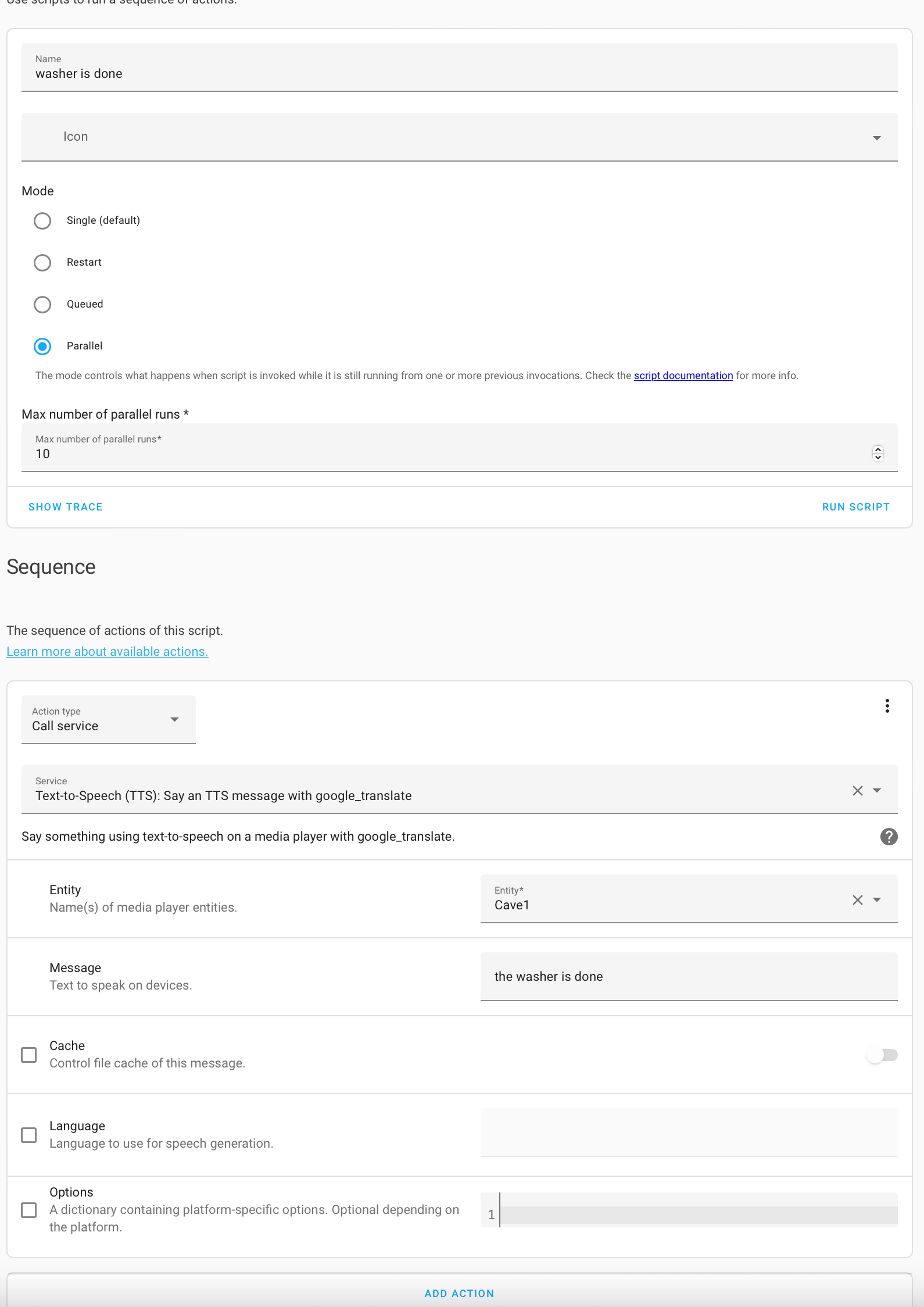
This script blueprint uses a Text-to-Speech service to play messages on Sonos speakers. The script
handles oddities to ensure a proper message playing experience. Examples include:
- Saving the state of the Sonos and restoring when done (so music will stop and continue)
- Handling speakers in groups (for both old and newer versions of HA)
- Pausing music so volume adjustments don’t impact current music
- Applies volume to all grouped speakers
- Independent of volume, unmutes all grouped speakers
- Disabling repeat so that the announcement doesn’t repeat
- Handling delays to ensure proper handling of volume setting and playback cut-offs
The following field parameters can be given when the script is called:
- [required] Sonos speaker
- [required] Text of the message to say
- [optional] Volume for message playback. This only impacts the indicated speaker, not the group, and reverts when done.
