This year is Home Assistant’s Year of the Voice. It is our goal for 2023 to let users control Home Assistant in their own language. Today we’re presenting Chapter 2, our second milestone in building towards this goal.
In Chapter 1, we focused on intents – what the user wants to do. Today, the Home Assistant community has translated common smart home commands and responses into 45 languages, closing in on the 62 languages that Home Assistant supports.
For Chapter 2, we’ve expanded beyond text to now include audio; specifically, turning audio (speech) into text, and text back into speech. With this functionality, Home Assistant’s Assist feature is now able to provide a full voice interface for users to interact with.
A voice assistant also needs hardware, so today we’re launching ESPHome support for Assist and; to top it off: we’re launching the World’s Most Private Voice Assistant. Keep reading to see what that entails.
To watch the video presentation of this blog post, including live demos, check the recording of our live stream.
Composing Voice Assistants
The new Assist Pipeline integration allows you to configure all components that make up a voice assistant in a single place.
For voice commands, pipelines start with audio. A speech-to-text system determines the words the user speaks, which are then forwarded to a conversation agent. The intent is extracted from the text by the agent and executed by Home Assistant. At this point, “turn on the light” would cause your light to turn on 💡. The last part of the pipeline is text-to-speech, where the agent’s response is spoken back to you. This may be a simple confirmation (“Turned on light”) or the answer to a question, such as “Which lights are on?”
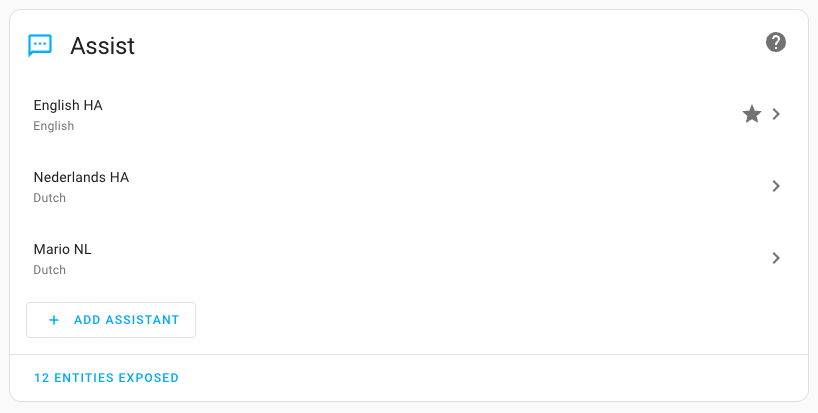 Screenshot of the new Assist configuration in Home Assistant.
Screenshot of the new Assist configuration in Home Assistant.
With the new Voice Assistant settings page users can create multiple assistants, mixing and matching voice services. Want a U.S. English assistant that responds with a British accent? No problem. What about a second assistant that listens for Dutch, German, or French voice commands? Or maybe you want to throw ChatGPT in the mix. Create as many assistants as you want, and use them from the Assist dialog as well as voice assistant hardware for Home Assistant.
Interacting with many different services means that many different things can go wrong. To help users figure out what went wrong, we’ve built extensive debug tooling for voice assistants into Home Assistant. You can always inspect the last 10 interactions per voice assistant.
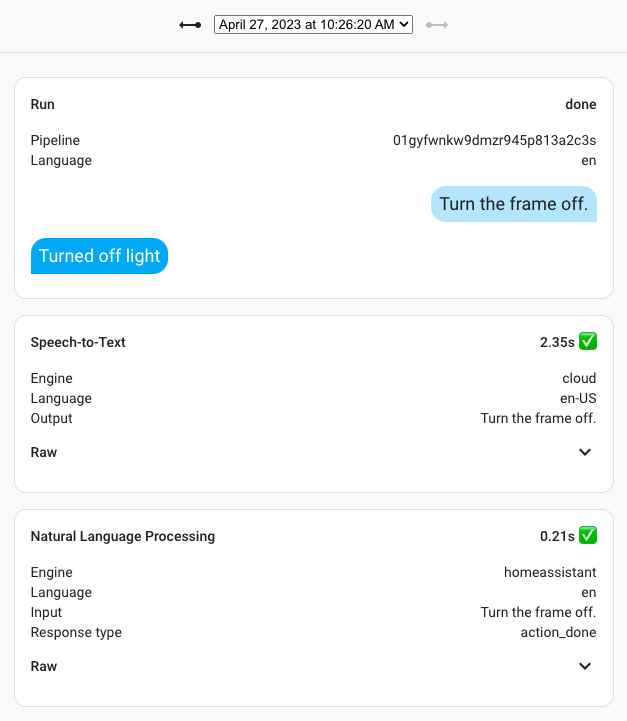 Screenshot of the new Assist debug tool.
Screenshot of the new Assist debug tool.
Voice Assistant powered by Home Assistant Cloud
The Home Assistant Cloud subscription, besides end-to-end encrypted remote connection, includes state of the art speech-to-text and text-to-speech services. This allows your voice assistant to speak 130+ languages (including dialects like Peruvian Spanish) and is extremely fast to respond. Sample:
As a subscriber, you can directly start using voice in Home Assistant. You will not need any extra hardware or software to get started.
