I’m using a Rpi4 with 8GB ram. Add-ons are: DuckDNS, ESPHome, Grafana, InfluxDB, Google Drive Backup, Network UPS Tools, Node-RED, Samba Share, deCONZ.
I went from HA 0.116.4 to 0.117.0 and I noticed on my Grafana graphs for Rpi memory that there was a gradual increase in memory usage, which was unusual. To the point it was double “normal” use in a few hours.
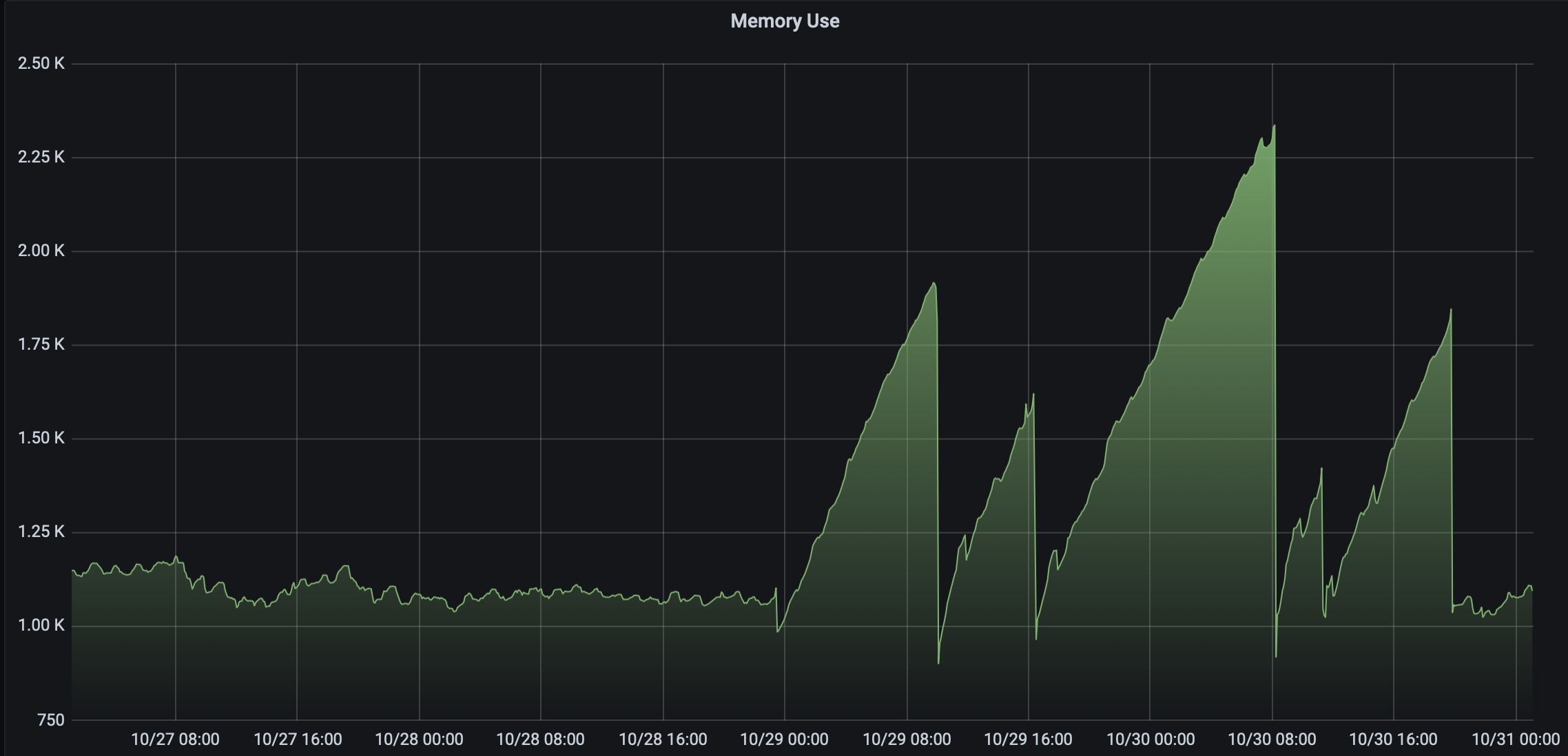
The attached image is over 4 days, and there are five sloping increases which I will explain. I’ve included previous time when I was using 0.116.4 to show it was “calm”. The first ramp increase is when I upgraded from 0.116.4 to 0.117.0. This is abnormal behaviour from what I have seen previously over the past nine months. On the same day HA updated, Grafana also updated from 5.3.2 to 5.3.3, and I will come to this later.
When the first ramp peak started, I rebooted the machine to clear the ram and maybe stop something running that was causing it. I left it for a few hours and so there is a second ramp up in memory use.
After the second ramp up after the soft reboot, I physically shut the RPi down completely. Shutdown, power off, power on. This then caused the third ramp to develop.
I then tried to eliminate Grafana from being the problem by rolling that back to 5.3.2 (which solved an iOS Grafana panel issue, but that’s another thing) but the memory continued to increase into a fourth ramp, which got as high as 2.3GB of ram used as compared to just over 1GB normally.
I noticed 0.117.1 was available, so I updated to that, thinking maybe that would solve the problem. That’s when the fifth ramp developed.
As a last resort, I rolled back to 0.116.4, low and behold the memory has levelled back out again to what it was before.
So the culprit is something in 0.117.0 and above which is causing the RPi to gobble up memory usage. In correlation to memory usage, it’s also increasing CPU usage which follows a similar pattern, and then also that obviously causes a temperature increase which also follows the same pattern.
So, has anyone else who is monitoring their RPi parameters using Grafana seeing a similar increase in memory usage after updating to 0.117.0 and above?
I have mentioned this in the Discord channels.
Steady ram usage: 0.116.4
Ramp 1: update to 0.117.0
Ramp 2: soft reboot
Ramp 3: hard reboot
Ramp 4: Grafana rollback
Ramp 5: Update to 0.117.1
Back to steady ram usage: rolled back to 0.116.4