The Need
Smart homes include a network of devices. A case of a failed command can happen due to temporary connectivity issues or invalid device states. The cost of such a failure can be high, especially for background automation. For example, failing to shutdown a watering system which should run for 20 minutes can have severe consequences.
Any machine or device can break down, so it’s not possible to have full guarantee without redundancy (which is most likely less relevant for smart homes). But it’s possible to identify failures and try mitigating them, which can increase significantly the overall reliability of the automation.
The Solution: retry.call
The custom integration adds a single service - retry.call. This service warps an inner service call with background retries on failures.
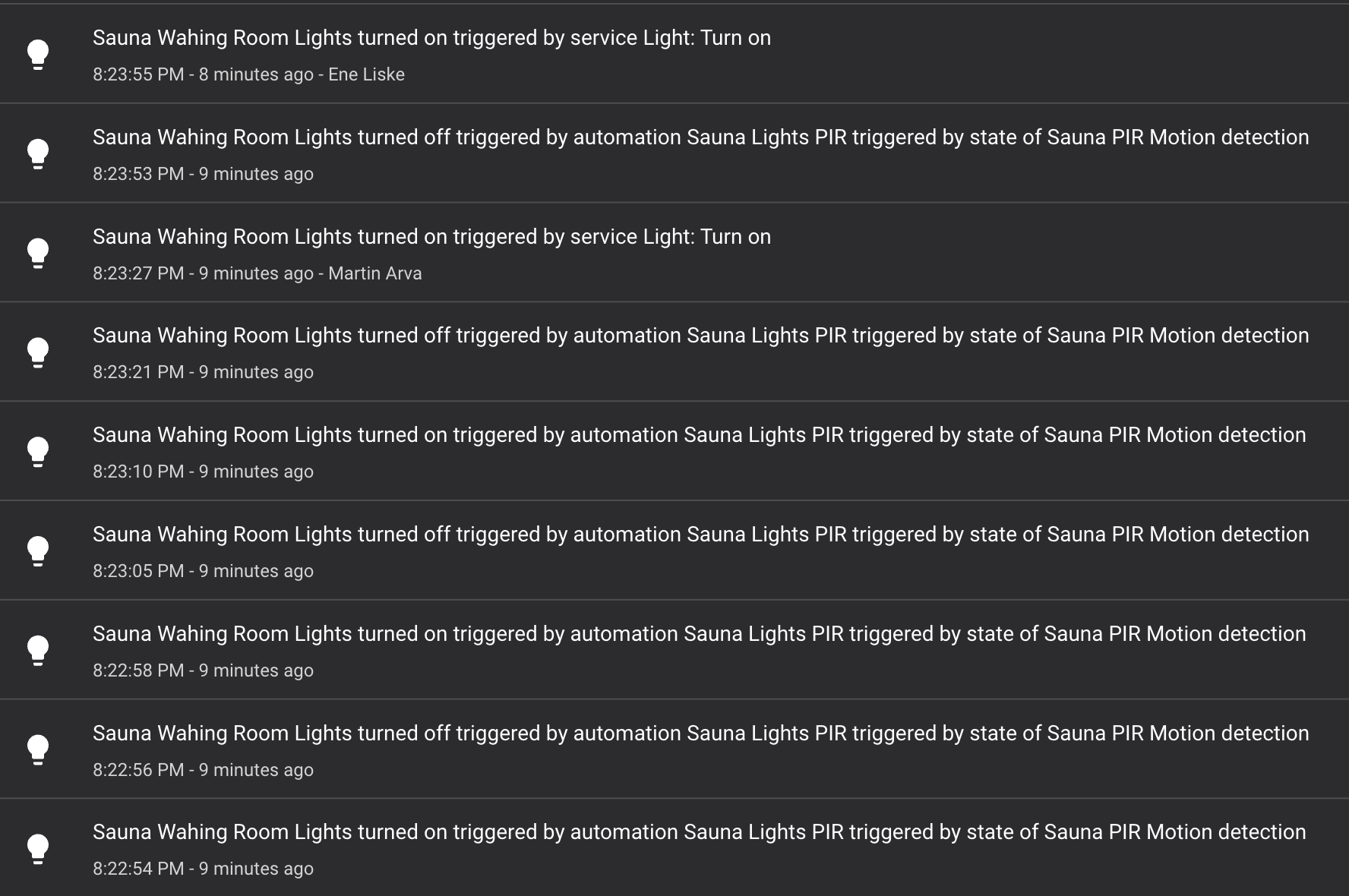
Our Results & Experience
We have 56 automation rules, with a total of 75 service calls in them. 51 of the service calls (~70%) were migrated last month to retry.call. The other 24 service calls are either not relevant or not suitable to this type of solution, as it has its own limitations. 34 of the 51 retry.call (~66%) are also passing the expected_state parameter (see more about this parameter below).
The result is a significant reliability increase of the automation. It’s not so rare to see in the log file that retires were used, but we never saw a failure of all retries (there is limit on the amount of retries).
Usage
Instead of:
service: homeassistant.turn_on
target:
entity_id: light.kitchen
The following should be used:
service: retry.call
data:
service: homeassistant.turn_on
target:
entity_id: light.kitchen
It’s possible to add any other data parameters needed by the inner service call.
Logic
The inner service call will get called again if one of the following happens:
- The inner service call raised an exception.
- One of the target entities is unavailable. Note that this is important since HA silently skips unavailable entities (here).
The service implements exponential backoff mechanism. These are the delay times of the first 7 attempts: [0, 1, 2, 4, 8, 16, 32] (each delay is twice than the previous one). The following are the offsets from the initial call [0, 1, 3, 7, 15, 31, 63].
Optional Parameters
By default there are 7 retries. It can be changed by passing the optional parameter retries:
service: retry.call
data:
service: homeassistant.turn_on
retries: 10
target:
entity_id: light.kitchen
The retries parameter is not passed to the inner service call.
expected_state is another optional parameter which can be used to validate the new state of the entities after the inner service call:
service: retry.call
data:
service: homeassistant.turn_on
expected_state: "on"
target:
entity_id: light.kitchen
If the new state is different than expected, the attempt is considered a failure and the loop of retries continues. The expected_state parameter is not passed to the inner service call.
Notes
- The service does not propagate inner service failures (exceptions) since the retries are done in the background. However, the service logs a warning when the inner function fails (on every attempt). It also logs an error when the maximum amount of retries is reached.
- This service can be used for absolute state changes (like turning on the lights). But it has limitations by nature. For example, it shouldn’t be used for sequence of actions, when the order matters.
Install
HACS is the preferred and easier way to install the component, and can be done by using this My button:
![]()
Otherwise, download retry.zip from the latest release, extract and copy the content under custom_components directory.
Home Assistant restart is required once the integration files were copied (either by HACS or manually).
Adding Retry integration to your Home Assistant instance can be done via the user interface, by using this My button:
It’s also possible to add the integration via configuration.yaml by adding the single line retry:.
Feedback
Feedback, suggestions, and thoughts are more than welcome!