Hello,
I’m trying to diagnose why my Core restarts three to ten times per day so that I can solve the issue.
The time is not regular, although one of them is often around when my children go to bed → lights don’t turn off, WAF reduces rapidly, sadtimes.
Although as I say it isn’t always exactly the same time and may be a red herring.
I’m fairly technical, but having difficulty finding an error message that I can get my teeth into, and this is where I would appreciate some guidance.
I’ve been looking into this on and off for months, and have got nowhere useful!
Indication
2025-05-13 12:45:11.331 ERROR (MainThread)[homeassistant.components.hassio.handler] Timeout on /info request**
2025-05-13 12:45:11.350 ERROR (MainThread) [homeassistant.components.hassio.handler] Timeout on /core/info request
2025-05-13 12:45:11.354 ERROR (MainThread) [homeassistant.components.hassio.handler] Timeout on /supervisor/info request
2025-05-13 12:45:11.361 ERROR (MainThread) [homeassistant.components.hassio.handler] Timeout on /os/info request
2025-05-13 12:45:11.365 ERROR (MainThread) [homeassistant.components.hassio.handler] Timeout on /network/info request
2025-05-13 12:45:11.373 ERROR (MainThread) [homeassistant.components.hassio.handler] Timeout on /host/info request
2025-05-13 12:45:12.452 WARNING (MainThread) [asyncio] Executing <Handle _SelectorSocketTransport._read_ready()> took 1.052 seconds
2025-05-13 12:45:13.040 WARNING (MainThread) [asyncio] Executing <Handle _SelectorSocketTransport._read_ready()> took 0.531 seconds
2025-05-13 12:45:13.050 WARNING (MainThread) [homeassistant.components.hassio] Can't read Supervisor data:
2025-05-13 12:45:13.318 WARNING (MainThread) [asyncio] Executing <Task finished name='System Monitor update coordinator - System Monitor - refresh' coro=<DataUpdateCoordinator._handle_refresh_interval() done, defined at /usr/src/homeassistant/homeassistant/helpers/update_coordinator.py:265> result=None created at /usr/src/homeassistant/homeassistant/util/async_.py:45> took 0.263 seconds
2025-05-13 12:45:13.699 WARNING (MainThread) [asyncio] Executing <Handle _SelectorSocketTransport._read_ready()> took 0.348 seconds
What my family experiences is buttons/motionlights not working.
What I experience is the GUI timing out, and the restarting, and then all the usual messages at the bottom of the screen “XYZ is starting, HA won’t be ready until all blah blahs has started”, which tells me the Core has just restarted.
H/W
I run a HA Yellow
S/W
The most recent updates, 2025.5.1.
However, I’ve noticed this issue for the last ~6 months at a rough guess.
At first it was “oh this button isn’t working for 30seconds”, but then I saw a wider problem. I’m busy so haven’t solved the problem yet!
Stats
Although timeouts of the Core appear to be why the Supervisor restarts it, it doesn’t appear to be due to high utilisation:

The spikes don’t correlate with the times of restarts. The big 5:20am spikes are backups, but even then I don’t get high util. Sunday/Monday util is higher, but because of the next points.
