Nick how much vram is being used by that 72k context? That’s dangerously close to capable of running Friday’s entire live context. (currently 96k I think 64k Is doable)
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.57.08 Driver Version: 575.57.08 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 On | 00000000:01:00.0 Off | N/A |
| 0% 51C P5 24W / 280W | 22744MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 59249 C /app/llama-server 22734MiB |
+-----------------------------------------------------------------------------------------+
Seems like it would probably be doable
1 Like
That’s currently #5 on my list behind post current script updates and complete deploy script.
If I can get a sub 3 second response off a >64K context were there. I’ve been eyeballing that qwen multimodel model hard. That + Q3VL +OSS20b are a serious combo (and suddenly vram availability is a problem)
2 Likes
I got Qwen3-ASR 0.6B running on my 9060XT which is being installed as a secondary system for helping out with voice specifically. Running via vLLM and this is the result. Will need more testing to see how accurate it is but this is promising.
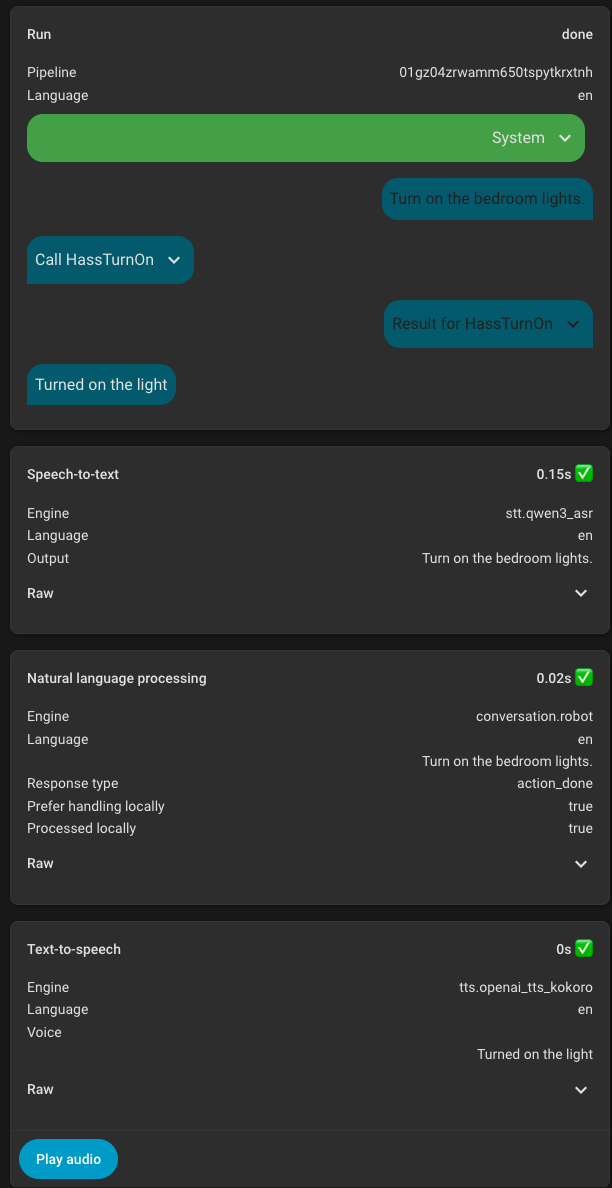
1 Like
I actually have my Frigate model setup to run with k & v cache types to be quantized. I don’t however have my HA model setup with those flags (it introduces a slight overhead that results in ever so slightly longer wait times…tenths of seconds, which isn’t bad, but my GPU is only at 88% VRAM usage with the 32B and 8B models loaded and being used, even simultaneously so I prefer the extra speed for HA).
I tried the A3B 30B model and it’s just too slow for HA usage (for me on my card anyway). That many parameters just slows it down too much.
In that screenshot I think it shows it wasn’t processed on the LLM but rather via the HA device directly (locally versus being passed off to an LLM).
That said, I’m sure a 0.6B model would run very quickly, it’s just a matter of it understanding things.
My personal experience has been that 8B is just about perfect, 4B is functional but is prone to mistakes (saying it completed things it didn’t occasionally, telling me what lights are on when I ask but including ones that aren’t, etc) and 2B would only work with very very specific commands. Things like “what should I wear if I head out tomorrow?” or “Good morning, I’m getting out of bed” would result in just wacky replies.
I’ve never tried a 0.6B model and just began testing different models the other day since when I got everything setup mid last year so maybe there have been advances that I haven’t gotten to experience (I continue to test lol).
I think you misunderstand, Qwen3-ASR is for speech recognition (speech to text), not for the LLM itself.
Also, in regards to models / size, not sure if it was known but there is a leaderboard for LLMs in Home Assistant with some benchmarks for Home Assistant.
My experience matches this, which is why I love 30B-A3B, 8B was great but it seemed to have less “depth” and 30B-A3B is more capable of seeing past transcription errors or speech mistakes and knowing what we mean.
Of course the best model is different for everyone, which is part of what makes this fun to tinker.
2 Likes
Yup, 100% missed that lol
You never fail to share new things I haven’t come across my friend hahaha. That leaderboard is awesome, and no, it wasn’t known to me…so cool.
