Hello! This is not strictly about installation, but because I’m running “Home Assistant Supervised”, this seemed to be the best topic to post the question. Here it is:
Recently the Core in my HA install stared shutting down on it’s own, without any errors. Can’t figure out the reason. I’ll post the logs from HA core and supervisor below.
Environment information:
arch: armv7
channel: stable
docker: 20.10.8
features:
- reboot
- shutdown
- services
- network
- hostname
- timedate
hassos: null
homeassistant: 2021.11.5
hostname: homeassistant
logging: info
machine: raspberrypi3
operating_system: Raspbian GNU/Linux 10 (buster)
state: running
supervisor: 2021.10.8
supported: false
supported_arch:
- armv7
- armhf
Logs from HA core: (truncated)
2021-11-26 19:09:00 WARNING (Thread-2) [homeassistant.helpers.template] Template variable warning: 'None' has no attribute 'last_changed' when rendering or compiling ''
2021-11-26 19:09:00 WARNING (Thread-2) [homeassistant.helpers.template] Template variable warning: 'None' has no attribute 'last_changed' when rendering or compiling ''
2021-11-26 19:09:00 WARNING (Thread-2) [homeassistant.helpers.template] Template variable warning: 'None' has no attribute 'last_changed' when rendering or compiling ''
[finish] process exit code 256
[finish] process received signal 9
[finish] process exit code 256
[finish] process received signal 15
[cont-finish.d] executing container finish scripts...
[cont-finish.d] done.
[s6-finish] waiting for services.
[s6-finish] sending all processes the TERM signal.
[s6-finish] sending all processes the KILL signal and exiting.
pi@homeassistant:~ $
Logs from HA supervisor: (truncated)
21-11-29 14:17:19 INFO (MainThread) [supervisor.api.middleware.security] /supervisor/info access from cebe7a76_hassio_google_drive_backup
21-11-29 14:17:19 INFO (MainThread) [supervisor.api.middleware.security] /backups access from cebe7a76_hassio_google_drive_backup
21-11-29 14:31:56 INFO (MainThread) [supervisor.updater] Fetching update data from https://version.home-assistant.io/stable.json
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.check] Starting system checks with state CoreState.RUNNING
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.checks.base] Run check for IssueType.TRUST/ContextType.SUPERVISOR
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.checks.base] Run check for IssueType.PWNED/ContextType.ADDON
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.checks.base] Run check for IssueType.TRUST/ContextType.CORE
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.checks.base] Run check for IssueType.FREE_SPACE/ContextType.SYSTEM
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.checks.base] Run check for IssueType.SECURITY/ContextType.CORE
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.checks.base] Run check for IssueType.TRUST/ContextType.PLUGIN
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.check] System checks complete
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.evaluate] Starting system evaluation with state CoreState.RUNNING
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.evaluate] System evaluation complete
