I have been watching HomeAssistant’s progress with assist for some time. We previously used Google Home via Nest Minis, and have switched to using fully local assist backed by local first + llama.cpp (previously Ollama). In this post I will share the steps I took to get to where I am today, the decisions I made and why they were the best for my use case specifically.
Links to Additional Improvements
Here are links to additional improvements posted about in this thread.
New Features
Fixing Unwanted HA / LLM Behaviors
- Overriding the default HassGetWeather intent to have consistent weather outputs
- Improving handling of unclear requests / false activations
- Automatically handle obvious transcription errors
- Optimizing prompt to reduce bloat and token usage
Optimizing Performance
Hardware Details
I have tested a wide variety of hardware from a 3050 to a 3090, most modern discrete GPUs can be used for local assist effectively, it just depends on your expectations of capability and speed for what hardware is required.
I am running HomeAssistant on my UnRaid NAS, specs are not really important as it has nothing to do with HA Voice.
Voice Hardware:
- 1 HA Voice Preview Satellite
- 2 Satellite1 Small Squircle Enclosures
- 1 Pixel 7a used as a satellite/ hub with View Assist
Voice Server Hardware:
- Beelink MiniPC with USB4 (the exact model isn’t important as long as it has USB4)
- USB4 eGPU enclosure
GPUs
The below table shows GPUs that I have tested with this setup. Response time will vary based on the model that is used.
| GPU | Model Class | Response Time (after prompt caching) | Notes |
|---|---|---|---|
| RTX 3090 24GB | 20B-30B MoE, 9B Dense | 1 - 2 seconds | Efficiently and quickly runs models that are optimal for this setup. |
| RX 7900XTX 24GB | 20B-30B MoE, 9B Dense | 1 - 2 seconds | Efficiently and quickly runs models that are optimal for this setup. |
| RTX 5060Ti 16GB | 20B MoE, 9B Dense | 1.5 - 3 seconds | Quick enough to run models that are optimal for this setup with responses < 3 seconds. |
| RX 9060XT 16GB | 20B MoE, 9B Dense | 1.5 - 4 seconds | Quick enough to run models that are optimal for this setup with responses < 4 seconds. |
| RTX 3050 8GB | 4B Dense | 3 seconds | Good for running small models with basic functionality. |
Models
The below table shows the models I have tested using this setup with various features and their performance.
All models below are good for basic tool calling. Advanced features are listed with the models quality at reliably reproducing the desired behavior.
| Model | Multi device tool calls (1) | Understands context cues (2) | Parses misheard commands (3) | Ignores unexpected text from false positives (4) |
|---|---|---|---|---|
| GGML Gemma4 26B-A4B Q4_K_M (thinking off) | ||||
| GGML GPT-OSS:20B MXFP4 (med reasoning effort) | ||||
| Unsloth GLM 4.7 Flash (30B) Q4_K_XL (reasoning enabled) | ||||
| Unsloth Qwen3-VL:8B-Instruct Q6_K_XL | ||||
| Unsloth Qwen3-30B-A3B-Instruct Q4_K_XL | ||||
| Unsloth Qwen3.5-35B-A3B MXFP4_MOE | ||||
| Unsloth GLM 4.7 Flash (30B) Q4_K_XL (reasoning disabled) | ||||
| Unsloth Qwen3:4b-Instruct 2507 Q6_K_XL |
(1) Handles commands like “Turn on the fan and off the lights”
(2) Understands when it is in a particular area and does not ask “which light?” when there is only one light in the area, but does correctly ask when there are multiple of the device type in the given area.
(3) Is able to parse misheard commands (ex: “turn on the pan”) and reliably execute the intended command
(4) Is able to reliably ignore unwanted input without being negatively affected by misheard text that was an intended command.
Voice Server Software:
Model Runner:
llama.cpp is recommended for optimal performance, see my reply below for details.
