Problem
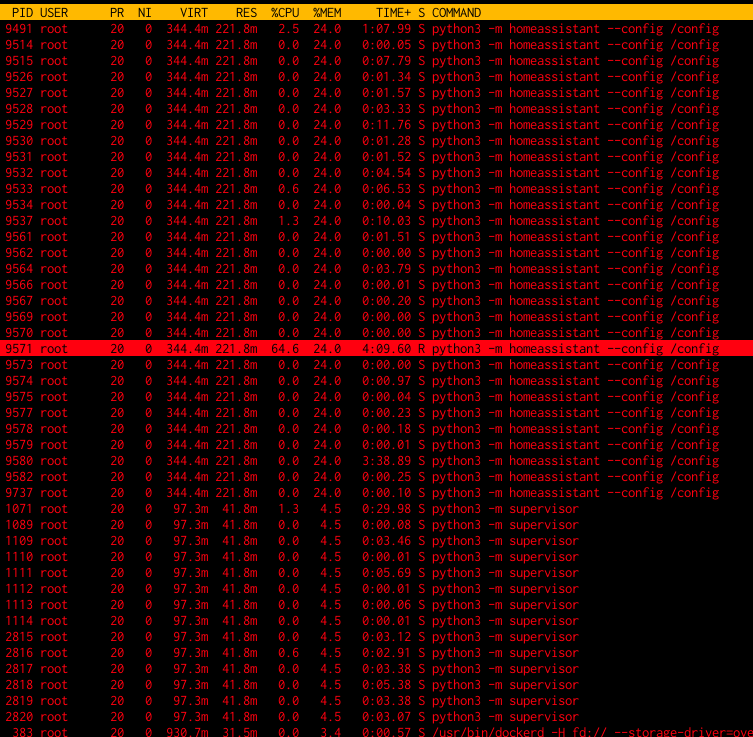
There is one Python thread that is using a very high amount of CPU. As consequence, my RPi is running constantly hot, and the overall system is noticeably slower. While HA is starting up, the CPU loadavg gets over 5 or even over 8. After the system running “idle” for a while, the loadavg goes down to between 1.0 and 1.1.


Question/Objective
How can I figure out which integration (or which code) is causing this high CPU usage?
I have dozens of integrations enabled, and I’d love to be able to track down this issue without having to manually disable each one of them.
Once I know what code causes this issue, I can take action (either disable the integration, or change some parameter, or report the bug to the authors).
System
HAOS running on RPi 3.
Right now it’s running HA 2022.3.8, but I noticed it since I upgraded from 2021.12.10 to 2022.2.9.
Context/History
I had a HA installation that was getting very outdated (about one year without being updated), so I decided to gradually update it, either version-by-version or skipping one version at most. Things were going smoothly, but when I upgraded from 2021.12.10 to 2022.2.9 I started facing high CPU usage. I don’t know if it was caused by the update, or if it was caused by some new integration that I configured. And that’s the point: I don’t know, and I want to know.
I have already tried…
I tried looking at HA core logs (ha core logs, or through the /config/logs web interface). I couldn’t find anything that looked obviously wrong. I found, however, many warnings of “Setup of … is taking over 10 seconds.”, which makes sense, since there is a thread eating up precious CPU cycles.
I also found several mentions of “E0618 … fork_posix.cc:70] Fork support is only compatible with the epoll1 and poll polling strategies”, but I don’t know where that is coming from. (See also: this forum thread.)
I’ve managed to ssh into port 22222. I tried killing that specific thread, hoping that would cause the stack trace to be logged somewhere. Unfortunately, that just caused the whole HA core to shut down, and I found nothing on the logs. (Or I failed to look in the right place.)
I thought about using strace to observe the syscalls from that thread, but there is no strace binary on HAOS.
Final words…
Huh… Help!



