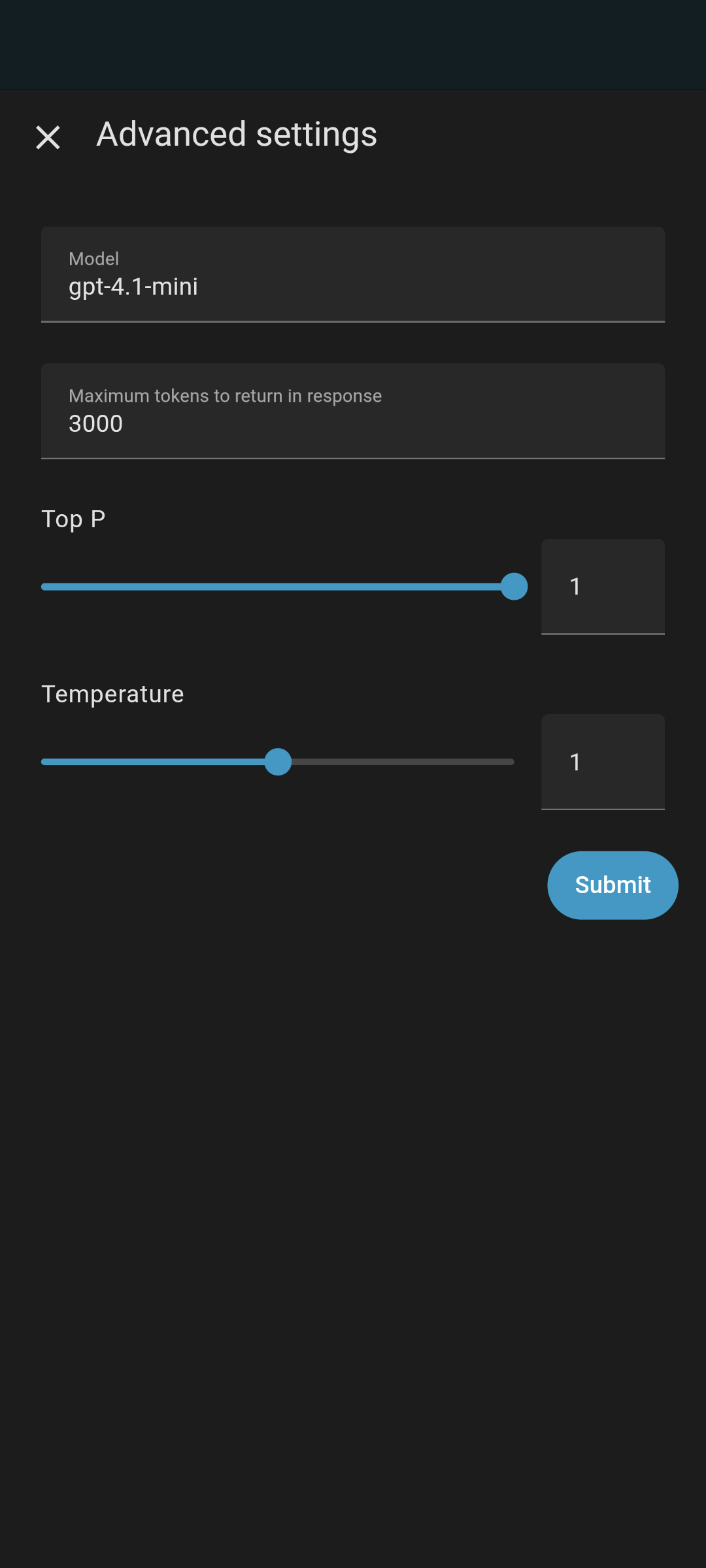
Yes I currently find the best setting for me on the NUC with local STT and TTS with cloud OpenAI gpt to be the below thanks to everyone’s help. Gpt-4.1-mini is more expensive than gpt-4.1-nano and gpt-4o-mini but it’s what I’m currently testing.