Speech to Text (Voice In):
The following are Speech to Text options that I have tested:
| Software | Model | Notes |
|---|---|---|
| Wyoming ONNX ASR | Nvidia Parakeet V3 | Tested to be more accurate than V2 with the same speed. |
| Wyoming ONNX ASR | Nvidia Parakeet V2 | Accurate and fast model which can run on CPU via OpenVINO or on Nvidia GPU |
| Rhasspy Faster Whisper | Nvidia Parakeet V2 | Slower due to running directly via ONNX CPU which is slower than OpenVINO |
Text to Speech (Voice Out):
| Software | Notes |
|---|---|
| Kokoro TTS | Provides ability to mix and match multiple voices / tones to get desired output. Handles all text well. |
| Piper running on CPU (TTS) | Has multiple voices which can be picked from, works for general text but struggles with currency, phone numbers, and addresses. |
Home Assistant LLM Integrations
- LLM Conversation Provides improvements to the base conversation to improve default experience talking with Assist
- LLM Intents to provide additional tools for Assist (Web Search, Place Search, Weather Forecast)
The Journey
My point in posting this is not to suggest that what I have done is “the right way” or even something others should replicate. But I learned a lot throughout this process and I figured it would be worth sharing so others could get a better idea of what to expect, pitfalls, etc.
The Problem
Throughout the last year or two we have noticed that Google Assistant through these Nest Minis has gotten progressively dumber / worse while also not bringing any new features. This is generally fine as the WAF was still much higher than not having voice, but it became increasingly annoying as we were met with more and more “Sorry, I can’t help with that” or “I don’t know the answer to that, but according to XYZ source here is the answer”. It generally worked, but not reliably and was often a fuss to get answers to arbitrary questions.
Then there is the usual privacy concern of having online microphones throughout your home, and the annoyance that every time AWS or something else went down you couldn’t use voice to control lights in the house.
Starting Out
I started by playing with one of Ollama’s included models. Every few weeks I would connect Ollama to HA, spin up assist and try to use it. Every time I was disappointed and surprised by its lack of abilities and most of the time basic tool calls would not work. I do believe HA has made things better, but I think the biggest issue was my understanding.
Ollama models that you see on Ollama are not even close to exhaustive in terms of the models that can be run. And worse yet, the default :4b models for example are often low quantization (Q4_K) which can cause a lot of problems. Once I learned about the ability to use HuggingFace to find GGUF models with higher quantizations, assist was immediately performing much better with no problems with tool calling.
Testing with Voice
After getting to the point where the fundamental basics were possible, I ordered a Voice Preview Edition to use for testing so I could get a better idea of the end-to-end experience. It took me some time to get things working well, originally I had WiFi reception issues where the ping was very inconsistent on the VPE (despite being next to the router) and this led to the speech output being stuttery and having a lot of mid-word pauses. After adjusting piper to use streaming and creating a new dedicated IoT network, the performance has been much better.
Making Assist Useful
Controlling device is great, and Ollama’s ability to adjust devices when the local processing missed a command was helpful. But to replace our speakers, Assist had to be capable of the following things:
- Ability to give Day and Week Weather Forecasts
- Ability to ask about a specific business to get opening / closing times
- Ability to do general knowledge lookup to answer arbitrary questions
- Ability to play music with search abilities entirely with voice
At first I was under the impression these would have to be built out separately, but I eventually found the brilliant llm-intents integration which provides a number of these services to Assist (and by extension, Ollama). Once setting these up, the results were mediocre.
The Importance of Your LLM Prompt
For those that want to see it, here is my prompt.
This is when I learned that the prompt will make or break your voice experience. The default HA prompt won’t get you very far, as LLMs need a lot of guidance to know what to do and when.
I generally improved my prompt by taking my current prompt and putting it into ChatGPT along with a description of the current behavior and desired behavior of the LLM. Then back-and-forth attempts until I consistently got the desired result. After a few cycles of this, I started to get a feel of how to make these improvements myself.