- [optional] Minimum number of seconds that the system will wait after state changes in Sonos
The following blueprint inputs can be given when creating the script:
-
[optional] Text-to-Speech Service engine to use to say the specified message. Default is
google_translate_say. -
[optional] Language to say messages in. Default is
en.
This script is particularly convenient when:
- You want to announce something on a Sonos speaker but want the speakers to continue what they were doing when playback completes (e.g. opening a dishwasher and announcing the dishes are clean on a kitchen speaker)
Additional Notes
- I recommend setting the mode to
parallelwhen using the same script for multiple automations
![]()
# ***************************************************************************
# * Copyright 2022-2023 Joseph Molnar
# *
# * Licensed under the Apache License, Version 2.0 (the "License");
# * you may not use this file except in compliance with the License.
# * You may obtain a copy of the License at
# *
# * http://www.apache.org/licenses/LICENSE-2.0
# *
# * Unless required by applicable law or agreed to in writing, software
# * distributed under the License is distributed on an "AS IS" BASIS,
# * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# * See the License for the specific language governing permissions and
# * limitations under the License.
# ***************************************************************************
# Announces the provided message on the specified speaker.
blueprint:
name: "Text-to-Speech on Sonos"
description:
This blueprint is used to add a script that will say messages on Sonos speakers. The script
handles oddities to ensure a proper experience including saving/restore state, handling
speaker groups, unmuting, pausing music, disabling repeat, adding delays, etc.
I recommend setting the mode to parallel if you will use this script on more than one speaker.
domain: script
input:
tts_service_name:
name: Text-To-Speech Service Name
description:
The text-to-speech service to use when saying the message. This must match your Home
Assistant configuration.
default: "google_translate_say"
selector:
text:
tts_language:
name: Language
description: The language to use with the text-to-speech service.
default: "en"
selector:
text:
fields:
entity_id:
description: The entity id of the Sonos speaker that will play the message.
name: Entity
required: true
selector:
entity:
domain: media_player
integration: sonos
message:
description: The text that will be played.
name: Message
required: true
selector:
text:
volume_level:
name: "Volume Level"
description:
Float for volume level. Range 0..1. If value isn't given, volume isn't changed.
The volume will revert to the previous level after it plays the message.
required: false
selector:
number:
min: 0
max: 1
step: 0.01
mode: slider
min_wait:
name: "Minimum Wait"
description:
The minimum number of seconds that the system will wait for state changes from
Sonos. Frequently the Sonos integration reports state changes too early, misses
some state quick enough which can result in odd volume changes, cut-off messages
and even, when the message is very short, long delays before continuing to play
previously running media. Setting this value will help. Defaults to 0 if not set.