Local automations are quick and cloud questions take 3 or 4 seconds to reply, which is slower than my Google nest mini but still acceptable for now.
Gpt-4.1-nano should be quicker than both 4o-mini and 4.1-mini but potentially less accurate, yet to test that though.
I need to play around with my Piper TTS setting though as the way it pronounces some words is a bit odd, I suspect it’s just the voice I’ve picked.
Why use AI STT/TTS though? Just use regular Google cloud STT/TTS. They are extremely fast and free. STT is never more than 0.35s with google cloud, and TTS is never even measurable.
They are extremely reliable. I totally fail to see why you would want AI STT/TTS?
Agreed… Mostly. I use a cloud TTS with streaming support for Friday’s voice. Nobody has a really good thirty something Irish, Dublin native female voice.
Unless I have a specific reason. I’m using default. If I’m switching for speed I’m definitely not going cloud.
This component does not have streaming processing of responses from the LLM. Even if Google performs its task instantly, the result will depend on the speed of the intent processing stage.
You are absolutely right, and the cloud LLM (if you use it) will still be the bottleneck. But at least it should solve part of the frustration of the topic starter by removing the seconds the AI STT takes without going down the path to build a suitable HW setup to handle everything local
Since you mention gemini, I assume you refer to the Google Gemini integration which offers the “Google AI STT” - which also the topic starter is using. The point I made is that that is a very different beast than google Cloud - it is a totally different integration. The google cloud integration I referenced does NOT use the generative AI API for STT. It is miles faster than the gemini integration for STT to the point the STT is not even the bottneleck anymore. Google cloud stt is anywhere between 0.15-0.3s for me. But again that is NOT Gemini. Carefully look at the screenshot I posted and notice my STT integration is a different one from the topic poster.
I agree it is very confusing - but follow the link I posted. If you are just running HA on a raspberry pi, no way local whisper will be faster with the same accuracy. I am sure if you have a beefy machine running your local stuff you can get it as close and arguably more reliable.
I jump in the discussion …
I was SO HAPPY to find Google AI STT TTS (from Google Gemini integration) because for Romanian it has absolutely BEAUTIFUL voces !!! Very very nice !!
Just that … I found out quickly that they come for a “high price” → The time
For a “50 words story” I get around 10 seconds from the moment I press tts.speak or assist_satellite.announce) while the other STT TTS are … around or below 1 second.
Now I’m not so happy anymore … since I need to choose: fast reaction (but a more robotic (and not so correct speaking) voice, or a very nice voice but … which comes with delay
Ps. If I have a given text, can I prepare the audio (in the cache) in advance? (so that when I play it, it plays immediately) ?
You’re talking about TextToSpeech.
It is quite possible to split a long text into sentences (as piper does) and generate them sequentially, but you need a paid plan with a large number of requests per minute, otherwise you will run into limits.
Still, the time to the first word will be quite long.
imho
Сreating a new voice for Piper is the best option if you don’t like the existing ones. It is useful both for yourself (you can select any data for the dataset), and for other users in Romanian.
Even if you don’t have the necessary equipment, it can be done for free at colab.
Thanks, I corrected above → TTS (not STT)
Interesting the idea with splitting the text. I suppose it’s not easy but could lead to some results.
Previously I was thinking …:
maybe “streaming” will be enabled also for normal TTS actions
at least a way to prepare in advance the cache (something like assist_satellite.announce with “cache_only: true” (or “play_audio: false”) (this is helpful only in some of the situations)
maybe a new solution … ChatGPT , Gemini have solutions (on mobile apps) for live dialogue in any language … and it works very nice. And it’s over their cloud (I suppose). So … maybe this could be possible also with HA in future
Thanks for the hint with Piper, I’m not familiar with. I’ll try to understand more
PS. For now I just re-installed an old m5stack-atom-echo, to use it as “dummy silent speaker” to be able to pre-cache the messages for “good night” for my kids to be used with the very nice Romanian voices from Google Gemini TTS