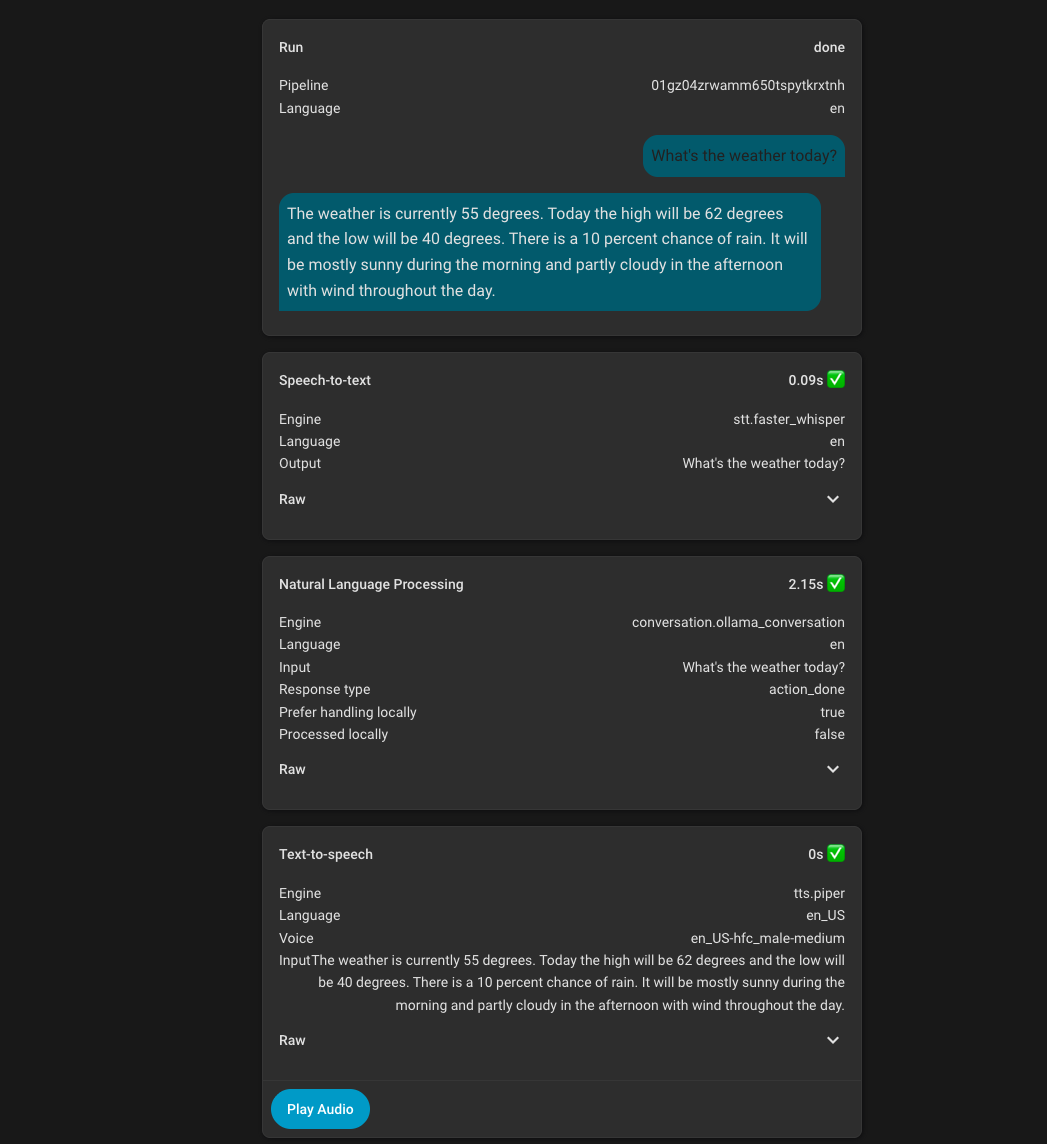
I started by trying to get weather working, the first challenge was getting the LLM to even call the weather service. I have found that having dedicated # sections for each service that is important along with a bulleted list of details / instructions works best.
Then I needed to make the weather response formatted in a way that was desirable without extra information. At first, the response would include extra commentary such as “sounds like a nice summery day!” or other things that detracted from the conciseness of the response. Once this was solved, a specific example of the output worked best to get the exact response format that was desired.