required: false
selector:
number:
min: 0
max: 60
step: 0.25
unit_of_measurement: seconds
mode: slider
max_wait:
name: "Maximum Wait"
description: THIS IS DEPRECATED AND WILL BE REMOVED IN FUTURE VERSIONS
required: false
selector:
number:
min: 1
max: 60
step: 0.25
unit_of_measurement: seconds
mode: slider
variables:
entity_group: >-
{# some operations we will be doing against the group, so need the group #}
{%- set group_members = state_attr( entity_id, "group_members" ) -%}
{%- if group_members == None -%}
{# we maybe on an older version of HA, so look for a different group name#}
{%- set group_members = state_attr( entity_id, "sonos_group" ) -%}
{%- if group_members == None -%}
{{ entity_id }}
{%- else -%}
{{ group_members | join(', ') }}
{%- endif -%}
{%- else -%}
{{ group_members | join(', ') }}
{%- endif -%}
entity_group_leader: >-
{# we see if in a group since the repeat is typically controlled by it #}
{# we use this for doing all the work since it is the primary speaker #}
{# and everything will be shared across speakers anyhow #}
{%- set group_members = state_attr( entity_id, "group_members" ) -%}
{%- if group_members == None -%}
{# we maybe on an older version of HA, so look for a different group name#}
{%- set group_members = state_attr( entity_id, "sonos_group" ) -%}
{%- if group_members == None -%}
{{ entity_id }}
{%- else -%}
{{ group_members[0] }}
{%- endif -%}
{%- else -%}
{# the first seems to be the control, at least on Sonos #}
{{ group_members[0] }}
{%- endif -%}
entity_repeat_state: >-
{# we grab the repeat state so that if in repeat mode we turn off #}
{# and also sanity check that we got a value otherwise default to off #}
{%- set repeat = state_attr( entity_group_leader, "repeat" ) -%}
{%- if repeat == None -%}
off
{%- else -%}
{{ repeat }}
{%- endif -%}
# oddly you can't get blueprint inputs directly into jina so . . .
# 1) putting service into a variable to verify values and provide default
tts_hack: !input tts_service_name
tts_engine: >-
{%- if tts_hack is undefined or tts_hack== None or tts_hack == "" -%}
tts.google_translate_say
{%- else -%}
tts.{{ tts_hack }}
{%- endif -%}
# 2) putting language into a variable to verify values and provide default
lang_hack: !input tts_language
tts_language: >-
{%- if lang_hack is undefined or lang_hack== None or lang_hack == "" -%}
"en"
{%- else -%}
{{ lang_hack }}
{%- endif -%}
# the state delay is used for forcing a wait after key state changes
# since the Sonos integration seems to report state too early which can cause
# audio being cut-off or volume changes being heard that shouldn't be.
state_delay: >-
{%- if min_wait is undefined or min_wait == None or not (min_wait is number) or min_wait < 0 -%}
{# bad or missing data means we just use a default of 0 #}
00:00:00
{%- else -%}
{{ "00:00:" + "{:02d}".format(min_wait | int ) + "." + "{:03d}".format( ( ( min_wait - ( min_wait | int ) ) * 1000 ) | int ) }}
{%- endif -%}
sequence:
# save current state so we can restore to whatever was happening previously
- service: sonos.snapshot
data:
entity_id: "{{ entity_group_leader }}"
with_group: true
# if something is playing, we pause...this is nice if you are changing the
# volume since you won't hear the volume adjust on what is currently playing
- choose:
- conditions:
- condition: template
value_template: >
{{ is_state(entity_group_leader, 'playing') }}
sequence:
# so we pause (using the leader, since that will cover all)
- service: media_player.media_pause
data:
entity_id: "{{ entity_group_leader }}"
# do a quick to make sure it isn't playing
- wait_template: "{{ states( entity_group_leader ) != 'playing' }}"
timeout:
seconds: 2
# we then put in a slight delay to ensure the pause
- delay: >-
{{ state_delay }}
default: []
# we check to see if the player is in repeat state and turn off otherwise
# the alarm announcement will repeat forever
- choose:
- conditions: >
{{ entity_repeat_state != "off" }}
sequence:
- service: media_player.repeat_set
data:
repeat: "off"
entity_id: "{{ entity_group_leader }}"
- wait_template: "{{ state_attr( entity_group_leader, 'repeat' ) == 'off' }}"