In addition to high quality speech-to-text and text-to-speech for your voice assistants, you will also be supporting the development of Home Assistant itself.
Join Home Assistant Cloud today
The fully local voice assistant
With Home Assistant you can be guaranteed two things: there will be options and one of those options will be local. With our voice assistant that’s no different.
Piper: our new model for high quality local text-to-speech
To make quality text-to-speech running locally possible, we’ve had to create our own text-to-speech system that is optimized for running on a Raspberry Pi 4. It’s called Piper.
Piper uses modern machine learning algorithms for realistic-sounding speech but can still generate audio quickly. On a Raspberry Pi 4, Piper can generate 2 seconds of audio with only 1 second of processing time. More powerful CPUs, such as the Intel Core i5, can generate 17 seconds of audio in the same amount of time. Sample:
For more samples, see the Piper website
An add-on with Piper is available now for Home Assistant with over 40 voices across 18 languages, including: Catalan, Danish, German, English, Spanish, Finnish, French, Greek, Italian, Kazakh, Nepali, Dutch, Norwegian, Polish, Brazilian Portuguese, Ukrainian, Vietnamese, and Chinese. Voices for Piper are trained from open audio datasets, many of which come from free audiobooks read by volunteers. If you’re interested in contributing your voice, let us know!
Local speech-to-text with OpenAI Whisper
Whisper is an open source speech-to-text model created by OpenAI that runs locally. Since its release in 2022, Whisper has been improved by the open source community to run on less powerful hardware by projects such as whisper.cpp and faster-whisper. In less than a year of progress, Whisper is now capable of providing speech-to-text for dozens of languages on small servers and single-board computers!
An add-on using faster-whisper is available now for Home Assistant. On a Raspberry Pi 4, voice commands can take around 7 seconds to process with about 200 MB of RAM used. An Intel Core i5 CPU or better is capable of sub-second response times and can run larger (and more accurate) versions of Whisper.
Wyoming: the voice assistant glue
Voice assistants share many common functions, such as speech-to-text, intent-recognition, and text-to-speech. We created the Wyoming protocol to provide a small set of standard messages for talking to voice assistant services, including the ability to stream audio.
Wyoming allows developers to focus on the core of a voice service without having to commit to a specific networking stack like HTTP or MQTT. This protocol is compatible with the upcoming version 3.0 of Rhasspy, so both projects can share voice services.
With Wyoming, we’re trying to kickstart a more interoperable open voice ecosystem that makes sharing components across projects and platforms easy. Developers and scientists wishing to experiment with new voice technologies need only implement a small set of messages to integrate with other voice assistant projects.
The Whisper and Piper add-ons mentioned above are integrated into Home Assistant via the new Wyoming integration. Wyoming services can also be run on other machines and still integrate into Home Assistant.
ESPHome powered voice assistants
ESPHome is our software for microcontrollers. Instead of programming, users define how their sensors are connected in a YAML file. ESPHome will read this file and generate and install software on your microcontroller to make this data accessible in Home Assistant.
Today we’re launching support for building voice assistants using ESPHome. Connect a microphone to your ESPHome device, and you can control your smart home with your voice. Include a speaker and the smart home will speak back.
We’ve been focusing on the M5STACK ATOM Echo for testing and development. For $13 it comes with a microphone and a speaker in a nice little box. We’ve created a tutorial to turn this device into a voice remote directly from your browser!
Tutorial: create a $13 voice remote for Home Assistant.
ESPHome Voice Assistant documentation.
World’s Most Private Voice Assistant
If you were designing the world’s most private voice assistant, what features would it have? To start, it should only listen when you’re ready to talk, rather than all the time. And when it responds, you should be the only one to hear it. This sounds strangely familiar…🤔
A phone! No, not the featureless rectangle you have in your pocket; an analog phone. These great creatures once ruled the Earth with twisty cords and unique looks to match your style. Analog phones have a familiar interface that’s hard to beat: pick up the phone to listen/speak and put it down when done.
With Home Assistant’s new Voice-over-IP integration, you can now use an “old school” phone to control your smart home!
By configuring off-hook autodial, your phone will automatically call Home Assistant when you pick it up. Speak your voice command or question, and listen for the response. The conversation will continue as long as you please: speak more commands/questions, or simply hang up. Assign a unique voice assistant/pipeline to each VoIP adapter, enabling dedicated phones for specific languages.
We’ve focused our initial efforts on supporting the Grandstream HT801 Voice-over-IP box. It works with any phone with an RJ11 connector, and connects directly to Home Assistant. There is no need for an extra server.
Tutorial: create your own World’s Most Private Voice Assistant
Give your voice assistant personality using the OpenAI integration.
Some links on this page are affiliate links and purchases using these links support the Home Assistant project.
This is a companion discussion topic for the original entry at https://www.home-assistant.io/blog/2023/04/27/year-of-the-voice-chapter-2/