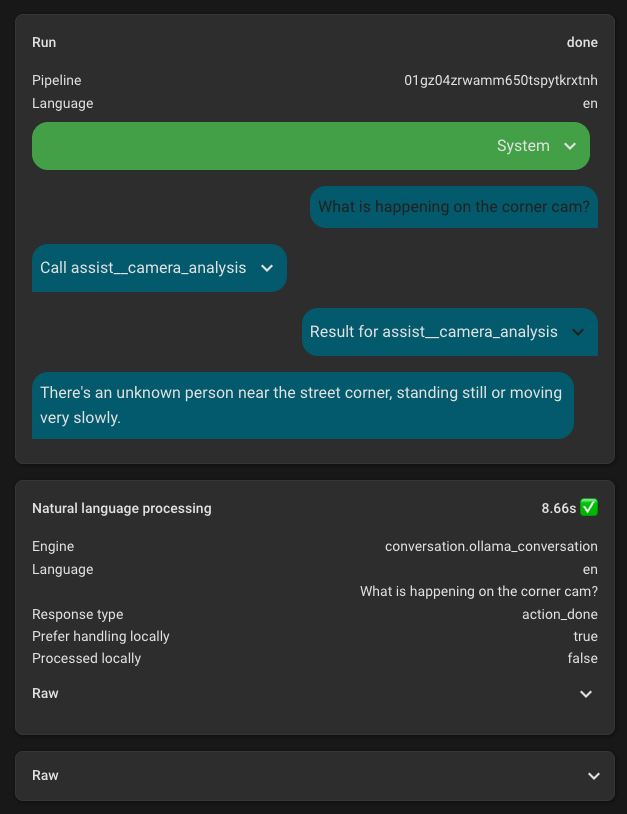
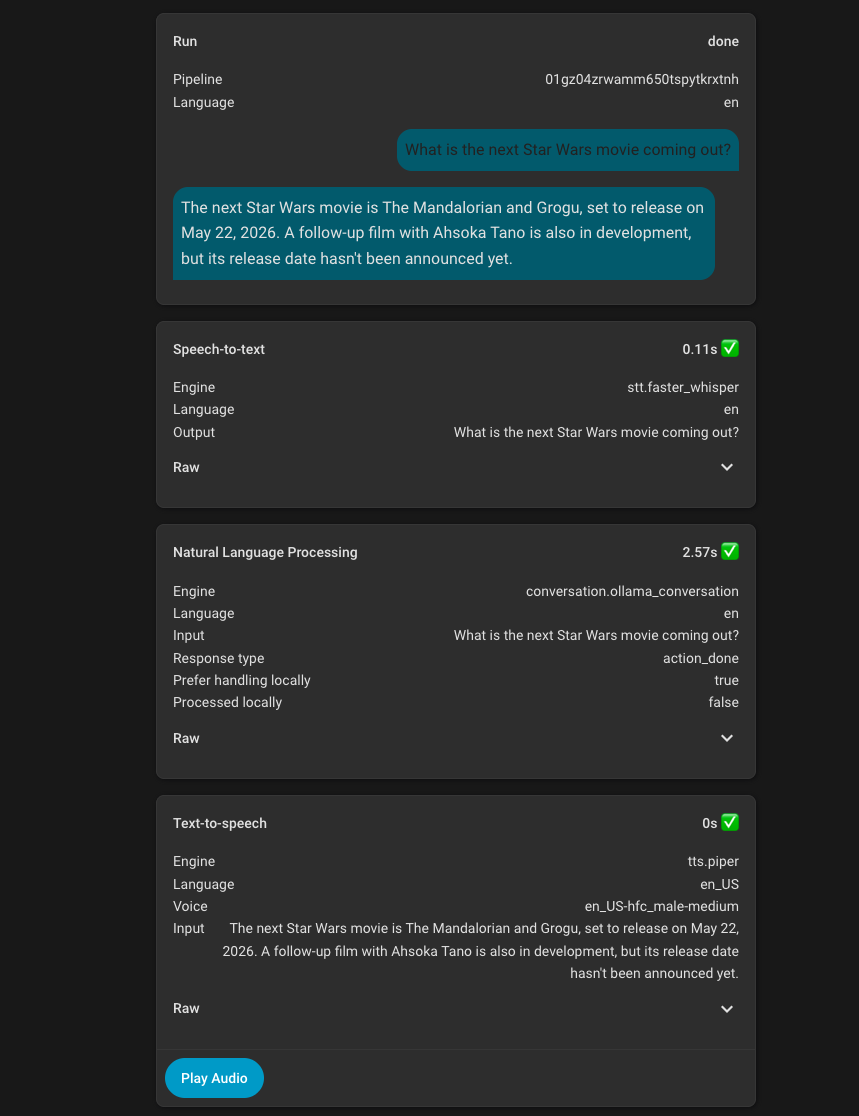
For places and search, the problem was much the same, it did not want to call the tool and instead insisted that it did not know the user’s location or the answer to specific questions. This mostly just needed some specific instructions to always call the specific tool when certain types of questions were asked, and that has worked well.