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.fixup] Starting system autofix at state CoreState.RUNNING
21-11-29 14:32:34 INFO (MainThread) [supervisor.resolution.fixup] System autofix complete
pi@homeassistant:~ $
dmesg logs: (truncated)
[103321.198028] Mem-Info:
[103321.198044] active_anon:103060 inactive_anon:103087 isolated_anon:0
active_file:41 inactive_file:1704 isolated_file:96
unevictable:4 dirty:0 writeback:0
slab_reclaimable:6170 slab_unreclaimable:6773
mapped:164 shmem:5536 pagetables:2467 bounce:0
free:4054 free_pcp:434 free_cma:40
[103321.198057] Node 0 active_anon:412240kB inactive_anon:412348kB active_file:164kB inactive_file:6816kB unevictable:16kB isolated(anon):0kB isolated(file):384kB mapped:656kB dirty:0kB writeback:0kB shmem:22144kB writeback_tmp:0kB kernel_stack:6024kB all_unreclaimable? no
[103321.198072] DMA free:16216kB min:16384kB low:20480kB high:24576kB reserved_highatomic:0KB active_anon:412240kB inactive_anon:412348kB active_file:0kB inactive_file:7100kB unevictable:16kB writepending:0kB present:970752kB managed:945364kB mlocked:16kB pagetables:9868kB bounce:0kB free_pcp:1736kB local_pcp:248kB free_cma:160kB
[103321.198078] lowmem_reserve[]: 0 0 0
[103321.198103] DMA: 818*4kB (UMEC) 442*8kB (UMEC) 200*16kB (UME) 79*32kB (UME) 24*64kB (ME) 9*128kB (UME) 3*256kB (U) 2*512kB (M) 0*1024kB 0*2048kB 0*4096kB = 17016kB
[103321.198211] 7498 total pagecache pages
[103321.198219] 31 pages in swap cache
[103321.198226] Swap cache stats: add 232642, delete 232611, find 132050/171715
[103321.198232] Free swap = 0kB
[103321.198237] Total swap = 307196kB
[103321.198243] 242688 pages RAM
[103321.198249] 0 pages HighMem/MovableOnly
[103321.198254] 6347 pages reserved
[103321.198260] 16384 pages cma reserved
[103321.198266] Tasks state (memory values in pages):
[103321.198272] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
[103321.198299] [ 118] 0 118 10347 215 83968 135 0 systemd-journal
(aproximately 180 lines cut out for brevity)
[103321.200126] [ 18750] 0 18750 1090 33 10240 0 0 pgrep
[103321.200137] [ 18758] 0 18758 1987 34 12288 12 0 cron
[103321.200147] [ 18759] 0 18759 1987 30 12288 16 0 cron
[103321.200157] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=ab8434278066a72b90184009b898dd8308373da7619d1c745c7b5e5ff621f2b2,mems_allowed=0,global_oom,task_memcg=/,task=python3,pid=7218,uid=0
[103321.200313] Out of memory: Killed process 7218 (python3) total-vm:587660kB, anon-rss:352320kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:624kB oom_score_adj:0
[103321.381143] oom_reaper: reaped process 7218 (python3), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
pi@homeassistant:~ $
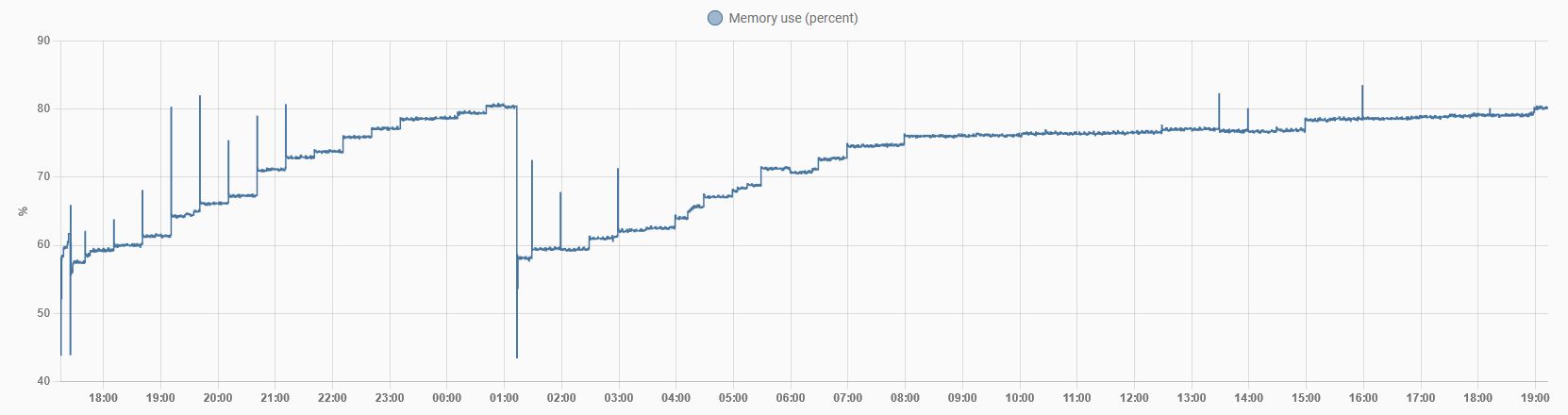
In the process of composing this post I noticed the “out of memory” error in dmesg (above), and this is likely why it is being shutdown. That never happened before, and started occurring after I updated last week.
I will start disabling addons and generally trying to figure out if there’s a memory leak somewhere.
Have anyone seen any memory usage issues lately?
thanks!
Claudio