As for your sentiment of “best model…” and “fun to tinker” - couldn’t have said it better myself.
Playing around with this stuff makes me feel like a kid watching Sci-Fi movies and the joy/wonder of what the future might be like…and now I get to live it…it’s magical and almost surreal.
1 Like
Also an update on Qwen3-ASR, for short requests like “turn on the lights” it is very fast, but when you get into longer sentences “Turn on the lights and turn off the fan” it is significantly slower (1.5 seconds). It seems the explanation is the architecture is slower when multiple frames of audio are passed in. Perhaps it will get better as the feature matures in vLLM. For now parakeet still seems to be better overall.
1 Like
While waiting for Qwen3.5 to drop I have been playing with other models. The one thing about Qwen3-VL that is difficult is it does not respond well to negative prompting (ex: “do not …”, “never…”, etc.).
After recent llama.cpp fixes I decided to give GLM4.7 Flash a try, and it is working quite well. It seems to handle the negative prompting better, its main problem is an over-eagerness to “do something”, so it is difficult to have it correctly ignore text after a false activation. It also would try to run an action with a few words, for example just saying “dog digging” and it would run a different tool every time trying to be helpful. It also often would struggle to understand what room it was in.
For now I have gone back to Qwen3-VL again.
1 Like
I’ve had a similar experience with qwen3-vl (haven’t tried GLM). I’ve had to do some extreme “constraint based prompting” in certain areas to achieve desired results. The simplest of which (and have many more complex use cases, primarily within my Frigate prompting) was simply getting it to stop returning “F” at the end of temperatures when requesting weather forecasts. I ended up with this to get it to adhere to it:
====================================================================
SECTION 3 — WEATHER RESPONSE FORMATTING (MANDATORY)
When responding with temperature information:
Round the temperature to the nearest whole number.
REMOVE ALL REFERENCES TO THE FOLLOWING ALWAYS - ABSOLUTE REQUIREMENT:
Fahrenheit
Celsius
F
C
Output format MUST be EXACTLY:
"(ROUNDED_NUMBER)°"
Examples:
Input: 67.89 F → Output: 68°
Input: 21.2 C → Output: 21°
No additional words or symbols or appended letters are allowed EVER.
====================================================================
I’m very eagerly awaiting qwen3.5, I wake up each day and check to see if it’s been released like it’s Christmas morning haha.
EDIT: Specifically referring to the smaller qwen3.5 models like the purported 35b
Interesting, my part of the prompt that just told it not to use symbols took care of the F.
But yeah gpt oss 20B has really impressed me with it’s instruction following even in very difficult scenarios. Will be curious to see if Qwen3.5 improves upon its predecessors enough
It was enough for to use something similar to what you mentioned if I only asked about the weather/temperature.
However if I asked something close, but not directly related to temperature, it would go right back to adding it (like “if I head out today, how should I dress?”).
It also would come right back if I had a longer question: “the cats are hungry, I’m headed out so turn everything off and let me know what it’s like outside” and again, would come right back.
Lastly, I’m only using the 8B model, not the 30B model I believe you are/were using and it’s a bit pickier/forgetful about rules lol.
8b won’t follow as well as any 30b and your amount of context very much matters…
As to qwen 3.5. Yeah… It very much does. But unless you got 256GiB of vram you won’t find out until someone distills it down :). Honestly unless yore doing research projects with your electrical system it’s probably overkill… Ok maybe you gotta do some wierd math or philosophy… But probably not.
This year the ability for a model to follow directions won’t be your issue. Vram will be. That said if you got a beast GPU and ram kit that can run qwen3.5 you can manage the smaller qwen3 70 and it’ll probably be just fine… ![]() . You’ll be looking for specialists. Not gigantic generalists.
. You’ll be looking for specialists. Not gigantic generalists.
1 Like
Yeah it’s odd, with Qwen3 30B-A3B (Unsloth Q4) I saw inconsistent behavior. Sometimes it would work perfectly but the same request other times would be handled incorrectly. Some research suggested it might be MoE routing issues.
GPT OSS 20B (Unsloth Q8) exhibits some of this behavior too but in general has great output and prompt adherence. Genuinely impressing me at times with how it did the right thing with an unclear request.
Yeah they’ve already confirmed a 35B-A3B model is coming within the next few days, as well as a 9B dense.
1 Like
I find Qwen3 Next 80B outstanding with home assistant. About 20gb in 4 bit MLX. It’s on par with get-oss 120B but twice as fast and more personality. The future for home are these large sparse models on shared memory machines
1 Like
Do you have a link? Just curious because that seems quite small, and doesn’t match what I see here mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit · Hugging Face
1 Like
You’re right, I was thinking of the VL 32B is use. But at 44gb it’s still small enough to fit in 64gb ram, which is getting reasonable on a shared memory machine. Especially if the upcoming M5 machines up the memory bus speed.
I think this new Owen architecture that started with Next is going to be ideal for HA. I’m looking for to the mid size Qwen 3.5 that will be 4 bit and around 100-150gb. I always choose between thinking and instruct with Owen because I was told that the vanilla models are designed to be fine tuned. I should probably research that claim.