The final problem I had to solve was emojis, most responses would end with a smiley face or something, which is not good to TTS. This took a lot of sections in the prompt, but overall has completely removed it without adverse affects.
Solving Some Problems Manually
NOTE: Not sure if a recent Home Assistant or Music Assistant update improved things, but the LLM is now able to naturally search and play music without the automation. I am leaving this section in as an example, as I still believe automations can be a good way to solve some problems when there is not an easy way to give the LLM access to a certain feature.
It is certainly the most desirable outcome that every function would be executed perfectly by the LLM without intervention, but at least in my case with the model I am using that is not true. But there are cases where that really is not a bad thing.
In my case, music was one of this case. I believe this is an area that improvements are currently be made, but for me the automatic case was not working well. I started by getting music assistant setup. I found various LLM blueprints to create a script that allows the LLM to start playing music automatically, but it did not work well for me.
That is when I realized the power of the sentence automation trigger and the beauty of music assistant. I create an automation that triggers on Play {music}. The automation has a map of assist_satellite to media_player in the automation, so it will play music on the correct media player based on which satellite makes the request. Then it passes {music} (which can be a song, album, artist, whatever) to music assistant’s play service which performs the searching and starts playing.
Example Automation
alias: Music Shortcut
description: ""
triggers:
- trigger: conversation
command:
- Play {music}
id: play
- trigger: conversation
command: Stop playing
id: stop
conditions: []
actions:
- choose:
- conditions:
- condition: trigger
id:
- play
sequence:
- action: music_assistant.play_media
metadata: {}
data:
media_id: "{{ trigger.slots.music }}"
target:
entity_id: "{{ target_player }}"
- set_conversation_response: Playing {{ trigger.slots.music }}
- conditions:
- condition: trigger
id:
- stop
sequence:
- action: media_player.media_stop
metadata: {}
data: {}
target:
entity_id: "{{ target_player }}"
- set_conversation_response: Stopped playing music.
variables:
satellite_player_map: |
{{
{
"assist_satellite.home_assistant_voice_xyz123": "media_player.my_desired_speaker",
}
}}
target_player: |
{{
satellite_player_map.get(trigger.satellite_id, "media_player.default_speaker")
}}
mode: single
Training a Custom Wakeword
The next problem to solve was the wakeword. For WAF the default included options weren’t going to work. After some back and forth we decided on Hey Robot. I use this repo to train a custom microwakeword which is usable on the VPE and Satellite1. This only took ~30 minutes to run on my GPU and the results have been quite good. There are some false positives, but overall the rate is similar to the Google Homes that have been replaced and with the ability to automate muting it is possible we can solve that problem with that until the training / options become better.
The End Result
I definitely would not recommend this for the average Home Assistant user, IMO a lot of patience and research is needed to understand particular problems and work towards a solution, and I imagine we will run into more problems as we continue to use these. I am certainly not done, but that is the beauty of this solution - most aspects of it can be tuned.
The goal has been met though, overall we have a more enjoyable voice assistant that runs locally without privacy concerns, and our core tasks are handled reliably.
Let me know what you think! I am happy to answer any questions.