timeout:
seconds: 4
default: []
# we set the volume if it is defined, but do so far all speakers in the group
- choose:
- conditions: >
{{ volume_level is defined and volume_level != None and volume_level is number }}
sequence:
# now we can set the set the volume
- service: media_player.volume_set
data:
volume_level: "{{ volume_level }}"
entity_id: >
{{ entity_group }}
# force to unmute, just in case, since mute IS different than volume
- service: media_player.volume_mute
data:
entity_id: >
{{ entity_group }}
is_volume_muted: false
# FINALLY the actual call to say the message
- service: "{{ tts_engine }}"
data:
entity_id: "{{ entity_group_leader }}"
message: "{{ message }}"
language: "{{ tts_language }}"
# not sure why, but setting the repeat doesn't always properly take
# I can see it changing in the state when the TTY goes the repeat
# turns back on ... calling to turn off again helps
- service: media_player.repeat_set
data:
repeat: "off"
entity_id: "{{ entity_group_leader }}"
# first we wait for it to start to properly announce the time
- wait_template: "{{ states( entity_group_leader ) == 'playing' }}"
timeout:
seconds: 2 # timeout so doesn't sit forever
# we put a slight delay in here to ensure that the grabbing of the media
# duration below is likely to succeed, which tends to be crucial for short
# messages, otherwise it seems to take the full media length from what was
# previously playing
- delay: >-
{{ state_delay }}
# then we wait for it to finish announcing before we continue
- wait_template: "{{ states( entity_group_leader ) != 'playing' }}"
timeout: >-
{# we grab the duration to try to set a wait that is roughly the right amount of time #}
{# this is returned in seconds, so not extact accurate #}
{% set duration = state_attr(entity_group_leader, 'media_duration') %}
{% if duration == None or duration <= 1 %}
{# this should never happen, though sounds like there can be delays in response #}
{# to get the state, so we put a mininum of one second ... the waiting for the state #}
{# below should cover BUT if it doesn't than state_delay can make sure we are good #}
{{ "00:00:01" }}
{% else %}
{# adding a second, just to help with potential cut-off #}
{% set duration = duration + 1 %}
{% set seconds = duration % 60 %}
{% set minutes = (duration / 60)|int % 60 %}
{% set hours = (duration / 3600)|int %}
{{ "{:02d}".format(hours) + ":" + "{:02d}".format(minutes) + ":" + "{:02d}".format(seconds) }}
{% endif %}
# we then put in a slight delay to ensure the playing finished
- delay: >-
{{ state_delay }}
# and now we restore where we were which should cover repeat, what's playing, etc.
# NOTE: so far this works when driven by Sonos or HA, but when driven from Alexa
# it doesn't seem to work as well
- service: sonos.restore
data:
entity_id: "{{ entity_group_leader }}"
with_group: true
mode: parallel
max_exceeded: silent
icon: mdi:account-voice
Revisions
-
2023-01-14:
volume_level, if given, is applied to all grouped speakers, simplified wait handling (should never wait unexpectantly long anymore and deprecatedmax_wait), and forcibly unmutes speakers based on feedback from @0_0 - 2022-10-28: Better volume value checking and added delay afer playing the message to help short message playback
-
2022-10-15: Added
min_waitto help with HA reporting Sonos state changes too early, and changedmax_waitand delay handling based on feedback from @krazykaz83 - 2022-05-25: Initial release
Available Blueprints
- Automation: Lutron Pico Media Remote for Contextually Handling Music or Xbox on Sonos Speakers
- Automation: Automation for Sonos + Lutron Picos to Magically Manage Sleep Alarms and Music
- Script: Script for Sonos Speakers to do Text-to-Speech and Handle Typical Oddities
- Script: Script for Sonos Speakers to Announce Upcoming Alarm
- Script: Script for Sonos Speakers to Stop Current Alarm or Temporarily Disable Upcoming Alarm
- Script: Play Random Media w/ Shuffle, Repeat, Multi-room, Volume support
- Script: Play Media w/ Shuffle, Repeat, Multi-room, Volume support
- Others in my GitHub repository







 )?
)?