Debugging
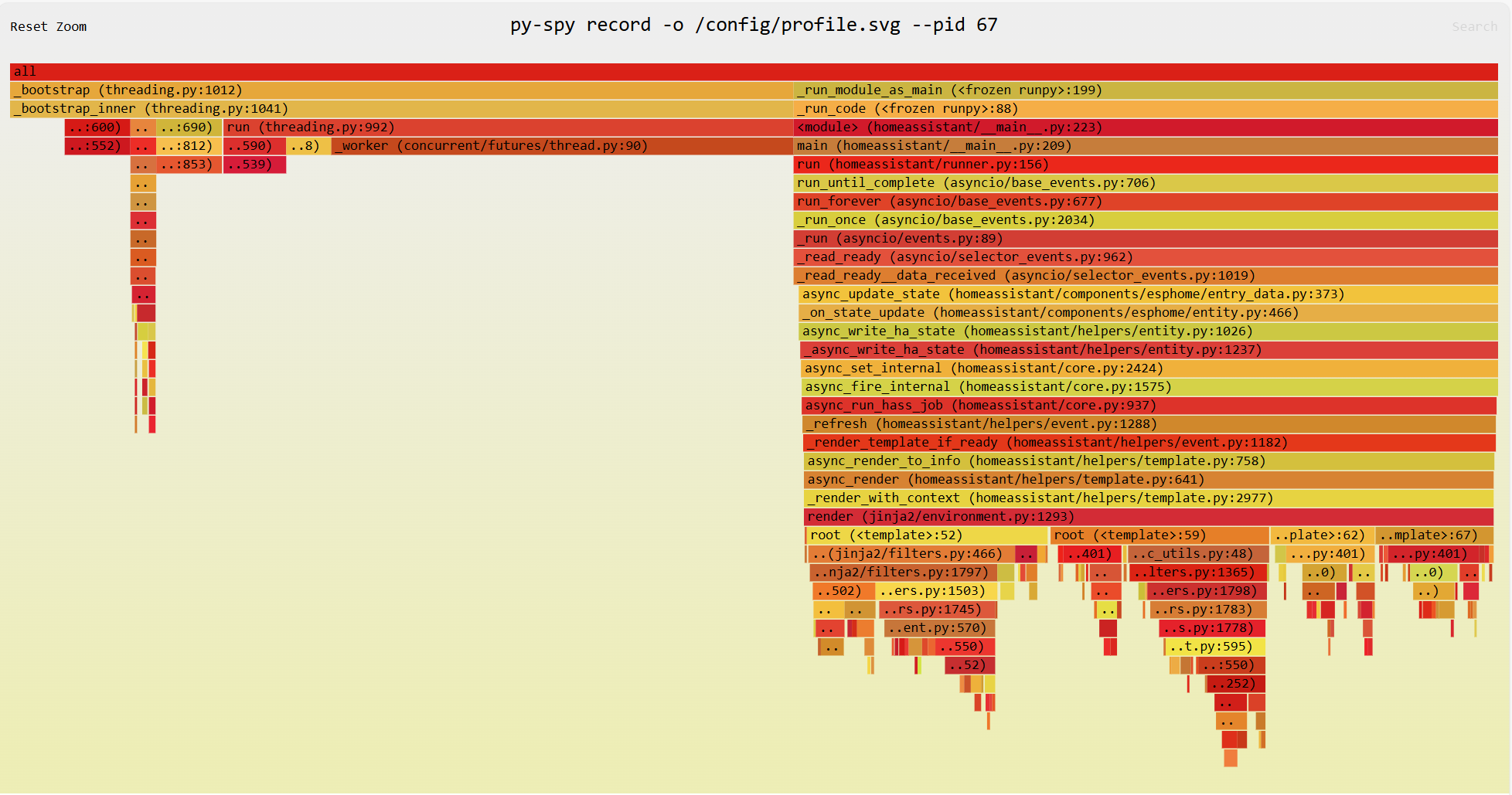
As per 2024.5+: Tracking down instability issues caused by integrations
I have enabled debug:
homeassistant:
enabled: true
debug: true
I have booted into safemode.
I have installed Profiler.
I have enabled Asyncio Debug Mode at Runtime.
I have also disabled a number of built-in integrations that are not necessary for my house to function, although not all integrations are disabled.
I have disabled my main complicated automations, i.e. a multi-templated motion/light one that I wrote - it’s beautiful - all the house in one automation, but I digress, it’s disabled.
I cannot see any particular “related” errors in any logs, other than the timeouts. I appreciate there are errors in the logs, but they don’t seem to be the faults!
A WLED light seems to have invalid response, generic error.
[homeassistant.components.websocket_api.http.connection] [546876652928] Error handling message: Unknown error (unknown_error) - great, thanks for that.
WARNING (MainThread) [idasen] [E4:DB:71:37:B9:DF] Failed to connect, retrying (1/3)... buggy since I got it, but it works.
Occasional PiHole (on separate Pi) connection errrors, but not always at same time as restarts.
I can’t see any particular problems in Supervisor or Host logs. I may have missed something of course! I can’t see how to attach the logs though!
I disabled the main erroring integrations/automations last night, and so the later logs have less mention of those!
Although no automations in particular appear to be hanging, just the whole system when it restarts.
Any advice on other steps I can take to diagnose would be appreciated. I have the logs although I can’t find where to upload them during the topic creation!
Thanks,
Richard